 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElixir: Train a Large Language Model on a Small GPU Cluster
Dec 10, 2022In recent years, the number of parameters of one deep learning (DL) model has been growing much faster than the growth of GPU memory space. People who are inaccessible to a large number of GPUs resort to heterogeneous training systems for storing model parameters in CPU memory. Existing heterogeneous systems are based on parallelization plans in the scope of the whole model. They apply a consistent parallel training method for all the operators in the computation. Therefore, engineers need to pay a huge effort to incorporate a new type of model parallelism and patch its compatibility with other parallelisms. For example, Mixture-of-Experts (MoE) is still incompatible with ZeRO-3 in Deepspeed. Also, current systems face efficiency problems on small scale, since they are designed and tuned for large-scale training. In this paper, we propose Elixir, a new parallel heterogeneous training system, which is designed for efficiency and flexibility. Elixir utilizes memory resources and computing resources of both GPU and CPU. For flexibility, Elixir generates parallelization plans in the granularity of operators. Any new type of model parallelism can be incorporated by assigning a parallel pattern to the operator. For efficiency, Elixir implements a hierarchical distributed memory management scheme to accelerate inter-GPU communications and CPU-GPU data transmissions. As a result, Elixir can train a 30B OPT model on an A100 with 40GB CUDA memory, meanwhile reaching 84% efficiency of Pytorch GPU training. With its super-linear scalability, the training efficiency becomes the same as Pytorch GPU training on multiple GPUs. Also, large MoE models can be trained 5.3x faster than dense models of the same size. Now Elixir is integrated into ColossalAI and is available on its main branch.
Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
Oct 28, 2021
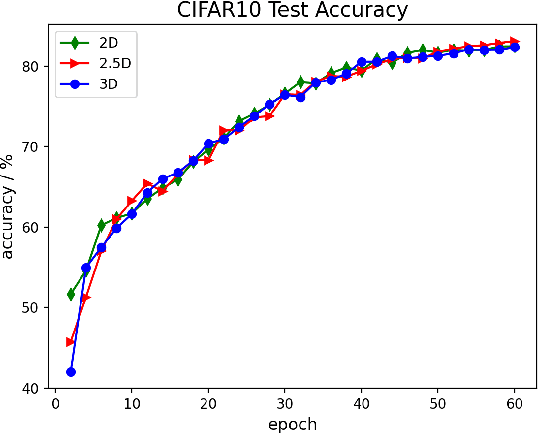
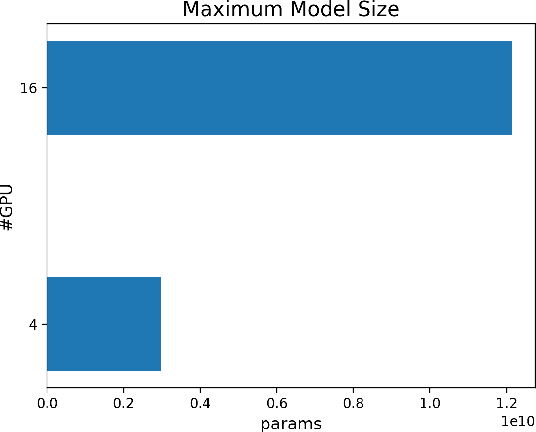
The Transformer architecture has improved the performance of deep learning models in domains such as Computer Vision and Natural Language Processing. Together with better performance come larger model sizes. This imposes challenges to the memory wall of the current accelerator hardware such as GPU. It is never ideal to train large models such as Vision Transformer, BERT, and GPT on a single GPU or a single machine. There is an urgent demand to train models in a distributed environment. However, distributed training, especially model parallelism, often requires domain expertise in computer systems and architecture. It remains a challenge for AI researchers to implement complex distributed training solutions for their models. In this paper, we introduce Colossal-AI, which is a unified parallel training system designed to seamlessly integrate different paradigms of parallelization techniques including data parallelism, pipeline parallelism, multiple tensor parallelism, and sequence parallelism. Colossal-AI aims to support the AI community to write distributed models in the same way as how they write models normally. This allows them to focus on developing the model architecture and separates the concerns of distributed training from the development process. The documentations can be found at https://www.colossalai.org and the source code can be found at https://github.com/hpcaitech/ColossalAI.