 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025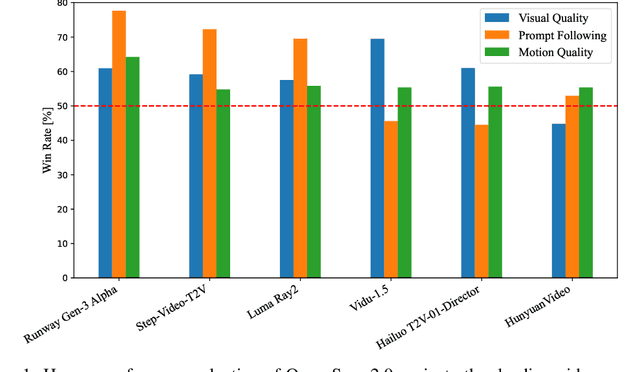

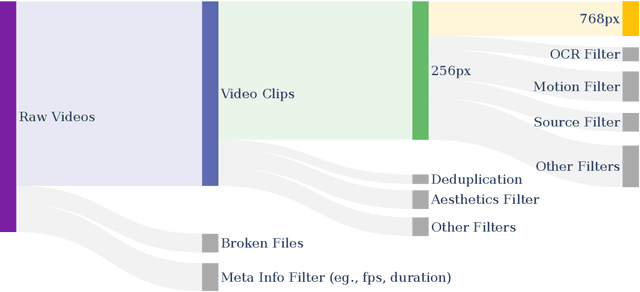

Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
Overcoming challenges of translating deep-learning models for glioblastoma: the ZGBM consortium
May 07, 2024Objective: To report imaging protocol and scheduling variance in routine care of glioblastoma patients in order to demonstrate challenges of integrating deep-learning models in glioblastoma care pathways. Additionally, to understand the most common imaging studies and image contrasts to inform the development of potentially robust deep-learning models. Methods: MR imaging data were analysed from a random sample of five patients from the prospective cohort across five participating sites of the ZGBM consortium. Reported clinical and treatment data alongside DICOM header information were analysed to understand treatment pathway imaging schedules. Results: All sites perform all structural imaging at every stage in the pathway except for the presurgical study, where in some sites only contrast-enhanced T1-weighted imaging is performed. Diffusion MRI is the most common non-structural imaging type, performed at every site. Conclusion: The imaging protocol and scheduling varies across the UK, making it challenging to develop machine-learning models that could perform robustly at other centres. Structural imaging is performed most consistently across all centres. Advances in knowledge: Successful translation of deep-learning models will likely be based on structural post-treatment imaging unless there is significant effort made to standardise non-structural or peri-operative imaging protocols and schedules.
On the Inconsistencies of Conditionals Learned by Masked Language Models
Dec 30, 2022Learning to predict masked tokens in a sequence has been shown to be a powerful pretraining objective for large-scale language models. After training, such masked language models can provide distributions of tokens conditioned on bidirectional context. In this short draft, we show that such bidirectional conditionals often demonstrate considerable inconsistencies, i.e., they can not be derived from a coherent joint distribution when considered together. We empirically quantify such inconsistencies in the simple scenario of bigrams for two common styles of masked language models: T5-style and BERT-style. For example, we show that T5 models often confuse its own preference regarding two similar bigrams. Such inconsistencies may represent a theoretical pitfall for the research work on sampling sequences based on the bidirectional conditionals learned by BERT-style MLMs. This phenomenon also means that T5-style MLMs capable of infilling will generate discrepant results depending on how much masking is given, which may represent a particular trust issue.
Fusing task-oriented and open-domain dialogues in conversational agents
Sep 09, 2021

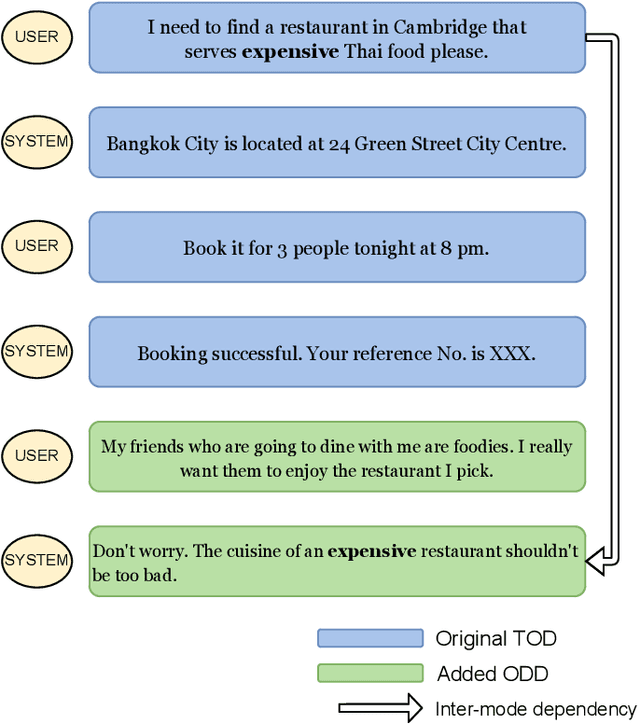
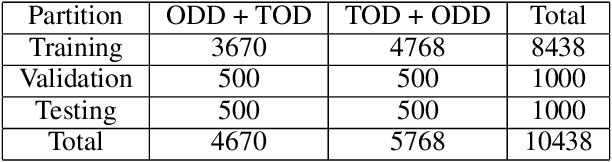
The goal of building intelligent dialogue systems has largely been \textit{separately} pursued under two paradigms: task-oriented dialogue (TOD) systems, which perform goal-oriented functions, and open-domain dialogue (ODD) systems, which focus on non-goal-oriented chitchat. The two dialogue modes can potentially be intertwined together seamlessly in the same conversation, as easily done by a friendly human assistant. Such ability is desirable in conversational agents, as the integration makes them more accessible and useful. Our paper addresses this problem of fusing TODs and ODDs in multi-turn dialogues. Based on the popular TOD dataset MultiWOZ, we build a new dataset FusedChat, by rewriting the existing TOD turns and adding new ODD turns. This procedure constructs conversation sessions containing exchanges from both dialogue modes. It features inter-mode contextual dependency, i.e., the dialogue turns from the two modes depend on each other. Rich dependency patterns including co-reference and ellipsis are features. The new dataset, with 60k new human-written ODD turns and 5k re-written TOD turns, offers a benchmark to test a dialogue model's ability to perform inter-mode conversations. This is a more challenging task since the model has to determine the appropriate dialogue mode and generate the response based on the inter-mode context. But such models would better mimic human-level conversation capabilities. We evaluate baseline models on this task, including \textit{classification-based} two-stage models and \textit{two-in-one} fused models. We publicly release FusedChat and the baselines to propel future work on inter-mode dialogue systems https://github.com/tomyoung903/FusedChat.
Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey
Jun 01, 2021


Dialogue systems are a popular Natural Language Processing (NLP) task as it is promising in real-life applications. It is also a complicated task since many NLP tasks deserving study are involved. As a result, a multitude of novel works on this task are carried out, and most of them are deep learning-based due to the outstanding performance. In this survey, we mainly focus on the deep learning-based dialogue systems. We comprehensively review state-of-the-art research outcomes in dialogue systems and analyze them from two angles: model type and system type. Specifically, from the angle of model type, we discuss the principles, characteristics, and applications of different models that are widely used in dialogue systems. This will help researchers acquaint these models and see how they are applied in state-of-the-art frameworks, which is rather helpful when designing a new dialogue system. From the angle of system type, we discuss task-oriented and open-domain dialogue systems as two streams of research, providing insight into the hot topics related. Furthermore, we comprehensively review the evaluation methods and datasets for dialogue systems to pave the way for future research. Finally, some possible research trends are identified based on the recent research outcomes. To the best of our knowledge, this survey is the most comprehensive and up-to-date one at present in the area of dialogue systems and dialogue-related tasks, extensively covering the popular frameworks, topics, and datasets. Keywords: Dialogue Systems, Chatbots, Conversational AI, Task-oriented, Open Domain, Chit-chat, Question Answering, Artificial Intelligence, Natural Language Processing, Information Retrieval, Deep Learning, Neural Networks, CNN, RNN, Hierarchical Recurrent Encoder-Decoder, Memory Networks, Attention, Transformer, Pointer Net, CopyNet, Reinforcement Learning, GANs, Knowledge Graph, Survey, Review
Recent Trends in Deep Learning Based Natural Language Processing
Oct 10, 2018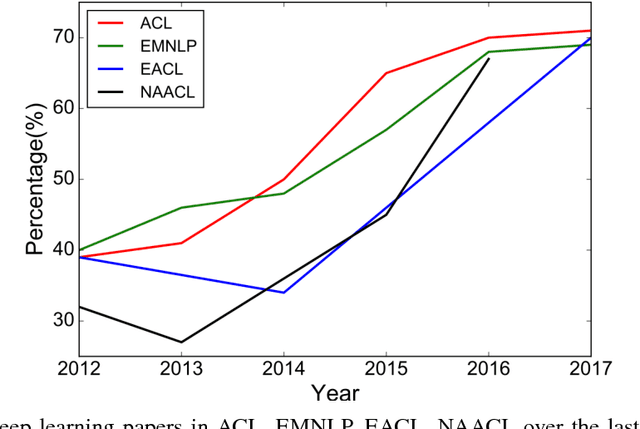
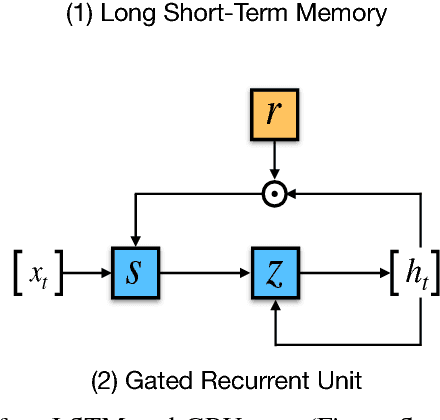
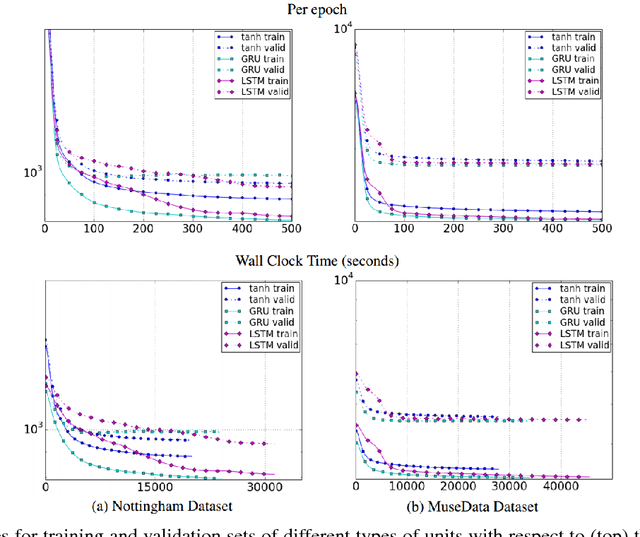
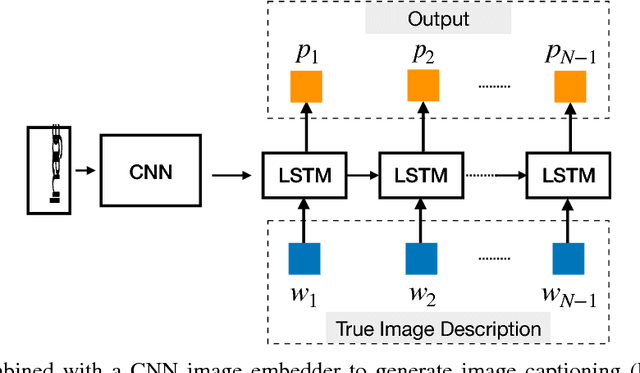
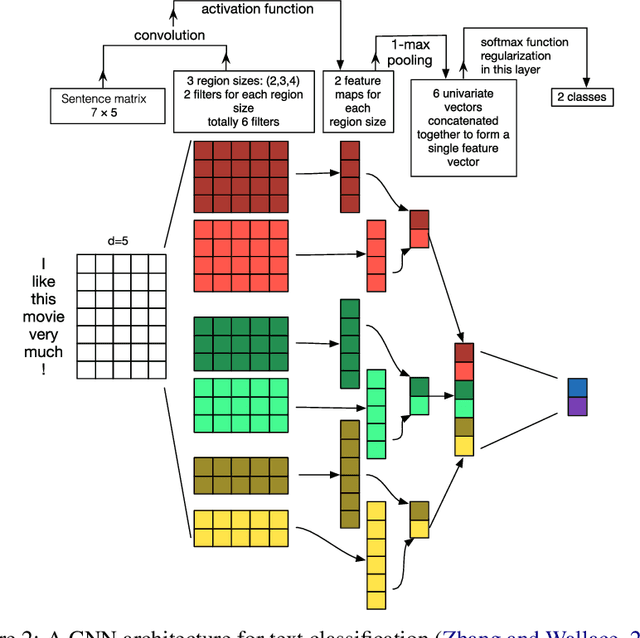
Deep learning methods employ multiple processing layers to learn hierarchical representations of data and have produced state-of-the-art results in many domains. Recently, a variety of model designs and methods have blossomed in the context of natural language processing (NLP). In this paper, we review significant deep learning related models and methods that have been employed for numerous NLP tasks and provide a walk-through of their evolution. We also summarize, compare and contrast the various models and put forward a detailed understanding of the past, present and future of deep learning in NLP.
Augmenting End-to-End Dialog Systems with Commonsense Knowledge
Feb 12, 2018

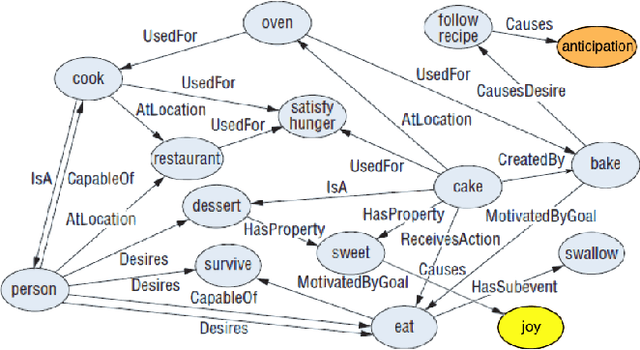
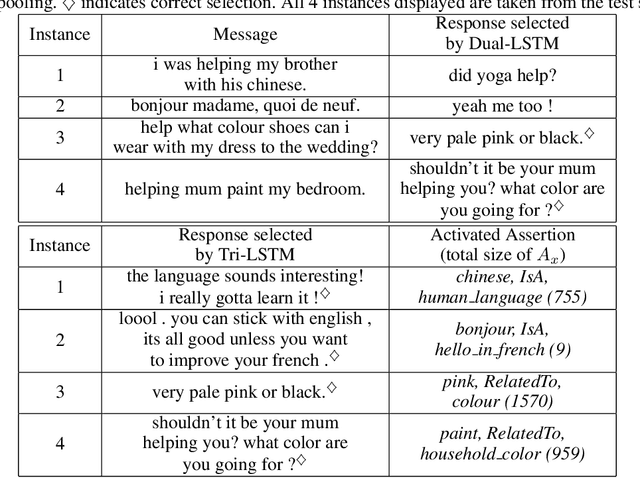
Building dialog agents that can converse naturally with humans is a challenging yet intriguing problem of artificial intelligence. In open-domain human-computer conversation, where the conversational agent is expected to respond to human responses in an interesting and engaging way, commonsense knowledge has to be integrated into the model effectively. In this paper, we investigate the impact of providing commonsense knowledge about the concepts covered in the dialog. Our model represents the first attempt to integrating a large commonsense knowledge base into end-to-end conversational models. In the retrieval-based scenario, we propose the Tri-LSTM model to jointly take into account message and commonsense for selecting an appropriate response. Our experiments suggest that the knowledge-augmented models are superior to their knowledge-free counterparts in automatic evaluation.