 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming challenges of translating deep-learning models for glioblastoma: the ZGBM consortium
May 07, 2024

Objective: To report imaging protocol and scheduling variance in routine care of glioblastoma patients in order to demonstrate challenges of integrating deep-learning models in glioblastoma care pathways. Additionally, to understand the most common imaging studies and image contrasts to inform the development of potentially robust deep-learning models. Methods: MR imaging data were analysed from a random sample of five patients from the prospective cohort across five participating sites of the ZGBM consortium. Reported clinical and treatment data alongside DICOM header information were analysed to understand treatment pathway imaging schedules. Results: All sites perform all structural imaging at every stage in the pathway except for the presurgical study, where in some sites only contrast-enhanced T1-weighted imaging is performed. Diffusion MRI is the most common non-structural imaging type, performed at every site. Conclusion: The imaging protocol and scheduling varies across the UK, making it challenging to develop machine-learning models that could perform robustly at other centres. Structural imaging is performed most consistently across all centres. Advances in knowledge: Successful translation of deep-learning models will likely be based on structural post-treatment imaging unless there is significant effort made to standardise non-structural or peri-operative imaging protocols and schedules.
Validating transformers for redaction of text from electronic health records in real-world healthcare
Oct 05, 2023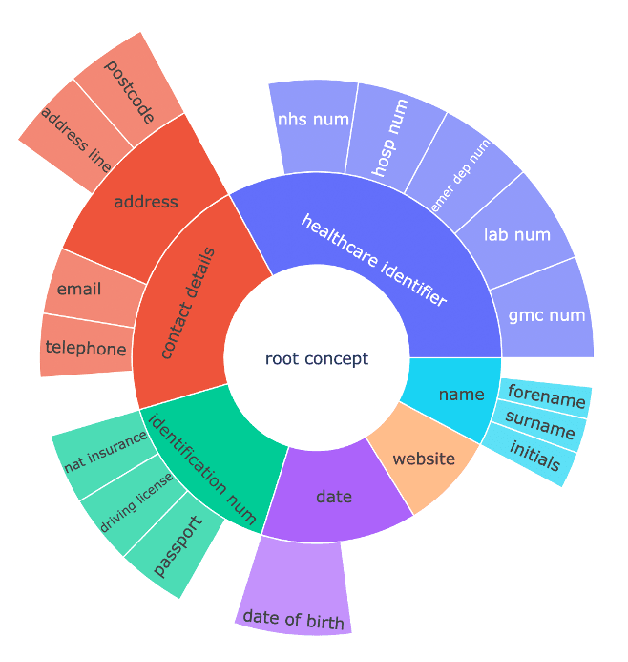
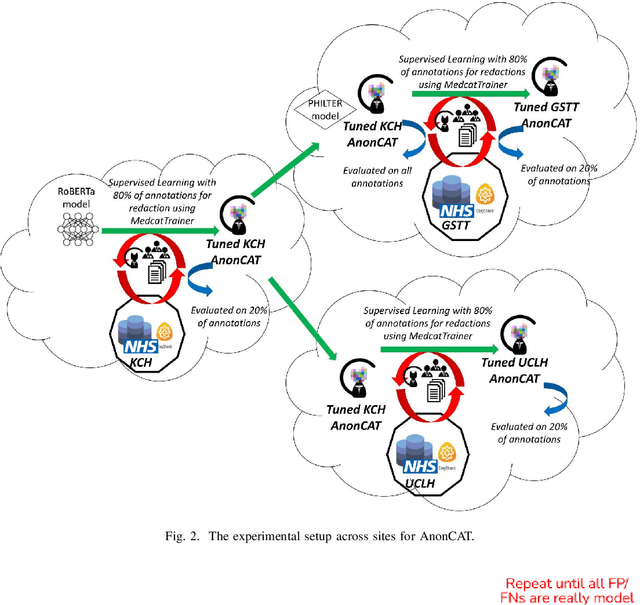
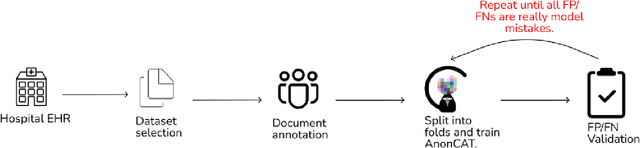
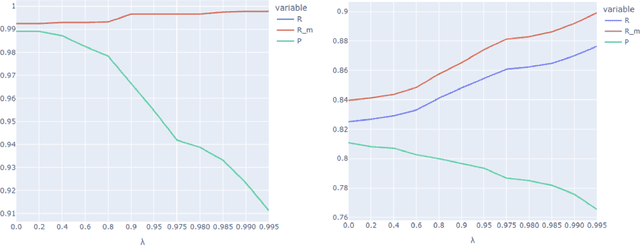
Protecting patient privacy in healthcare records is a top priority, and redaction is a commonly used method for obscuring directly identifiable information in text. Rule-based methods have been widely used, but their precision is often low causing over-redaction of text and frequently not being adaptable enough for non-standardised or unconventional structures of personal health information. Deep learning techniques have emerged as a promising solution, but implementing them in real-world environments poses challenges due to the differences in patient record structure and language across different departments, hospitals, and countries. In this study, we present AnonCAT, a transformer-based model and a blueprint on how deidentification models can be deployed in real-world healthcare. AnonCAT was trained through a process involving manually annotated redactions of real-world documents from three UK hospitals with different electronic health record systems and 3116 documents. The model achieved high performance in all three hospitals with a Recall of 0.99, 0.99 and 0.96. Our findings demonstrate the potential of deep learning techniques for improving the efficiency and accuracy of redaction in global healthcare data and highlight the importance of building workflows which not just use these models but are also able to continually fine-tune and audit the performance of these algorithms to ensure continuing effectiveness in real-world settings. This approach provides a blueprint for the real-world use of de-identifying algorithms through fine-tuning and localisation, the code together with tutorials is available on GitHub (https://github.com/CogStack/MedCAT).
Current State of Community-Driven Radiological AI Deployment in Medical Imaging
Dec 29, 2022



Artificial Intelligence (AI) has become commonplace to solve routine everyday tasks. Because of the exponential growth in medical imaging data volume and complexity, the workload on radiologists is steadily increasing. We project that the gap between the number of imaging exams and the number of expert radiologist readers required to cover this increase will continue to expand, consequently introducing a demand for AI-based tools that improve the efficiency with which radiologists can comfortably interpret these exams. AI has been shown to improve efficiency in medical-image generation, processing, and interpretation, and a variety of such AI models have been developed across research labs worldwide. However, very few of these, if any, find their way into routine clinical use, a discrepancy that reflects the divide between AI research and successful AI translation. To address the barrier to clinical deployment, we have formed MONAI Consortium, an open-source community which is building standards for AI deployment in healthcare institutions, and developing tools and infrastructure to facilitate their implementation. This report represents several years of weekly discussions and hands-on problem solving experience by groups of industry experts and clinicians in the MONAI Consortium. We identify barriers between AI-model development in research labs and subsequent clinical deployment and propose solutions. Our report provides guidance on processes which take an imaging AI model from development to clinical implementation in a healthcare institution. We discuss various AI integration points in a clinical Radiology workflow. We also present a taxonomy of Radiology AI use-cases. Through this report, we intend to educate the stakeholders in healthcare and AI (AI researchers, radiologists, imaging informaticists, and regulators) about cross-disciplinary challenges and possible solutions.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Machine Learning and Glioblastoma: Treatment Response Monitoring Biomarkers in 2021
Apr 15, 2021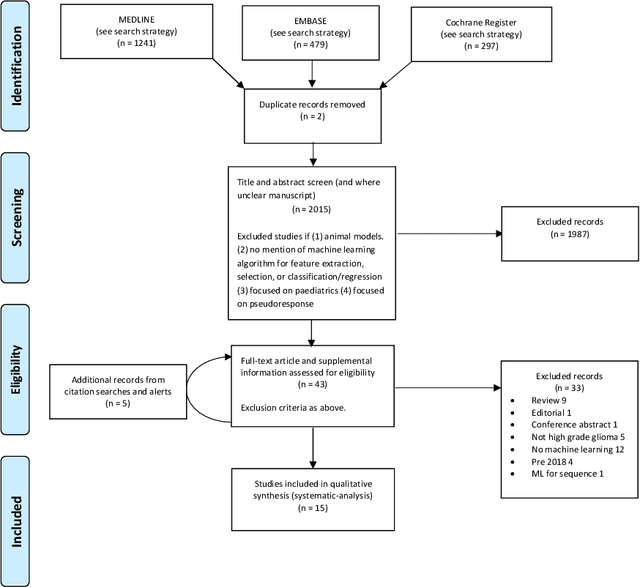
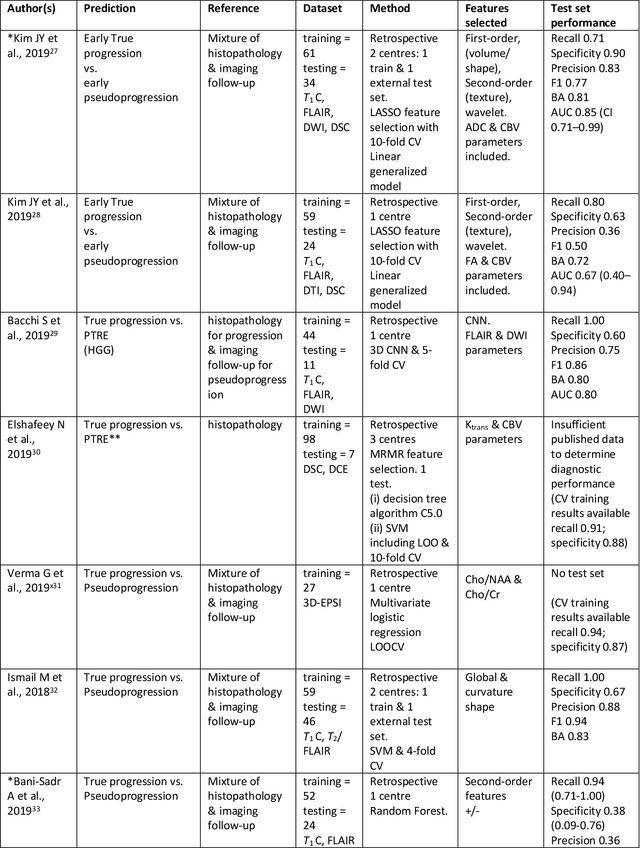
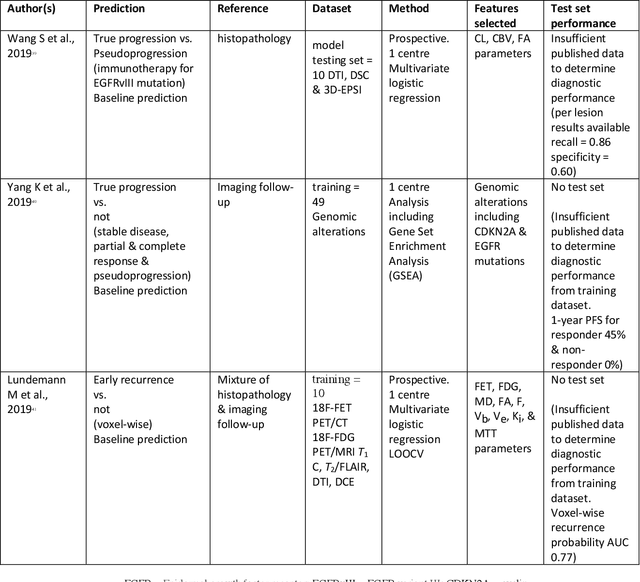
The aim of the systematic review was to assess recently published studies on diagnostic test accuracy of glioblastoma treatment response monitoring biomarkers in adults, developed through machine learning (ML). Articles were searched for using MEDLINE, EMBASE, and the Cochrane Register. Included study participants were adult patients with high grade glioma who had undergone standard treatment (maximal resection, radiotherapy with concomitant and adjuvant temozolomide) and subsequently underwent follow-up imaging to determine treatment response status. Risk of bias and applicability was assessed with QUADAS 2 methodology. Contingency tables were created for hold-out test sets and recall, specificity, precision, F1-score, balanced accuracy calculated. Fifteen studies were included with 1038 patients in training sets and 233 in test sets. To determine whether there was progression or a mimic, the reference standard combination of follow-up imaging and histopathology at re-operation was applied in 67% of studies. The small numbers of patient included in studies, the high risk of bias and concerns of applicability in the study designs (particularly in relation to the reference standard and patient selection due to confounding), and the low level of evidence, suggest that limited conclusions can be drawn from the data. There is likely good diagnostic performance of machine learning models that use MRI features to distinguish between progression and mimics. The diagnostic performance of ML using implicit features did not appear to be superior to ML using explicit features. There are a range of ML-based solutions poised to become treatment response monitoring biomarkers for glioblastoma. To achieve this, the development and validation of ML models require large, well-annotated datasets where the potential for confounding in the study design has been carefully considered.