 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESGSenticNet: A Neurosymbolic Knowledge Base for Corporate Sustainability Analysis
Jan 27, 2025


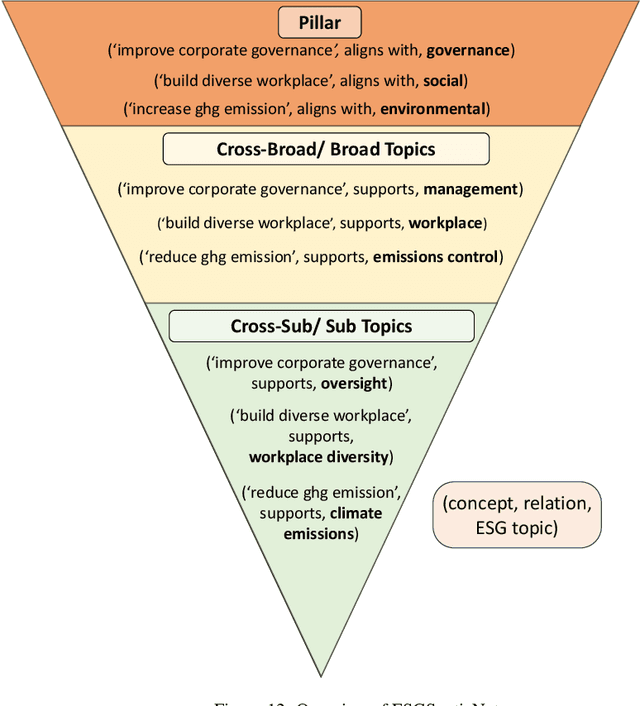
Evaluating corporate sustainability performance is essential to drive sustainable business practices, amid the need for a more sustainable economy. However, this is hindered by the complexity and volume of corporate sustainability data (i.e. sustainability disclosures), not least by the effectiveness of the NLP tools used to analyse them. To this end, we identify three primary challenges - immateriality, complexity, and subjectivity, that exacerbate the difficulty of extracting insights from sustainability disclosures. To address these issues, we introduce ESGSenticNet, a publicly available knowledge base for sustainability analysis. ESGSenticNet is constructed from a neurosymbolic framework that integrates specialised concept parsing, GPT-4o inference, and semi-supervised label propagation, together with a hierarchical taxonomy. This approach culminates in a structured knowledge base of 44k knowledge triplets - ('halve carbon emission', supports, 'emissions control'), for effective sustainability analysis. Experiments indicate that ESGSenticNet, when deployed as a lexical method, more effectively captures relevant and actionable sustainability information from sustainability disclosures compared to state of the art baselines. Besides capturing a high number of unique ESG topic terms, ESGSenticNet outperforms baselines on the ESG relatedness and ESG action orientation of these terms by 26% and 31% respectively. These metrics describe the extent to which topic terms are related to ESG, and depict an action toward ESG. Moreover, when deployed as a lexical method, ESGSenticNet does not require any training, possessing a key advantage in its simplicity for non-technical stakeholders.
Primary and Secondary Factor Consistency as Domain Knowledge to Guide Happiness Computing in Online Assessment
Feb 17, 2024



Happiness computing based on large-scale online web data and machine learning methods is an emerging research topic that underpins a range of issues, from personal growth to social stability. Many advanced Machine Learning (ML) models with explanations are used to compute the happiness online assessment while maintaining high accuracy of results. However, domain knowledge constraints, such as the primary and secondary relations of happiness factors, are absent from these models, which limits the association between computing results and the right reasons for why they occurred. This article attempts to provide new insights into the explanation consistency from an empirical study perspective. Then we study how to represent and introduce domain knowledge constraints to make ML models more trustworthy. We achieve this through: (1) proving that multiple prediction models with additive factor attributions will have the desirable property of primary and secondary relations consistency, and (2) showing that factor relations with quantity can be represented as an importance distribution for encoding domain knowledge. Factor explanation difference is penalized by the Kullback-Leibler divergence-based loss among computing models. Experimental results using two online web datasets show that domain knowledge of stable factor relations exists. Using this knowledge not only improves happiness computing accuracy but also reveals more significative happiness factors for assisting decisions well.
Designing Heterogeneous LLM Agents for Financial Sentiment Analysis
Jan 11, 2024Large language models (LLMs) have drastically changed the possible ways to design intelligent systems, shifting the focuses from massive data acquisition and new modeling training to human alignment and strategical elicitation of the full potential of existing pre-trained models. This paradigm shift, however, is not fully realized in financial sentiment analysis (FSA), due to the discriminative nature of this task and a lack of prescriptive knowledge of how to leverage generative models in such a context. This study investigates the effectiveness of the new paradigm, i.e., using LLMs without fine-tuning for FSA. Rooted in Minsky's theory of mind and emotions, a design framework with heterogeneous LLM agents is proposed. The framework instantiates specialized agents using prior domain knowledge of the types of FSA errors and reasons on the aggregated agent discussions. Comprehensive evaluation on FSA datasets show that the framework yields better accuracies, especially when the discussions are substantial. This study contributes to the design foundations and paves new avenues for LLMs-based FSA. Implications on business and management are also discussed.
Fusing task-oriented and open-domain dialogues in conversational agents
Sep 09, 2021

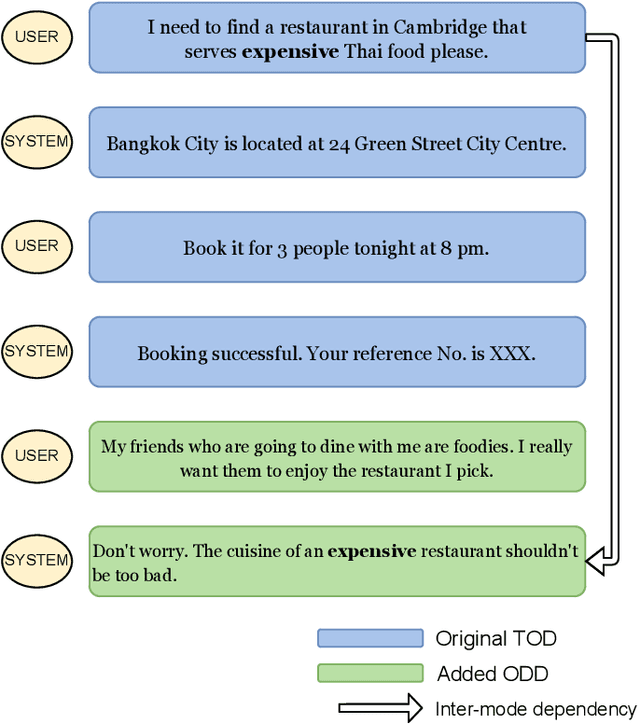
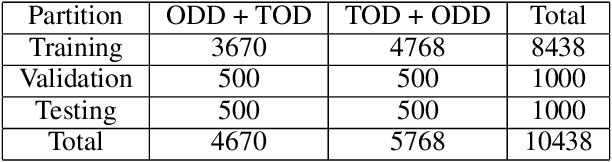
The goal of building intelligent dialogue systems has largely been \textit{separately} pursued under two paradigms: task-oriented dialogue (TOD) systems, which perform goal-oriented functions, and open-domain dialogue (ODD) systems, which focus on non-goal-oriented chitchat. The two dialogue modes can potentially be intertwined together seamlessly in the same conversation, as easily done by a friendly human assistant. Such ability is desirable in conversational agents, as the integration makes them more accessible and useful. Our paper addresses this problem of fusing TODs and ODDs in multi-turn dialogues. Based on the popular TOD dataset MultiWOZ, we build a new dataset FusedChat, by rewriting the existing TOD turns and adding new ODD turns. This procedure constructs conversation sessions containing exchanges from both dialogue modes. It features inter-mode contextual dependency, i.e., the dialogue turns from the two modes depend on each other. Rich dependency patterns including co-reference and ellipsis are features. The new dataset, with 60k new human-written ODD turns and 5k re-written TOD turns, offers a benchmark to test a dialogue model's ability to perform inter-mode conversations. This is a more challenging task since the model has to determine the appropriate dialogue mode and generate the response based on the inter-mode context. But such models would better mimic human-level conversation capabilities. We evaluate baseline models on this task, including \textit{classification-based} two-stage models and \textit{two-in-one} fused models. We publicly release FusedChat and the baselines to propel future work on inter-mode dialogue systems https://github.com/tomyoung903/FusedChat.