 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Compression Preserve Uncertainty? A Unified Benchmark for Quantized and Sparse LLMs via Conformal Prediction
Jun 01, 2026Model compression techniques such as quantization and pruning are widely used to reduce the deployment cost of large language models (LLMs), with existing evaluations focusing almost exclusively on accuracy preservation. However, in safety-critical applications, a model's ability to reliably quantify its own uncertainty is equally important. We ask: does compression preserve this ability? To answer this question, we benchmark 12 LLMs under various compression configurations across five NLP tasks, using conformal prediction to provide a rigorous, distribution-free measure of uncertainty. Our experiments reveal that: (I) compression frequently decouples accuracy from uncertainty; (II) larger models absorb compression-induced uncertainty far more effectively than smaller ones; and (III) uncertainty inflation is often threshold-like rather than gradual. These results suggest that accuracy-only evaluation is insufficient for assessing the deployment readiness of compressed LLMs, and that uncertainty-aware benchmarking should be a standard component of model compression pipelines.
Hyena Operator for Fast Sequential Recommendation
Mar 26, 2026Sequential recommendation models, particularly those based on attention, achieve strong accuracy but incur quadratic complexity, making long user histories prohibitively expensive. Sub-quadratic operators such as Hyena provide efficient alternatives in language modeling, but their potential in recommendation remains underexplored. We argue that Hyena faces challenges in recommendation due to limited representation capacity on sparse, long user sequences. To address these challenges, we propose HyenaRec, a novel sequential recommender that integrates polynomial-based kernel parameterization with gated convolutions. Specifically, we design convolutional kernels using Legendre orthogonal polynomials, which provides a smooth and compact basis for modeling long-term temporal dependencies. A complementary gating mechanism captures fine-grained short-term behavioral bursts, yielding a hybrid architecture that balances global temporal evolution with localized user interests under sparse feedback. This construction enhances expressiveness while scaling linearly with sequence length. Extensive experiments on multiple real-world datasets demonstrate that HyenaRec consistently outperforms Attention-, Recurrent-, and other baselines in ranking accuracy. Moreover, it trains significantly faster (up to 6x speedup), with particularly pronounced advantages on long-sequence scenarios where efficiency is maintained without sacrificing accuracy. These results highlight polynomial-based kernel parameterization as a principled and scalable alternative to attention for sequential recommendation.
Visual Attention Drifts,but Anchors Hold:Mitigating Hallucination in Multimodal Large Language Models via Cross-Layer Visual Anchors
Mar 26, 2026Multimodal Large Language Models often suffer from object hallucination. While existing research utilizes attention enhancement and visual retracing, we find these works lack sufficient interpretability regarding attention drift in final model stages. In this paper, we investigate the layer wise evolution of visual features and discover that hallucination stems from deep layer attention regressing toward initial visual noise from early layers. We observe that output reliability depends on acquiring visual anchors at intermediate layers rather than final layers. Based on these insights, we propose CLVA, which stands for Cross-Layer Visual Anchors, a training free method that reinforces critical mid layer features while suppressing regressive noise. This approach effectively pulls deep layer attention back to correct visual regions by utilizing essential anchors captured from attention dynamics. We evaluate our method across diverse architectures and benchmarks, demonstrating outstanding performance without significant increase in computational time and GPU memory.
Forget by Uncertainty: Orthogonal Entropy Unlearning for Quantized Neural Networks
Jan 31, 2026The deployment of quantized neural networks on edge devices, combined with privacy regulations like GDPR, creates an urgent need for machine unlearning in quantized models. However, existing methods face critical challenges: they induce forgetting by training models to memorize incorrect labels, conflating forgetting with misremembering, and employ scalar gradient reweighting that cannot resolve directional conflicts between gradients. We propose OEU, a novel Orthogonal Entropy Unlearning framework with two key innovations: 1) Entropy-guided unlearning maximizes prediction uncertainty on forgotten data, achieving genuine forgetting rather than confident misprediction, and 2) Gradient orthogonal projection eliminates interference by projecting forgetting gradients onto the orthogonal complement of retain gradients, providing theoretical guarantees for utility preservation under first-order approximation. Extensive experiments demonstrate that OEU outperforms existing methods in both forgetting effectiveness and retain accuracy.
SAGE: Accelerating Vision-Language Models via Entropy-Guided Adaptive Speculative Decoding
Jan 31, 2026Speculative decoding has emerged as a promising approach to accelerate inference in vision-language models (VLMs) by enabling parallel verification of multiple draft tokens. However, existing methods rely on static tree structures that remain fixed throughout the decoding process, failing to adapt to the varying prediction difficulty across generation steps. This leads to suboptimal acceptance lengths and limited speedup. In this paper, we propose SAGE, a novel framework that dynamically adjusts the speculation tree structure based on real-time prediction uncertainty. Our key insight is that output entropy serves as a natural confidence indicator with strong temporal correlation across decoding steps. SAGE constructs deeper-narrower trees for high-confidence predictions to maximize speculation depth, and shallower-wider trees for uncertain predictions to diversify exploration. SAGE improves acceptance lengths and achieves faster acceleration compared to static tree baselines. Experiments on multiple benchmarks demonstrate the effectiveness of SAGE: without any loss in output quality, it delivers up to $3.36\times$ decoding speedup for LLaVA-OneVision-72B and $3.18\times$ for Qwen2.5-VL-72B.
Sparsity-Aware Unlearning for Large Language Models
Jan 31, 2026Large Language Models (LLMs) inevitably memorize sensitive information during training, posing significant privacy risks. Machine unlearning has emerged as a promising solution to selectively remove such information without full retraining. However, existing methods are designed for dense models and overlook model sparsification-an essential technique for efficient LLM deployment. We find that unlearning effectiveness degrades substantially on sparse models. Through empirical analysis, we reveal that this degradation occurs because existing unlearning methods require updating all parameters, yet sparsification prunes substantial weights to zero, fundamentally limiting the model's forgetting capacity. To address this challenge, we propose Sparsity-Aware Unlearning (SAU), which decouples unlearning from sparsification objectives through gradient masking that redirects updates to surviving weights, combined with importance-aware redistribution to compensate for pruned parameters. Extensive experiments demonstrate that SAU significantly outperforms existing methods on sparse LLMs, achieving effective forgetting while preserving model utility.
Heaven-Sent or Hell-Bent? Benchmarking the Intelligence and Defectiveness of LLM Hallucinations
Dec 25, 2025

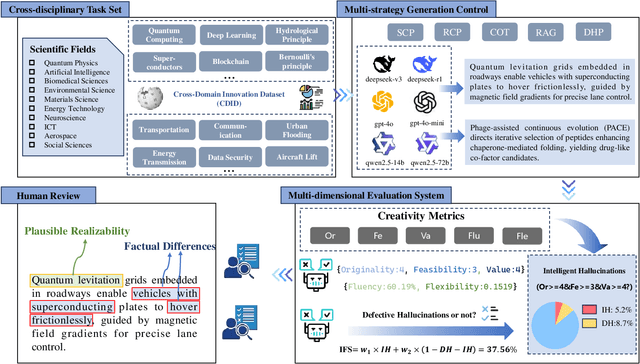

Hallucinations in large language models (LLMs) are commonly regarded as errors to be minimized. However, recent perspectives suggest that some hallucinations may encode creative or epistemically valuable content, a dimension that remains underquantified in current literature. Existing hallucination detection methods primarily focus on factual consistency, struggling to handle heterogeneous scientific tasks and balance creativity with accuracy. To address these challenges, we propose HIC-Bench, a novel evaluation framework that categorizes hallucinations into Intelligent Hallucinations (IH) and Defective Hallucinations (DH), enabling systematic investigation of their interplay in LLM creativity. HIC-Bench features three core characteristics: (1) Structured IH/DH Assessment. using a multi-dimensional metric matrix integrating Torrance Tests of Creative Thinking (TTCT) metrics (Originality, Feasibility, Value) with hallucination-specific dimensions (scientific plausibility, factual deviation); (2) Cross-Domain Applicability. spanning ten scientific domains with open-ended innovation tasks; and (3) Dynamic Prompt Optimization. leveraging the Dynamic Hallucination Prompt (DHP) to guide models toward creative and reliable outputs. The evaluation process employs multiple LLM judges, averaging scores to mitigate bias, with human annotators verifying IH/DH classifications. Experimental results reveal a nonlinear relationship between IH and DH, demonstrating that creativity and correctness can be jointly optimized. These insights position IH as a catalyst for creativity and reveal the ability of LLM hallucinations to drive scientific innovation.Additionally, the HIC-Bench offers a valuable platform for advancing research into the creative intelligence of LLM hallucinations.
Certified Signed Graph Unlearning
Nov 18, 2025Signed graphs model complex relationships through positive and negative edges, with widespread real-world applications. Given the sensitive nature of such data, selective removal mechanisms have become essential for privacy protection. While graph unlearning enables the removal of specific data influences from Graph Neural Networks (GNNs), existing methods are designed for conventional GNNs and overlook the unique heterogeneous properties of signed graphs. When applied to Signed Graph Neural Networks (SGNNs), these methods lose critical sign information, degrading both model utility and unlearning effectiveness. To address these challenges, we propose Certified Signed Graph Unlearning (CSGU), which provides provable privacy guarantees while preserving the sociological principles underlying SGNNs. CSGU employs a three-stage method: (1) efficiently identifying minimal influenced neighborhoods via triangular structures, (2) applying sociological theories to quantify node importance for optimal privacy budget allocation, and (3) performing importance-weighted parameter updates to achieve certified modifications with minimal utility degradation. Extensive experiments demonstrate that CSGU outperforms existing methods, achieving superior performance in both utility preservation and unlearning effectiveness on SGNNs.
Expanding Zero-Shot Object Counting with Rich Prompts
May 21, 2025Expanding pre-trained zero-shot counting models to handle unseen categories requires more than simply adding new prompts, as this approach does not achieve the necessary alignment between text and visual features for accurate counting. We introduce RichCount, the first framework to address these limitations, employing a two-stage training strategy that enhances text encoding and strengthens the model's association with objects in images. RichCount improves zero-shot counting for unseen categories through two key objectives: (1) enriching text features with a feed-forward network and adapter trained on text-image similarity, thereby creating robust, aligned representations; and (2) applying this refined encoder to counting tasks, enabling effective generalization across diverse prompts and complex images. In this manner, RichCount goes beyond simple prompt expansion to establish meaningful feature alignment that supports accurate counting across novel categories. Extensive experiments on three benchmark datasets demonstrate the effectiveness of RichCount, achieving state-of-the-art performance in zero-shot counting and significantly enhancing generalization to unseen categories in open-world scenarios.
Robust Machine Unlearning for Quantized Neural Networks via Adaptive Gradient Reweighting with Similar Labels
Mar 18, 2025Model quantization enables efficient deployment of deep neural networks on edge devices through low-bit parameter representation, yet raises critical challenges for implementing machine unlearning (MU) under data privacy regulations. Existing MU methods designed for full-precision models fail to address two fundamental limitations in quantized networks: 1) Noise amplification from label mismatch during data processing, and 2) Gradient imbalance between forgotten and retained data during training. These issues are exacerbated by quantized models' constrained parameter space and discrete optimization. We propose Q-MUL, the first dedicated unlearning framework for quantized models. Our method introduces two key innovations: 1) Similar Labels assignment replaces random labels with semantically consistent alternatives to minimize noise injection, and 2) Adaptive Gradient Reweighting dynamically aligns parameter update contributions from forgotten and retained data. Through systematic analysis of quantized model vulnerabilities, we establish theoretical foundations for these mechanisms. Extensive evaluations on benchmark datasets demonstrate Q-MUL's superiority over existing approaches.