 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Zero-Shot Object Counting with Rich Prompts
May 21, 2025Expanding pre-trained zero-shot counting models to handle unseen categories requires more than simply adding new prompts, as this approach does not achieve the necessary alignment between text and visual features for accurate counting. We introduce RichCount, the first framework to address these limitations, employing a two-stage training strategy that enhances text encoding and strengthens the model's association with objects in images. RichCount improves zero-shot counting for unseen categories through two key objectives: (1) enriching text features with a feed-forward network and adapter trained on text-image similarity, thereby creating robust, aligned representations; and (2) applying this refined encoder to counting tasks, enabling effective generalization across diverse prompts and complex images. In this manner, RichCount goes beyond simple prompt expansion to establish meaningful feature alignment that supports accurate counting across novel categories. Extensive experiments on three benchmark datasets demonstrate the effectiveness of RichCount, achieving state-of-the-art performance in zero-shot counting and significantly enhancing generalization to unseen categories in open-world scenarios.
VEGAS: Towards Visually Explainable and Grounded Artificial Social Intelligence
Apr 03, 2025Social Intelligence Queries (Social-IQ) serve as the primary multimodal benchmark for evaluating a model's social intelligence level. While impressive multiple-choice question(MCQ) accuracy is achieved by current solutions, increasing evidence shows that they are largely, and in some cases entirely, dependent on language modality, overlooking visual context. Additionally, the closed-set nature further prevents the exploration of whether and to what extent the reasoning path behind selection is correct. To address these limitations, we propose the Visually Explainable and Grounded Artificial Social Intelligence (VEGAS) model. As a generative multimodal model, VEGAS leverages open-ended answering to provide explainable responses, which enhances the clarity and evaluation of reasoning paths. To enable visually grounded answering, we propose a novel sampling strategy to provide the model with more relevant visual frames. We then enhance the model's interpretation of these frames through Generalist Instruction Fine-Tuning (GIFT), which aims to: i) learn multimodal-language transformations for fundamental emotional social traits, and ii) establish multimodal joint reasoning capabilities. Extensive experiments, comprising modality ablation, open-ended assessments, and supervised MCQ evaluations, consistently show that VEGAS effectively utilizes visual information in reasoning to produce correct and also credible answers. We expect this work to of fer a new perspective on Social-IQ and advance the development of human-like social AI.
Knowledge-guided machine learning model with soil moisture for corn yield prediction under drought conditions
Mar 20, 2025Remote sensing (RS) techniques, by enabling non-contact acquisition of extensive ground observations, have become a valuable tool for corn yield prediction. Traditional process-based (PB) models are limited by fixed input features and struggle to incorporate large volumes of RS data. In contrast, machine learning (ML) models are often criticized for being ``black boxes'' with limited interpretability. To address these limitations, we used Knowledge-Guided Machine Learning (KGML), which combined the strengths of both approaches and fully used RS data. However, previous KGML methods overlooked the crucial role of soil moisture in plant growth. To bridge this gap, we proposed the Knowledge-Guided Machine Learning with Soil Moisture (KGML-SM) framework, using soil moisture as an intermediate variable to emphasize its key role in plant development. Additionally, based on the prior knowledge that the model may overestimate under drought conditions, we designed a drought-aware loss function that penalizes predicted yield in drought-affected areas. Our experiments showed that the KGML-SM model outperformed other ML models. Finally, we explored the relationships between drought, soil moisture, and corn yield prediction, assessing the importance of various features and analyzing how soil moisture impacts corn yield predictions across different regions and time periods.
Cross-Modal Few-Shot Learning: a Generative Transfer Learning Framework
Oct 14, 2024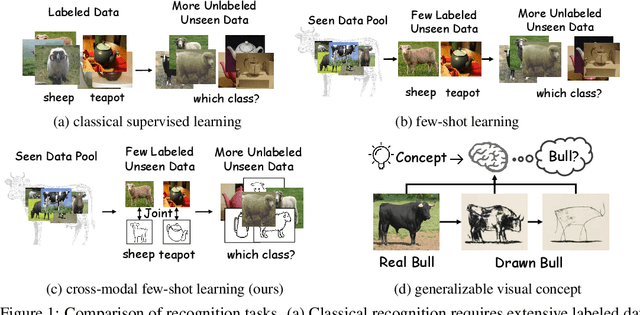
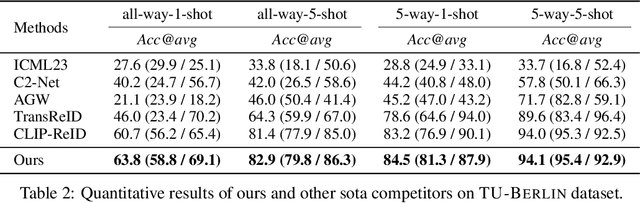
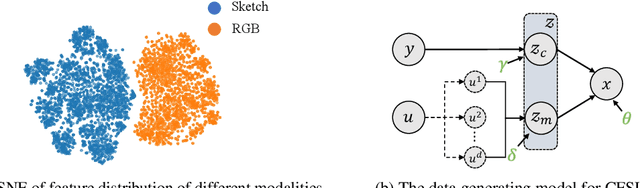
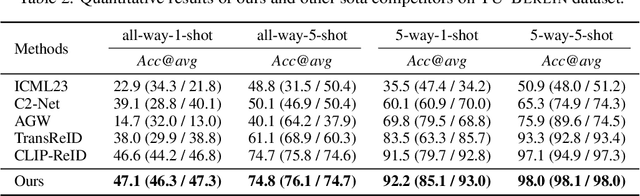
Most existing studies on few-shot learning focus on unimodal settings, where models are trained to generalize on unseen data using only a small number of labeled examples from the same modality. However, real-world data are inherently multi-modal, and unimodal approaches limit the practical applications of few-shot learning. To address this gap, this paper introduces the Cross-modal Few-Shot Learning (CFSL) task, which aims to recognize instances from multiple modalities when only a few labeled examples are available. This task presents additional challenges compared to classical few-shot learning due to the distinct visual characteristics and structural properties unique to each modality. To tackle these challenges, we propose a Generative Transfer Learning (GTL) framework consisting of two stages: the first stage involves training on abundant unimodal data, and the second stage focuses on transfer learning to adapt to novel data. Our GTL framework jointly estimates the latent shared concept across modalities and in-modality disturbance in both stages, while freezing the generative module during the transfer phase to maintain the stability of the learned representations and prevent overfitting to the limited multi-modal samples. Our finds demonstrate that GTL has superior performance compared to state-of-the-art methods across four distinct multi-modal datasets: Sketchy, TU-Berlin, Mask1K, and SKSF-A. Additionally, the results suggest that the model can estimate latent concepts from vast unimodal data and generalize these concepts to unseen modalities using only a limited number of available samples, much like human cognitive processes.
Zero-shot Object Counting with Good Exemplars
Jul 09, 2024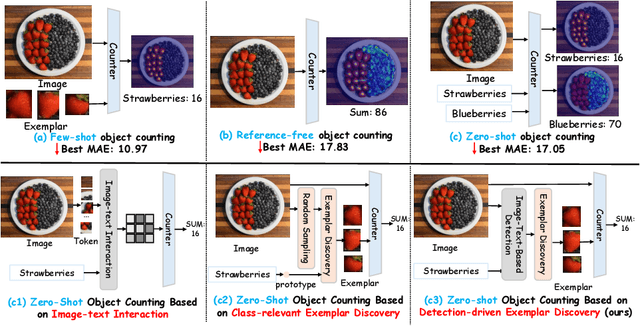


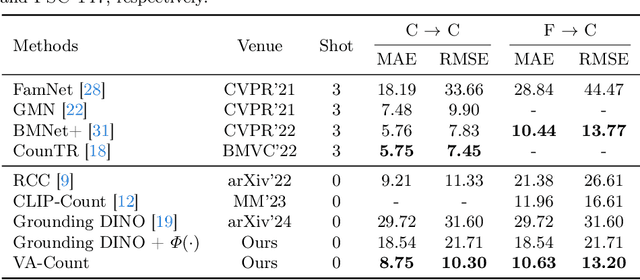
Zero-shot object counting (ZOC) aims to enumerate objects in images using only the names of object classes during testing, without the need for manual annotations. However, a critical challenge in current ZOC methods lies in their inability to identify high-quality exemplars effectively. This deficiency hampers scalability across diverse classes and undermines the development of strong visual associations between the identified classes and image content. To this end, we propose the Visual Association-based Zero-shot Object Counting (VA-Count) framework. VA-Count consists of an Exemplar Enhancement Module (EEM) and a Noise Suppression Module (NSM) that synergistically refine the process of class exemplar identification while minimizing the consequences of incorrect object identification. The EEM utilizes advanced vision-language pretaining models to discover potential exemplars, ensuring the framework's adaptability to various classes. Meanwhile, the NSM employs contrastive learning to differentiate between optimal and suboptimal exemplar pairs, reducing the negative effects of erroneous exemplars. VA-Count demonstrates its effectiveness and scalability in zero-shot contexts with superior performance on two object counting datasets.
Learning county from pixels: Corn yield prediction with attention-weighted multiple instance learning
Dec 02, 2023Remote sensing technology has become a promising tool in yield prediction. Most prior work employs satellite imagery for county-level corn yield prediction by spatially aggregating all pixels within a county into a single value, potentially overlooking the detailed information and valuable insights offered by more granular data. To this end, this research examines each county at the pixel level and applies multiple instance learning to leverage detailed information within a county. In addition, our method addresses the "mixed pixel" issue caused by the inconsistent resolution between feature datasets and crop mask, which may introduce noise into the model and therefore hinder accurate yield prediction. Specifically, the attention mechanism is employed to automatically assign weights to different pixels, which can mitigate the influence of mixed pixels. The experimental results show that the developed model outperforms four other machine learning models over the past five years in the U.S. corn belt and demonstrates its best performance in 2022, achieving a coefficient of determination (R2) value of 0.84 and a root mean square error (RMSE) of 0.83. This paper demonstrates the advantages of our approach from both spatial and temporal perspectives. Furthermore, through an in-depth study of the relationship between mixed pixels and attention, it is verified that our approach can capture critical feature information while filtering out noise from mixed pixels.
DAOT: Domain-Agnostically Aligned Optimal Transport for Domain-Adaptive Crowd Counting
Aug 10, 2023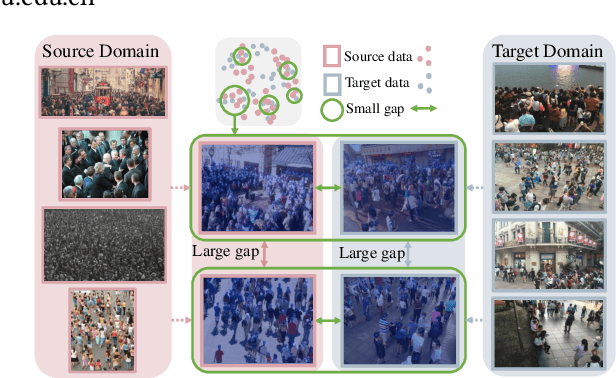



Domain adaptation is commonly employed in crowd counting to bridge the domain gaps between different datasets. However, existing domain adaptation methods tend to focus on inter-dataset differences while overlooking the intra-differences within the same dataset, leading to additional learning ambiguities. These domain-agnostic factors, e.g., density, surveillance perspective, and scale, can cause significant in-domain variations, and the misalignment of these factors across domains can lead to a drop in performance in cross-domain crowd counting. To address this issue, we propose a Domain-agnostically Aligned Optimal Transport (DAOT) strategy that aligns domain-agnostic factors between domains. The DAOT consists of three steps. First, individual-level differences in domain-agnostic factors are measured using structural similarity (SSIM). Second, the optimal transfer (OT) strategy is employed to smooth out these differences and find the optimal domain-to-domain misalignment, with outlier individuals removed via a virtual "dustbin" column. Third, knowledge is transferred based on the aligned domain-agnostic factors, and the model is retrained for domain adaptation to bridge the gap across domains. We conduct extensive experiments on five standard crowd-counting benchmarks and demonstrate that the proposed method has strong generalizability across diverse datasets. Our code will be available at: https://github.com/HopooLinZ/DAOT/.