 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Few-Shot Learning: a Generative Transfer Learning Framework
Paper and Code
Oct 14, 2024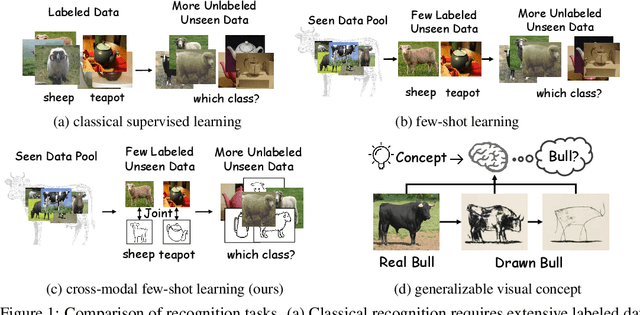
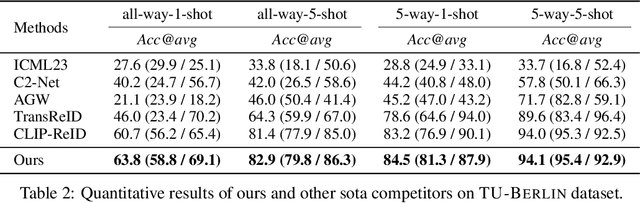
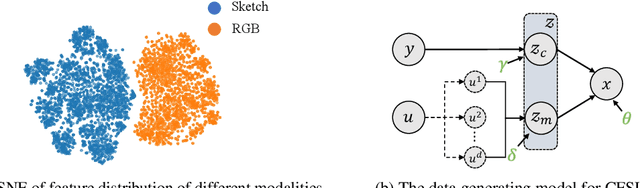
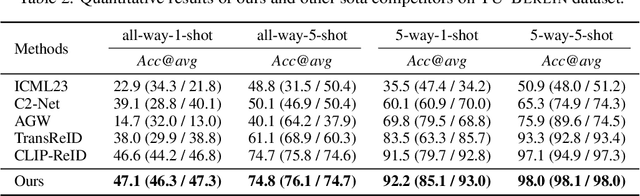
Most existing studies on few-shot learning focus on unimodal settings, where models are trained to generalize on unseen data using only a small number of labeled examples from the same modality. However, real-world data are inherently multi-modal, and unimodal approaches limit the practical applications of few-shot learning. To address this gap, this paper introduces the Cross-modal Few-Shot Learning (CFSL) task, which aims to recognize instances from multiple modalities when only a few labeled examples are available. This task presents additional challenges compared to classical few-shot learning due to the distinct visual characteristics and structural properties unique to each modality. To tackle these challenges, we propose a Generative Transfer Learning (GTL) framework consisting of two stages: the first stage involves training on abundant unimodal data, and the second stage focuses on transfer learning to adapt to novel data. Our GTL framework jointly estimates the latent shared concept across modalities and in-modality disturbance in both stages, while freezing the generative module during the transfer phase to maintain the stability of the learned representations and prevent overfitting to the limited multi-modal samples. Our finds demonstrate that GTL has superior performance compared to state-of-the-art methods across four distinct multi-modal datasets: Sketchy, TU-Berlin, Mask1K, and SKSF-A. Additionally, the results suggest that the model can estimate latent concepts from vast unimodal data and generalize these concepts to unseen modalities using only a limited number of available samples, much like human cognitive processes.