 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Knowledge-Action Gap by Evaluating LLMs in Dynamic Dental Clinical Scenarios
Jan 19, 2026The transition of Large Language Models (LLMs) from passive knowledge retrievers to autonomous clinical agents demands a shift in evaluation-from static accuracy to dynamic behavioral reliability. To explore this boundary in dentistry, a domain where high-quality AI advice uniquely empowers patient-participatory decision-making, we present the Standardized Clinical Management & Performance Evaluation (SCMPE) benchmark, which comprehensively assesses performance from knowledge-oriented evaluations (static objective tasks) to workflow-based simulations (multi-turn simulated patient interactions). Our analysis reveals that while models demonstrate high proficiency in static objective tasks, their performance precipitates in dynamic clinical dialogues, identifying that the primary bottleneck lies not in knowledge retention, but in the critical challenges of active information gathering and dynamic state tracking. Mapping "Guideline Adherence" versus "Decision Quality" reveals a prevalent "High Efficacy, Low Safety" risk in general models. Furthermore, we quantify the impact of Retrieval-Augmented Generation (RAG). While RAG mitigates hallucinations in static tasks, its efficacy in dynamic workflows is limited and heterogeneous, sometimes causing degradation. This underscores that external knowledge alone cannot bridge the reasoning gap without domain-adaptive pre-training. This study empirically charts the capability boundaries of dental LLMs, providing a roadmap for bridging the gap between standardized knowledge and safe, autonomous clinical practice.
Expanding Zero-Shot Object Counting with Rich Prompts
May 21, 2025Expanding pre-trained zero-shot counting models to handle unseen categories requires more than simply adding new prompts, as this approach does not achieve the necessary alignment between text and visual features for accurate counting. We introduce RichCount, the first framework to address these limitations, employing a two-stage training strategy that enhances text encoding and strengthens the model's association with objects in images. RichCount improves zero-shot counting for unseen categories through two key objectives: (1) enriching text features with a feed-forward network and adapter trained on text-image similarity, thereby creating robust, aligned representations; and (2) applying this refined encoder to counting tasks, enabling effective generalization across diverse prompts and complex images. In this manner, RichCount goes beyond simple prompt expansion to establish meaningful feature alignment that supports accurate counting across novel categories. Extensive experiments on three benchmark datasets demonstrate the effectiveness of RichCount, achieving state-of-the-art performance in zero-shot counting and significantly enhancing generalization to unseen categories in open-world scenarios.
DenseTrack: Drone-based Crowd Tracking via Density-aware Motion-appearance Synergy
Jul 26, 2024



Drone-based crowd tracking faces difficulties in accurately identifying and monitoring objects from an aerial perspective, largely due to their small size and close proximity to each other, which complicates both localization and tracking. To address these challenges, we present the Density-aware Tracking (DenseTrack) framework. DenseTrack capitalizes on crowd counting to precisely determine object locations, blending visual and motion cues to improve the tracking of small-scale objects. It specifically addresses the problem of cross-frame motion to enhance tracking accuracy and dependability. DenseTrack employs crowd density estimates as anchors for exact object localization within video frames. These estimates are merged with motion and position information from the tracking network, with motion offsets serving as key tracking cues. Moreover, DenseTrack enhances the ability to distinguish small-scale objects using insights from the visual-language model, integrating appearance with motion cues. The framework utilizes the Hungarian algorithm to ensure the accurate matching of individuals across frames. Demonstrated on DroneCrowd dataset, our approach exhibits superior performance, confirming its effectiveness in scenarios captured by drones.
Zero-shot Object Counting with Good Exemplars
Jul 09, 2024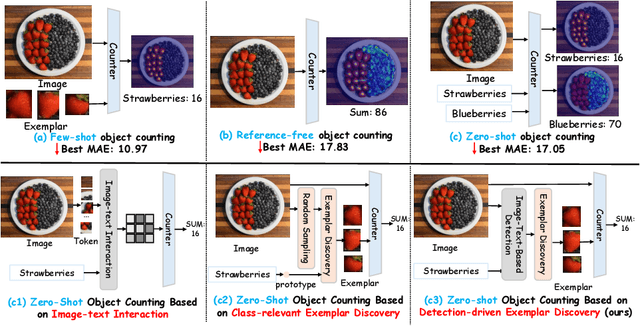


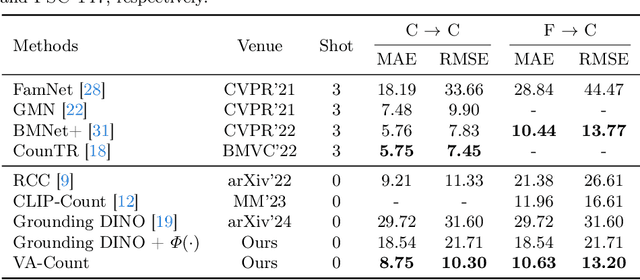
Zero-shot object counting (ZOC) aims to enumerate objects in images using only the names of object classes during testing, without the need for manual annotations. However, a critical challenge in current ZOC methods lies in their inability to identify high-quality exemplars effectively. This deficiency hampers scalability across diverse classes and undermines the development of strong visual associations between the identified classes and image content. To this end, we propose the Visual Association-based Zero-shot Object Counting (VA-Count) framework. VA-Count consists of an Exemplar Enhancement Module (EEM) and a Noise Suppression Module (NSM) that synergistically refine the process of class exemplar identification while minimizing the consequences of incorrect object identification. The EEM utilizes advanced vision-language pretaining models to discover potential exemplars, ensuring the framework's adaptability to various classes. Meanwhile, the NSM employs contrastive learning to differentiate between optimal and suboptimal exemplar pairs, reducing the negative effects of erroneous exemplars. VA-Count demonstrates its effectiveness and scalability in zero-shot contexts with superior performance on two object counting datasets.
OneRestore: A Universal Restoration Framework for Composite Degradation
Jul 05, 2024



In real-world scenarios, image impairments often manifest as composite degradations, presenting a complex interplay of elements such as low light, haze, rain, and snow. Despite this reality, existing restoration methods typically target isolated degradation types, thereby falling short in environments where multiple degrading factors coexist. To bridge this gap, our study proposes a versatile imaging model that consolidates four physical corruption paradigms to accurately represent complex, composite degradation scenarios. In this context, we propose OneRestore, a novel transformer-based framework designed for adaptive, controllable scene restoration. The proposed framework leverages a unique cross-attention mechanism, merging degraded scene descriptors with image features, allowing for nuanced restoration. Our model allows versatile input scene descriptors, ranging from manual text embeddings to automatic extractions based on visual attributes. Our methodology is further enhanced through a composite degradation restoration loss, using extra degraded images as negative samples to fortify model constraints. Comparative results on synthetic and real-world datasets demonstrate OneRestore as a superior solution, significantly advancing the state-of-the-art in addressing complex, composite degradations.
DAOT: Domain-Agnostically Aligned Optimal Transport for Domain-Adaptive Crowd Counting
Aug 10, 2023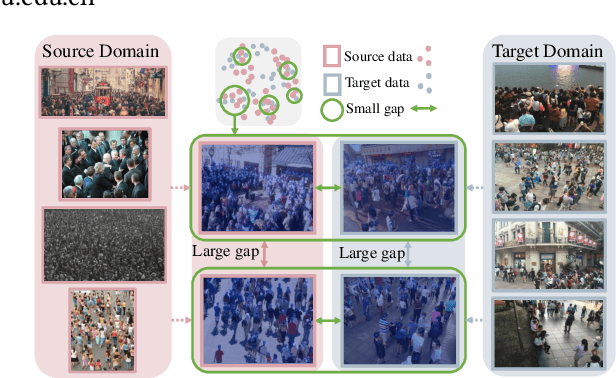



Domain adaptation is commonly employed in crowd counting to bridge the domain gaps between different datasets. However, existing domain adaptation methods tend to focus on inter-dataset differences while overlooking the intra-differences within the same dataset, leading to additional learning ambiguities. These domain-agnostic factors, e.g., density, surveillance perspective, and scale, can cause significant in-domain variations, and the misalignment of these factors across domains can lead to a drop in performance in cross-domain crowd counting. To address this issue, we propose a Domain-agnostically Aligned Optimal Transport (DAOT) strategy that aligns domain-agnostic factors between domains. The DAOT consists of three steps. First, individual-level differences in domain-agnostic factors are measured using structural similarity (SSIM). Second, the optimal transfer (OT) strategy is employed to smooth out these differences and find the optimal domain-to-domain misalignment, with outlier individuals removed via a virtual "dustbin" column. Third, knowledge is transferred based on the aligned domain-agnostic factors, and the model is retrained for domain adaptation to bridge the gap across domains. We conduct extensive experiments on five standard crowd-counting benchmarks and demonstrate that the proposed method has strong generalizability across diverse datasets. Our code will be available at: https://github.com/HopooLinZ/DAOT/.