 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget by Uncertainty: Orthogonal Entropy Unlearning for Quantized Neural Networks
Jan 31, 2026The deployment of quantized neural networks on edge devices, combined with privacy regulations like GDPR, creates an urgent need for machine unlearning in quantized models. However, existing methods face critical challenges: they induce forgetting by training models to memorize incorrect labels, conflating forgetting with misremembering, and employ scalar gradient reweighting that cannot resolve directional conflicts between gradients. We propose OEU, a novel Orthogonal Entropy Unlearning framework with two key innovations: 1) Entropy-guided unlearning maximizes prediction uncertainty on forgotten data, achieving genuine forgetting rather than confident misprediction, and 2) Gradient orthogonal projection eliminates interference by projecting forgetting gradients onto the orthogonal complement of retain gradients, providing theoretical guarantees for utility preservation under first-order approximation. Extensive experiments demonstrate that OEU outperforms existing methods in both forgetting effectiveness and retain accuracy.
Sparsity-Aware Unlearning for Large Language Models
Jan 31, 2026Large Language Models (LLMs) inevitably memorize sensitive information during training, posing significant privacy risks. Machine unlearning has emerged as a promising solution to selectively remove such information without full retraining. However, existing methods are designed for dense models and overlook model sparsification-an essential technique for efficient LLM deployment. We find that unlearning effectiveness degrades substantially on sparse models. Through empirical analysis, we reveal that this degradation occurs because existing unlearning methods require updating all parameters, yet sparsification prunes substantial weights to zero, fundamentally limiting the model's forgetting capacity. To address this challenge, we propose Sparsity-Aware Unlearning (SAU), which decouples unlearning from sparsification objectives through gradient masking that redirects updates to surviving weights, combined with importance-aware redistribution to compensate for pruned parameters. Extensive experiments demonstrate that SAU significantly outperforms existing methods on sparse LLMs, achieving effective forgetting while preserving model utility.
Seg-Wild: Interactive Segmentation based on 3D Gaussian Splatting for Unconstrained Image Collections
Jul 10, 2025
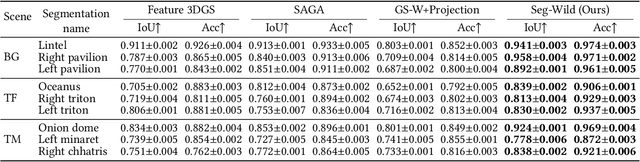
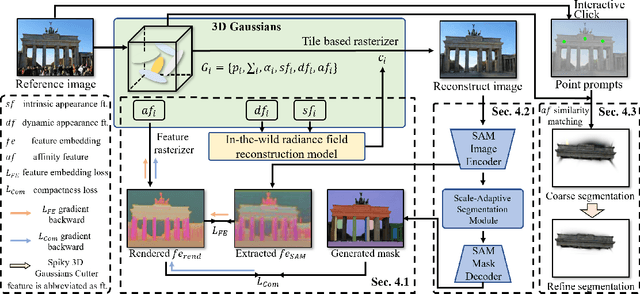
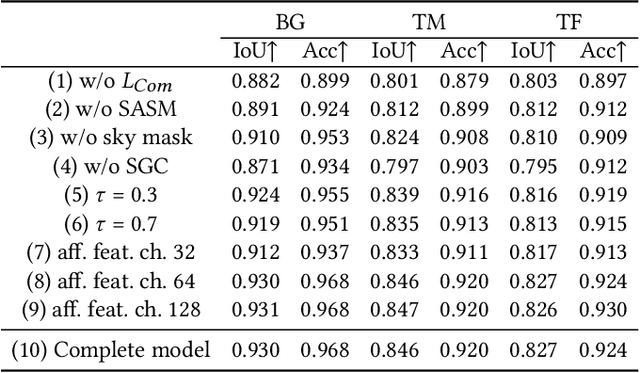
Reconstructing and segmenting scenes from unconstrained photo collections obtained from the Internet is a novel but challenging task. Unconstrained photo collections are easier to get than well-captured photo collections. These unconstrained images suffer from inconsistent lighting and transient occlusions, which makes segmentation challenging. Previous segmentation methods cannot address transient occlusions or accurately restore the scene's lighting conditions. Therefore, we propose Seg-Wild, an interactive segmentation method based on 3D Gaussian Splatting for unconstrained image collections, suitable for in-the-wild scenes. We integrate multi-dimensional feature embeddings for each 3D Gaussian and calculate the feature similarity between the feature embeddings and the segmentation target to achieve interactive segmentation in the 3D scene. Additionally, we introduce the Spiky 3D Gaussian Cutter (SGC) to smooth abnormal 3D Gaussians. We project the 3D Gaussians onto a 2D plane and calculate the ratio of 3D Gaussians that need to be cut using the SAM mask. We also designed a benchmark to evaluate segmentation quality in in-the-wild scenes. Experimental results demonstrate that compared to previous methods, Seg-Wild achieves better segmentation results and reconstruction quality. Our code will be available at https://github.com/Sugar0725/Seg-Wild.
DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion
Jun 26, 2025Reconstructing 3D objects from a single image is a long-standing challenge, especially under real-world occlusions. While recent diffusion-based view synthesis models can generate consistent novel views from a single RGB image, they generally assume fully visible inputs and fail when parts of the object are occluded. This leads to inconsistent views and degraded 3D reconstruction quality. To overcome this limitation, we propose an end-to-end framework for occlusion-aware multi-view generation. Our method directly synthesizes six structurally consistent novel views from a single partially occluded image, enabling downstream 3D reconstruction without requiring prior inpainting or manual annotations. We construct a self-supervised training pipeline using the Pix2Gestalt dataset, leveraging occluded-unoccluded image pairs and pseudo-ground-truth views to teach the model structure-aware completion and view consistency. Without modifying the original architecture, we fully fine-tune the view synthesis model to jointly learn completion and multi-view generation. Additionally, we introduce the first benchmark for occlusion-aware reconstruction, encompassing diverse occlusion levels, object categories, and mask patterns. This benchmark provides a standardized protocol for evaluating future methods under partial occlusions. Our code is available at https://github.com/Quyans/DeOcc123.
A Joint Learning Framework with Feature Reconstruction and Prediction for Incomplete Satellite Image Time Series in Agricultural Semantic Segmentation
May 25, 2025



Satellite Image Time Series (SITS) is crucial for agricultural semantic segmentation. However, Cloud contamination introduces time gaps in SITS, disrupting temporal dependencies and causing feature shifts, leading to degraded performance of models trained on complete SITS. Existing methods typically address this by reconstructing the entire SITS before prediction or using data augmentation to simulate missing data. Yet, full reconstruction may introduce noise and redundancy, while the data-augmented model can only handle limited missing patterns, leading to poor generalization. We propose a joint learning framework with feature reconstruction and prediction to address incomplete SITS more effectively. During training, we simulate data-missing scenarios using temporal masks. The two tasks are guided by both ground-truth labels and the teacher model trained on complete SITS. The prediction task constrains the model from selectively reconstructing critical features from masked inputs that align with the teacher's temporal feature representations. It reduces unnecessary reconstruction and limits noise propagation. By integrating reconstructed features into the prediction task, the model avoids learning shortcuts and maintains its ability to handle varied missing patterns and complete SITS. Experiments on SITS from Hunan Province, Western France, and Catalonia show that our method improves mean F1-scores by 6.93% in cropland extraction and 7.09% in crop classification over baselines. It also generalizes well across satellite sensors, including Sentinel-2 and PlanetScope, under varying temporal missing rates and model backbones.
Robust Machine Unlearning for Quantized Neural Networks via Adaptive Gradient Reweighting with Similar Labels
Mar 18, 2025Model quantization enables efficient deployment of deep neural networks on edge devices through low-bit parameter representation, yet raises critical challenges for implementing machine unlearning (MU) under data privacy regulations. Existing MU methods designed for full-precision models fail to address two fundamental limitations in quantized networks: 1) Noise amplification from label mismatch during data processing, and 2) Gradient imbalance between forgotten and retained data during training. These issues are exacerbated by quantized models' constrained parameter space and discrete optimization. We propose Q-MUL, the first dedicated unlearning framework for quantized models. Our method introduces two key innovations: 1) Similar Labels assignment replaces random labels with semantically consistent alternatives to minimize noise injection, and 2) Adaptive Gradient Reweighting dynamically aligns parameter update contributions from forgotten and retained data. Through systematic analysis of quantized model vulnerabilities, we establish theoretical foundations for these mechanisms. Extensive evaluations on benchmark datasets demonstrate Q-MUL's superiority over existing approaches.
Enhancing Scene Classification in Cloudy Image Scenarios: A Collaborative Transfer Method with Information Regulation Mechanism using Optical Cloud-Covered and SAR Remote Sensing Images
Jan 08, 2025



In remote sensing scene classification, leveraging the transfer methods with well-trained optical models is an efficient way to overcome label scarcity. However, cloud contamination leads to optical information loss and significant impacts on feature distribution, challenging the reliability and stability of transferred target models. Common solutions include cloud removal for optical data or directly using Synthetic aperture radar (SAR) data in the target domain. However, cloud removal requires substantial auxiliary data for support and pre-training, while directly using SAR disregards the unobstructed portions of optical data. This study presents a scene classification transfer method that synergistically combines multi-modality data, which aims to transfer the source domain model trained on cloudfree optical data to the target domain that includes both cloudy optical and SAR data at low cost. Specifically, the framework incorporates two parts: (1) the collaborative transfer strategy, based on knowledge distillation, enables the efficient prior knowledge transfer across heterogeneous data; (2) the information regulation mechanism (IRM) is proposed to address the modality imbalance issue during transfer. It employs auxiliary models to measure the contribution discrepancy of each modality, and automatically balances the information utilization of modalities during the target model learning process at the sample-level. The transfer experiments were conducted on simulated and real cloud datasets, demonstrating the superior performance of the proposed method compared to other solutions in cloud-covered scenarios. We also verified the importance and limitations of IRM, and further discussed and visualized the modality imbalance problem during the model transfer. Codes are available at https://github.com/wangyuze-csu/ESCCS
Weakly Supervised Framework Considering Multi-temporal Information for Large-scale Cropland Mapping with Satellite Imagery
Nov 27, 2024



Accurately mapping large-scale cropland is crucial for agricultural production management and planning. Currently, the combination of remote sensing data and deep learning techniques has shown outstanding performance in cropland mapping. However, those approaches require massive precise labels, which are labor-intensive. To reduce the label cost, this study presented a weakly supervised framework considering multi-temporal information for large-scale cropland mapping. Specifically, we extract high-quality labels according to their consistency among global land cover (GLC) products to construct the supervised learning signal. On the one hand, to alleviate the overfitting problem caused by the model's over-trust of remaining errors in high-quality labels, we encode the similarity/aggregation of cropland in the visual/spatial domain to construct the unsupervised learning signal, and take it as the regularization term to constrain the supervised part. On the other hand, to sufficiently leverage the plentiful information in the samples without high-quality labels, we also incorporate the unsupervised learning signal in these samples, enriching the diversity of the feature space. After that, to capture the phenological features of croplands, we introduce dense satellite image time series (SITS) to extend the proposed framework in the temporal dimension. We also visualized the high dimensional phenological features to uncover how multi-temporal information benefits cropland extraction, and assessed the method's robustness under conditions of data scarcity. The proposed framework has been experimentally validated for strong adaptability across three study areas (Hunan Province, Southeast France, and Kansas) in large-scale cropland mapping, and the internal mechanism and temporal generalizability are also investigated.
SCARF: Scalable Continual Learning Framework for Memory-efficient Multiple Neural Radiance Fields
Sep 06, 2024This paper introduces a novel continual learning framework for synthesising novel views of multiple scenes, learning multiple 3D scenes incrementally, and updating the network parameters only with the training data of the upcoming new scene. We build on Neural Radiance Fields (NeRF), which uses multi-layer perceptron to model the density and radiance field of a scene as the implicit function. While NeRF and its extensions have shown a powerful capability of rendering photo-realistic novel views in a single 3D scene, managing these growing 3D NeRF assets efficiently is a new scientific problem. Very few works focus on the efficient representation or continuous learning capability of multiple scenes, which is crucial for the practical applications of NeRF. To achieve these goals, our key idea is to represent multiple scenes as the linear combination of a cross-scene weight matrix and a set of scene-specific weight matrices generated from a global parameter generator. Furthermore, we propose an uncertain surface knowledge distillation strategy to transfer the radiance field knowledge of previous scenes to the new model. Representing multiple 3D scenes with such weight matrices significantly reduces memory requirements. At the same time, the uncertain surface distillation strategy greatly overcomes the catastrophic forgetting problem and maintains the photo-realistic rendering quality of previous scenes. Experiments show that the proposed approach achieves state-of-the-art rendering quality of continual learning NeRF on NeRF-Synthetic, LLFF, and TanksAndTemples datasets while preserving extra low storage cost.
WE-GS: An In-the-wild Efficient 3D Gaussian Representation for Unconstrained Photo Collections
Jun 04, 2024Novel View Synthesis (NVS) from unconstrained photo collections is challenging in computer graphics. Recently, 3D Gaussian Splatting (3DGS) has shown promise for photorealistic and real-time NVS of static scenes. Building on 3DGS, we propose an efficient point-based differentiable rendering framework for scene reconstruction from photo collections. Our key innovation is a residual-based spherical harmonic coefficients transfer module that adapts 3DGS to varying lighting conditions and photometric post-processing. This lightweight module can be pre-computed and ensures efficient gradient propagation from rendered images to 3D Gaussian attributes. Additionally, we observe that the appearance encoder and the transient mask predictor, the two most critical parts of NVS from unconstrained photo collections, can be mutually beneficial. We introduce a plug-and-play lightweight spatial attention module to simultaneously predict transient occluders and latent appearance representation for each image. After training and preprocessing, our method aligns with the standard 3DGS format and rendering pipeline, facilitating seamlessly integration into various 3DGS applications. Extensive experiments on diverse datasets show our approach outperforms existing approaches on the rendering quality of novel view and appearance synthesis with high converge and rendering speed.