 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Correlation: Refutation-Validated Aspect-Based Sentiment Analysis for Explainable Energy Market Returns
Mar 23, 2026This paper proposes a refutation-validated framework for aspect-based sentiment analysis in financial markets, addressing the limitations of correlational studies that cannot distinguish genuine associations from spurious ones. Using X data for the energy sector, we test whether aspect-level sentiment signals show robust, refutation-validated relationships with equity returns. Our pipeline combines net-ratio scoring with z-normalization, OLS with Newey West HAC errors, and refutation tests including placebo, random common cause, subset stability, and bootstrap. Across six energy tickers, only a few associations survive all checks, while renewables show aspect and horizon specific responses. While not establishing causality, the framework provides statistically robust, directionally interpretable signals, with limited sample size (six stocks, one quarter) constraining generalizability and framing this work as a methodological proof of concept.
Understanding Refusal in Language Models with Sparse Autoencoders
May 29, 2025Refusal is a key safety behavior in aligned language models, yet the internal mechanisms driving refusals remain opaque. In this work, we conduct a mechanistic study of refusal in instruction-tuned LLMs using sparse autoencoders to identify latent features that causally mediate refusal behaviors. We apply our method to two open-source chat models and intervene on refusal-related features to assess their influence on generation, validating their behavioral impact across multiple harmful datasets. This enables a fine-grained inspection of how refusal manifests at the activation level and addresses key research questions such as investigating upstream-downstream latent relationship and understanding the mechanisms of adversarial jailbreaking techniques. We also establish the usefulness of refusal features in enhancing generalization for linear probes to out-of-distribution adversarial samples in classification tasks. We open source our code in https://github.com/wj210/refusal_sae.
Debiasing CLIP: Interpreting and Correcting Bias in Attention Heads
May 23, 2025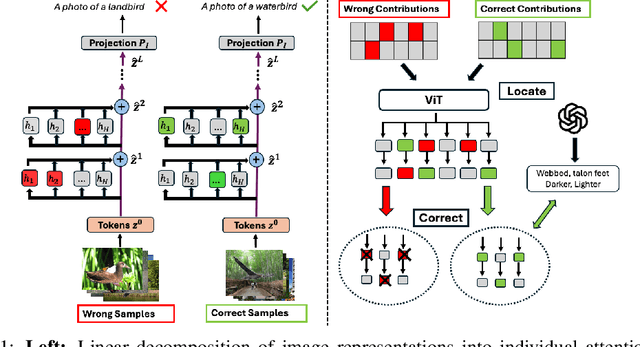
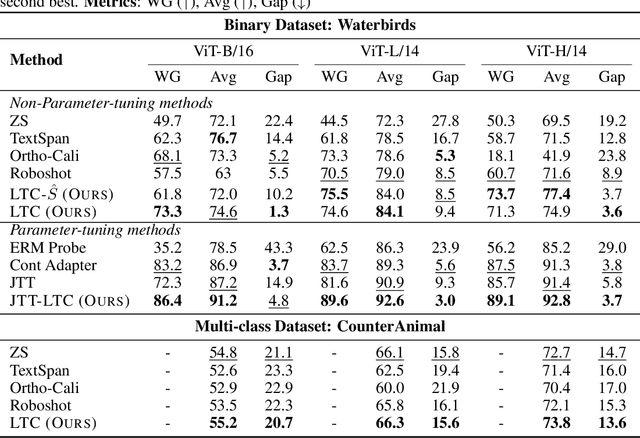
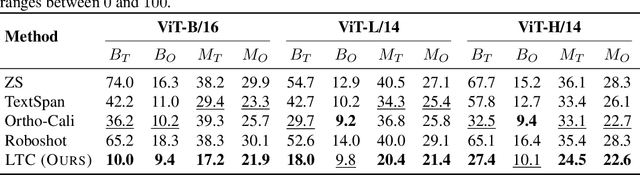

Multimodal models like CLIP have gained significant attention due to their remarkable zero-shot performance across various tasks. However, studies have revealed that CLIP can inadvertently learn spurious associations between target variables and confounding factors. To address this, we introduce \textsc{Locate-Then-Correct} (LTC), a contrastive framework that identifies spurious attention heads in Vision Transformers via mechanistic insights and mitigates them through targeted ablation. Furthermore, LTC identifies salient, task-relevant attention heads, enabling the integration of discriminative features through orthogonal projection to improve classification performance. We evaluate LTC on benchmarks with inherent background and gender biases, achieving over a $>50\%$ gain in worst-group accuracy compared to non-training post-hoc baselines. Additionally, we visualize the representation of selected heads and find that the presented interpretation corroborates our contrastive mechanism for identifying both spurious and salient attention heads. Code available at https://github.com/wj210/CLIP_LTC.
ESGSenticNet: A Neurosymbolic Knowledge Base for Corporate Sustainability Analysis
Jan 27, 2025


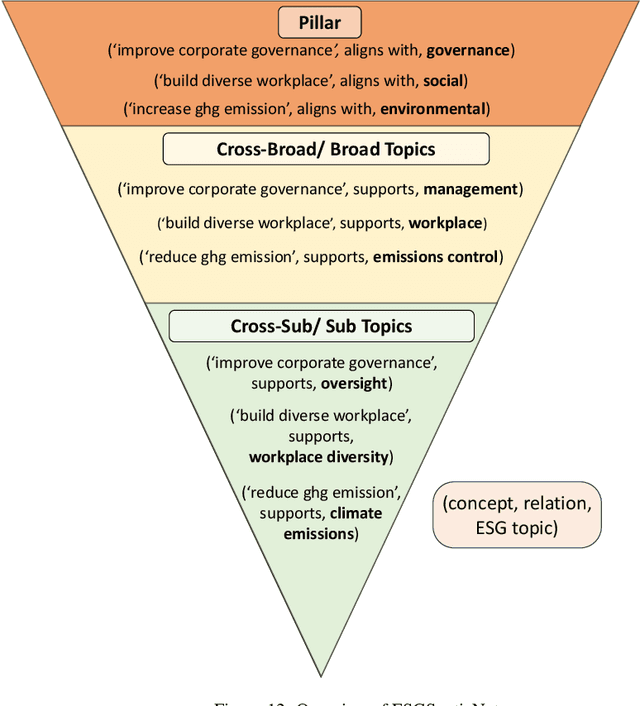
Evaluating corporate sustainability performance is essential to drive sustainable business practices, amid the need for a more sustainable economy. However, this is hindered by the complexity and volume of corporate sustainability data (i.e. sustainability disclosures), not least by the effectiveness of the NLP tools used to analyse them. To this end, we identify three primary challenges - immateriality, complexity, and subjectivity, that exacerbate the difficulty of extracting insights from sustainability disclosures. To address these issues, we introduce ESGSenticNet, a publicly available knowledge base for sustainability analysis. ESGSenticNet is constructed from a neurosymbolic framework that integrates specialised concept parsing, GPT-4o inference, and semi-supervised label propagation, together with a hierarchical taxonomy. This approach culminates in a structured knowledge base of 44k knowledge triplets - ('halve carbon emission', supports, 'emissions control'), for effective sustainability analysis. Experiments indicate that ESGSenticNet, when deployed as a lexical method, more effectively captures relevant and actionable sustainability information from sustainability disclosures compared to state of the art baselines. Besides capturing a high number of unique ESG topic terms, ESGSenticNet outperforms baselines on the ESG relatedness and ESG action orientation of these terms by 26% and 31% respectively. These metrics describe the extent to which topic terms are related to ESG, and depict an action toward ESG. Moreover, when deployed as a lexical method, ESGSenticNet does not require any training, possessing a key advantage in its simplicity for non-technical stakeholders.
SusGen-GPT: A Data-Centric LLM for Financial NLP and Sustainability Report Generation
Dec 14, 2024The rapid growth of the financial sector and the rising focus on Environmental, Social, and Governance (ESG) considerations highlight the need for advanced NLP tools. However, open-source LLMs proficient in both finance and ESG domains remain scarce. To address this gap, we introduce SusGen-30K, a category-balanced dataset comprising seven financial NLP tasks and ESG report generation, and propose TCFD-Bench, a benchmark for evaluating sustainability report generation. Leveraging this dataset, we developed SusGen-GPT, a suite of models achieving state-of-the-art performance across six adapted and two off-the-shelf tasks, trailing GPT-4 by only 2% despite using 7-8B parameters compared to GPT-4's 1,700B. Based on this, we propose the SusGen system, integrated with Retrieval-Augmented Generation (RAG), to assist in sustainability report generation. This work demonstrates the efficiency of our approach, advancing research in finance and ESG.
Self-training Large Language Models through Knowledge Detection
Jun 17, 2024



Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
How Interpretable are Reasoning Explanations from Prompting Large Language Models?
Feb 25, 2024



Prompt Engineering has garnered significant attention for enhancing the performance of large language models across a multitude of tasks. Techniques such as the Chain-of-Thought not only bolster task performance but also delineate a clear trajectory of reasoning steps, offering a tangible form of explanation for the audience. Prior works on interpretability assess the reasoning chains yielded by Chain-of-Thought solely along a singular axis, namely faithfulness. We present a comprehensive and multifaceted evaluation of interpretability, examining not only faithfulness but also robustness and utility across multiple commonsense reasoning benchmarks. Likewise, our investigation is not confined to a single prompting technique; it expansively covers a multitude of prevalent prompting techniques employed in large language models, thereby ensuring a wide-ranging and exhaustive evaluation. In addition, we introduce a simple interpretability alignment technique, termed Self-Entailment-Alignment Chain-of-thought, that yields more than 70\% improvements across multiple dimensions of interpretability. Code is available at https://github.com/wj210/CoT_interpretability
Plausible Extractive Rationalization through Semi-Supervised Entailment Signal
Feb 25, 2024



The increasing use of complex and opaque black box models requires the adoption of interpretable measures, one such option is extractive rationalizing models, which serve as a more interpretable alternative. These models, also known as Explain-Then-Predict models, employ an explainer model to extract rationales and subsequently condition the predictor with the extracted information. Their primary objective is to provide precise and faithful explanations, represented by the extracted rationales. In this paper, we take a semi-supervised approach to optimize for the plausibility of extracted rationales. We adopt a pre-trained natural language inference (NLI) model and further fine-tune it on a small set of supervised rationales ($10\%$). The NLI predictor is leveraged as a source of supervisory signals to the explainer via entailment alignment. We show that, by enforcing the alignment agreement between the explanation and answer in a question-answering task, the performance can be improved without access to ground truth labels. We evaluate our approach on the ERASER dataset and show that our approach achieves comparable results with supervised extractive models and outperforms unsupervised approaches by $> 100\%$.
A Comprehensive Review on Financial Explainable AI
Sep 21, 2023
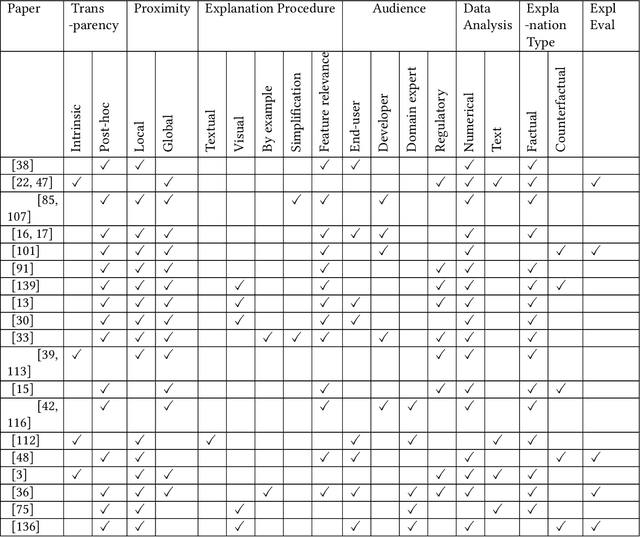


The success of artificial intelligence (AI), and deep learning models in particular, has led to their widespread adoption across various industries due to their ability to process huge amounts of data and learn complex patterns. However, due to their lack of explainability, there are significant concerns regarding their use in critical sectors, such as finance and healthcare, where decision-making transparency is of paramount importance. In this paper, we provide a comparative survey of methods that aim to improve the explainability of deep learning models within the context of finance. We categorize the collection of explainable AI methods according to their corresponding characteristics, and we review the concerns and challenges of adopting explainable AI methods, together with future directions we deemed appropriate and important.
Recent Developments in Recommender Systems: A Survey
Jun 22, 2023



In this technical survey, we comprehensively summarize the latest advancements in the field of recommender systems. The objective of this study is to provide an overview of the current state-of-the-art in the field and highlight the latest trends in the development of recommender systems. The study starts with a comprehensive summary of the main taxonomy of recommender systems, including personalized and group recommender systems, and then delves into the category of knowledge-based recommender systems. In addition, the survey analyzes the robustness, data bias, and fairness issues in recommender systems, summarizing the evaluation metrics used to assess the performance of these systems. Finally, the study provides insights into the latest trends in the development of recommender systems and highlights the new directions for future research in the field.