 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Paper and Code
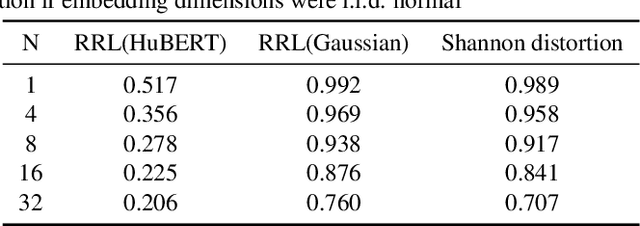
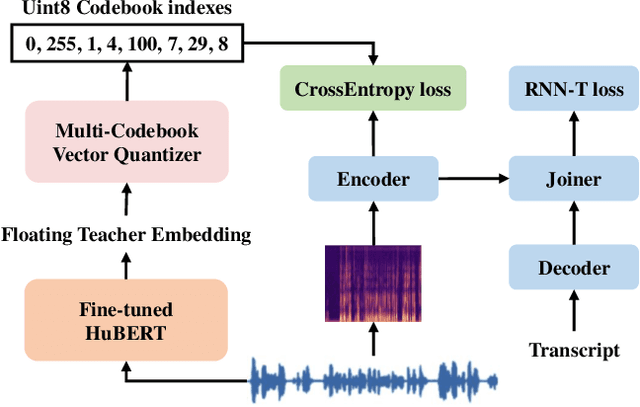

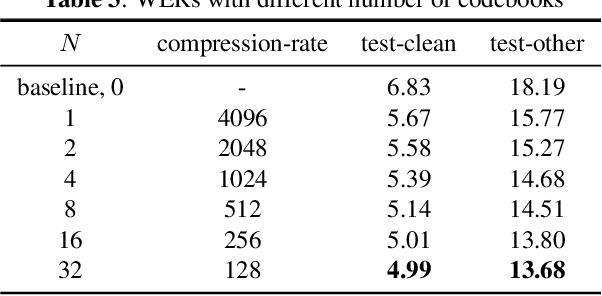
Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.