 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosyAccent: Duration-Controllable Accent Normalization Using Source-Synthesis Training Data
Feb 22, 2026Accent normalization (AN) systems often struggle with unnatural outputs and undesired content distortion, stemming from both suboptimal training data and rigid duration modeling. In this paper, we propose a "source-synthesis" methodology for training data construction. By generating source L2 speech and using authentic native speech as the training target, our approach avoids learning from TTS artifacts and, crucially, requires no real L2 data in training. Alongside this data strategy, we introduce CosyAccent, a non-autoregressive model that resolves the trade-off between prosodic naturalness and duration control. CosyAccent implicitly models rhythm for flexibility yet offers explicit control over total output duration. Experiments show that, despite being trained without any real L2 speech, CosyAccent achieves significantly improved content preservation and superior naturalness compared to strong baselines trained on real-world data.
MC-SpEx: Towards Effective Speaker Extraction with Multi-Scale Interfusion and Conditional Speaker Modulation
Jun 28, 2023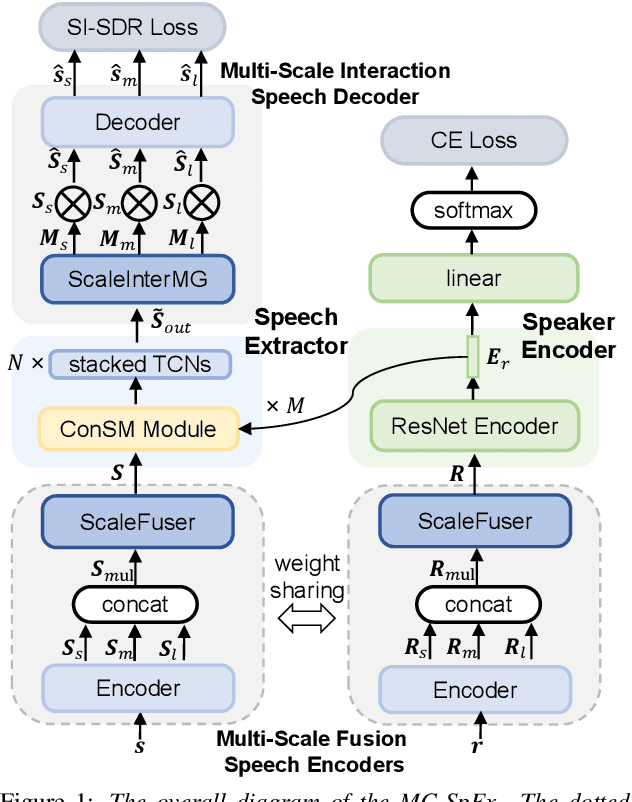

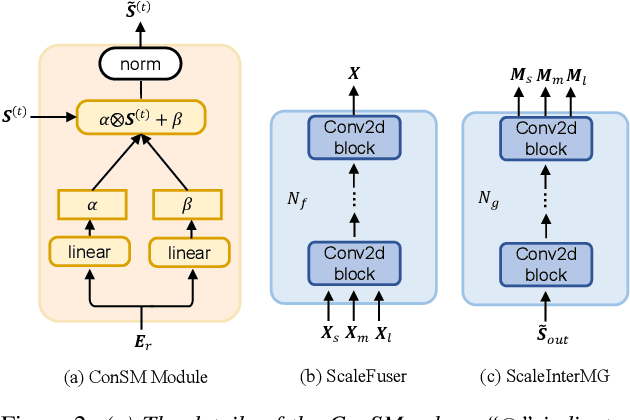

The previous SpEx+ has yielded outstanding performance in speaker extraction and attracted much attention. However, it still encounters inadequate utilization of multi-scale information and speaker embedding. To this end, this paper proposes a new effective speaker extraction system with multi-scale interfusion and conditional speaker modulation (ConSM), which is called MC-SpEx. First of all, we design the weight-share multi-scale fusers (ScaleFusers) for efficiently leveraging multi-scale information as well as ensuring consistency of the model's feature space. Then, to consider different scale information while generating masks, the multi-scale interactive mask generator (ScaleInterMG) is presented. Moreover, we introduce ConSM module to fully exploit speaker embedding in the speech extractor. Experimental results on the Libri2Mix dataset demonstrate the effectiveness of our improvements and the state-of-the-art performance of our proposed MC-SpEx.
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhancement System For ICASSP 2023 DNS Challenge
Mar 14, 2023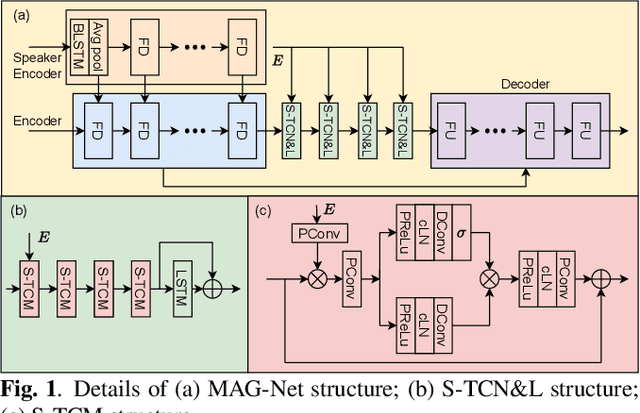


This paper introduces the Unbeatable Team's submission to the ICASSP 2023 Deep Noise Suppression (DNS) Challenge. We expand our previous work, TEA-PSE, to its upgraded version -- TEA-PSE 3.0. Specifically, TEA-PSE 3.0 incorporates a residual LSTM after squeezed temporal convolution network (S-TCN) to enhance sequence modeling capabilities. Additionally, the local-global representation (LGR) structure is introduced to boost speaker information extraction, and multi-STFT resolution loss is used to effectively capture the time-frequency characteristics of the speech signals. Moreover, retraining methods are employed based on the freeze training strategy to fine-tune the system. According to the official results, TEA-PSE 3.0 ranks 1st in both ICASSP 2023 DNS-Challenge track 1 and track 2.
Multi-Task Sub-Band Network For Deep Residual Echo Suppression
Mar 11, 2023


This paper introduces the SWANT team entry to the ICASSP 2023 AEC Challenge. We submit a system that cascades a linear filter with a neural post-filter. Particularly, we adopt sub-band processing to handle full-band signals and shape the network with multi-task learning, where dual signal voice activity detection (DSVAD) and echo estimation are adopted as auxiliary tasks. Moreover, we particularly improve the time frequency convolution module (TFCM) to increase the receptive field using small convolution kernels. Finally, our system has ranked 4th in ICASSP 2023 AEC Challenge Non-personalized track.
Local-global speaker representation for target speaker extraction
Oct 28, 2022



Target speaker extraction is to extract the target speaker's voice from a mixture of signals according to the given enrollment utterance. The target speaker's enrollment utterance is also called as anchor speech. The effective utilization of anchor speech is crucial for speaker extraction. In this study, we propose a new system to exploit speaker information from anchor speech fully. Unlike models that use only local or global features of the anchor, the proposed method extracts speaker information on global and local levels and feeds the features into a speech separation network. Our approach benefits from the complementary advantages of both global and local features, and the performance of speaker extraction is improved. We verified the feasibility of this local-global representation (LGR) method using multiple speaker extraction models. Systematic experiments were conducted on the open-source dataset Libri-2talker, and the results showed that the proposed method significantly outperformed the baseline models.
Speech Enhancement with Intelligent Neural Homomorphic Synthesis
Oct 28, 2022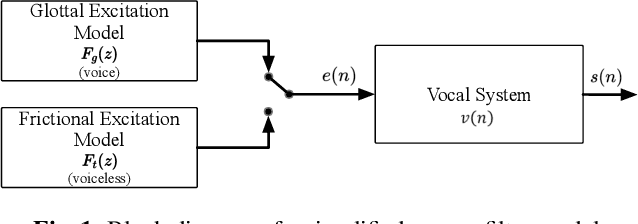
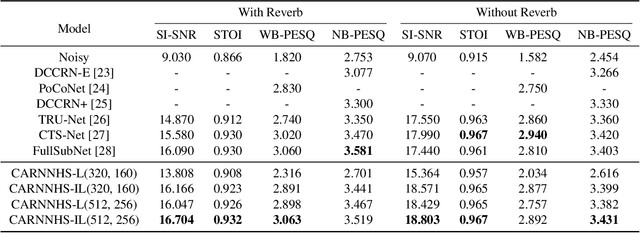

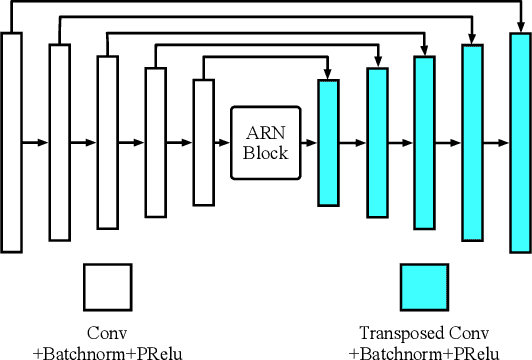
Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.
Personalized Acoustic Echo Cancellation for Full-duplex Communications
May 30, 2022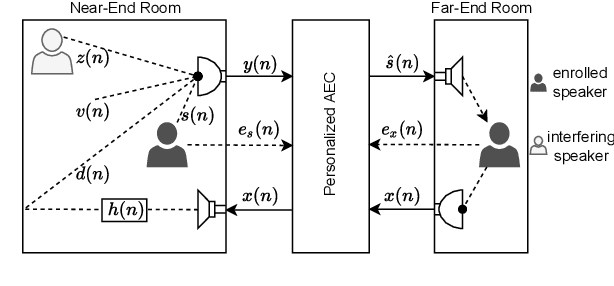

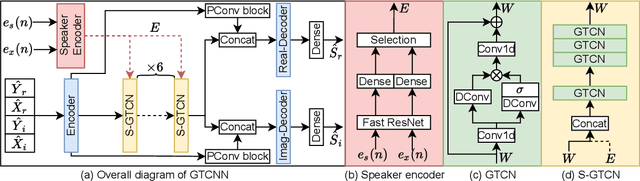
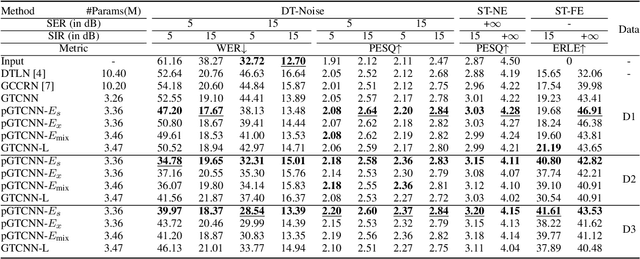
Deep neural networks (DNNs) have shown promising results for acoustic echo cancellation (AEC). But the DNN-based AEC models let through all near-end speakers including the interfering speech. In light of recent studies on personalized speech enhancement, we investigate the feasibility of personalized acoustic echo cancellation (PAEC) in this paper for full-duplex communications, where background noise and interfering speakers may coexist with acoustic echoes. Specifically, we first propose a novel backbone neural network termed as gated temporal convolutional neural network (GTCNN) that outperforms state-of-the-art AEC models in performance. Speaker embeddings like d-vectors are further adopted as auxiliary information to guide the GTCNN to focus on the target speaker. A special case in PAEC is that speech snippets of both parties on the call are enrolled. Experimental results show that auxiliary information from either the near-end speaker or the far-end speaker can improve the DNN-based AEC performance. Nevertheless, there is still much room for improvement in the utilization of the finite-dimensional speaker embeddings.