 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Acoustic Echo Cancellation and Speech Dereverberation Using Kalman filters
Feb 09, 2023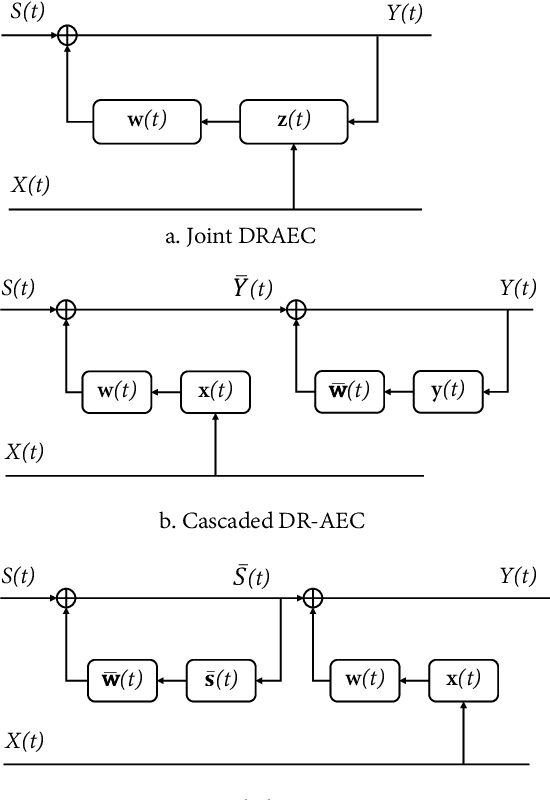

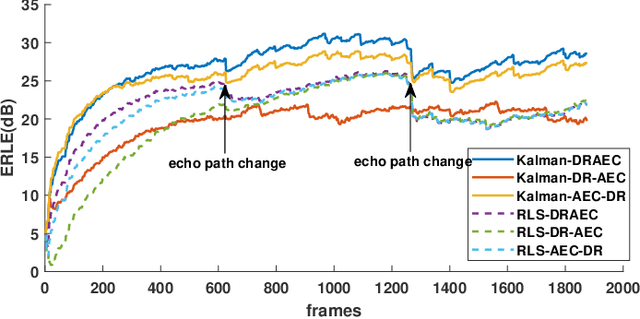

This paper proposes a joint acoustic echo cancellation (AEC) and speech dereverberation (DR) algorithm in the short-time Fourier transform domain. The reverberant microphone signals are described using an auto-regressive (AR) model. The AR coefficients and the loudspeaker-to-microphone acoustic transfer functions (ATFs) are considered time-varying and are modeled simultaneously using a first-order Markov process. This leads to a solution where these parameters can be optimally estimated using Kalman filters. It is shown that the proposed algorithm outperforms vanilla solutions that solve AEC and DR sequentially and one state-of-the-art joint DRAEC algorithm based on semi-blind source separation, in terms of both speech quality and echo reduction performance.
Personalized Acoustic Echo Cancellation for Full-duplex Communications
May 30, 2022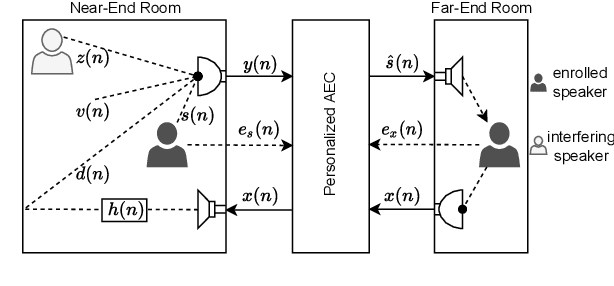

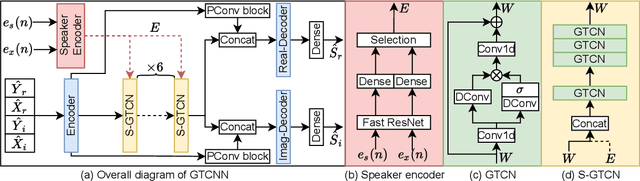
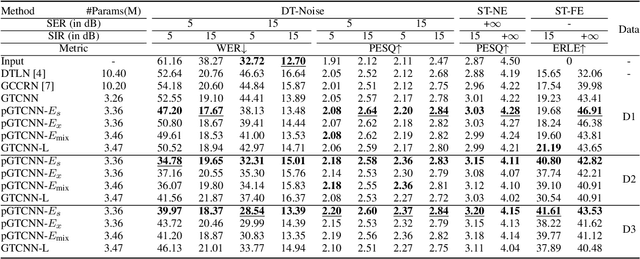
Deep neural networks (DNNs) have shown promising results for acoustic echo cancellation (AEC). But the DNN-based AEC models let through all near-end speakers including the interfering speech. In light of recent studies on personalized speech enhancement, we investigate the feasibility of personalized acoustic echo cancellation (PAEC) in this paper for full-duplex communications, where background noise and interfering speakers may coexist with acoustic echoes. Specifically, we first propose a novel backbone neural network termed as gated temporal convolutional neural network (GTCNN) that outperforms state-of-the-art AEC models in performance. Speaker embeddings like d-vectors are further adopted as auxiliary information to guide the GTCNN to focus on the target speaker. A special case in PAEC is that speech snippets of both parties on the call are enrolled. Experimental results show that auxiliary information from either the near-end speaker or the far-end speaker can improve the DNN-based AEC performance. Nevertheless, there is still much room for improvement in the utilization of the finite-dimensional speaker embeddings.
Controllable Multichannel Speech Dereverberation based on Deep Neural Networks
Oct 16, 2021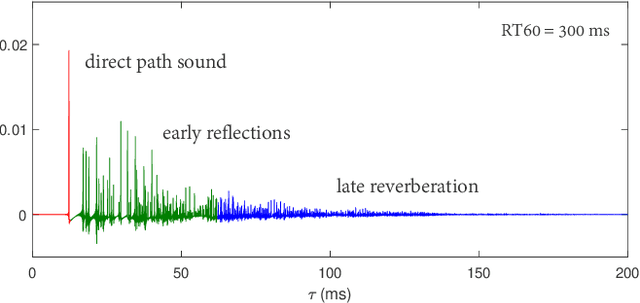
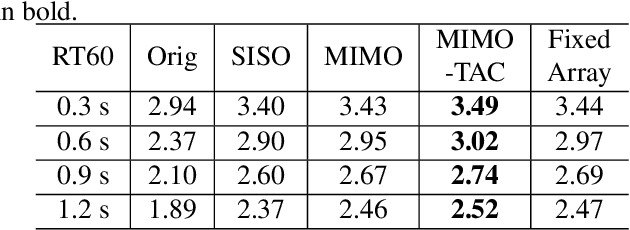
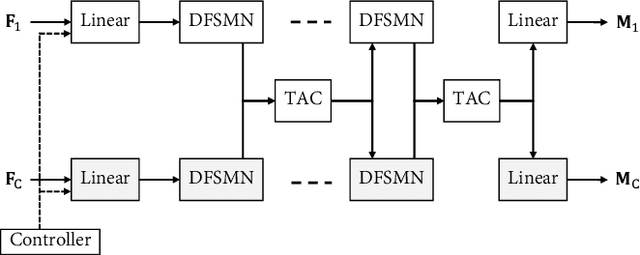
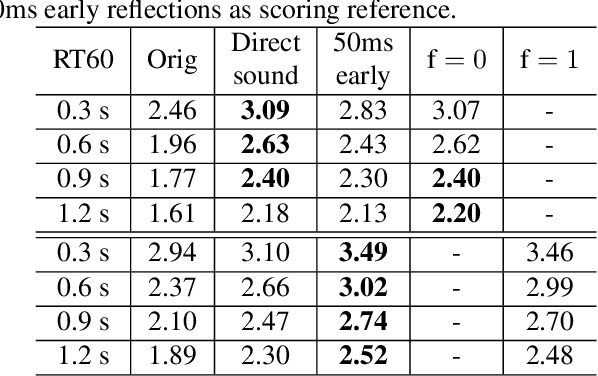
Neural network based speech dereverberation has achieved promising results in recent studies. Nevertheless, many are focused on recovery of only the direct path sound and early reflections, which could be beneficial to speech perception, are discarded. The performance of a model trained to recover clean speech degrades when evaluated on early reverberation targets, and vice versa. This paper proposes a novel deep neural network based multichannel speech dereverberation algorithm, in which the dereverberation level is controllable. This is realized by adding a simple floating-point number as target controller of the model. Experiments are conducted using spatially distributed microphones, and the efficacy of the proposed algorithm is confirmed in various simulated conditions.
NN3A: Neural Network supported Acoustic Echo Cancellation, Noise Suppression and Automatic Gain Control for Real-Time Communications
Oct 16, 2021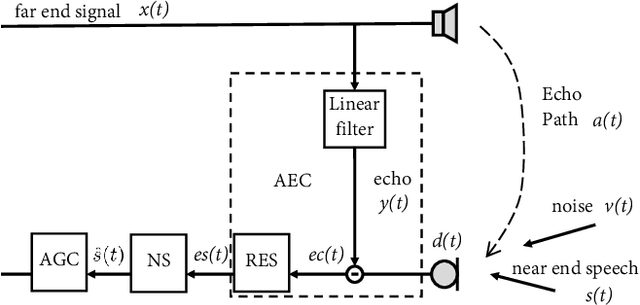

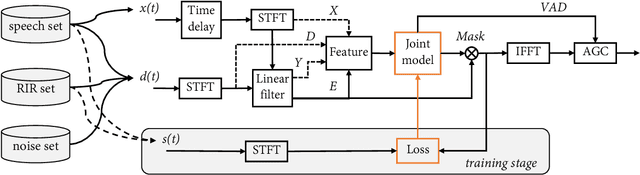

Acoustic echo cancellation (AEC), noise suppression (NS) and automatic gain control (AGC) are three often required modules for real-time communications (RTC). This paper proposes a neural network supported algorithm for RTC, namely NN3A, which incorporates an adaptive filter and a multi-task model for residual echo suppression, noise reduction and near-end speech activity detection. The proposed algorithm is shown to outperform both a method using separate models and an end-to-end alternative. It is further shown that there exists a trade-off in the model between residual suppression and near-end speech distortion, which could be balanced by a novel loss weighting function. Several practical aspects of training the joint model are also investigated to push its performance to limit.
Joint Online Multichannel Acoustic Echo Cancellation, Speech Dereverberation and Source Separation
Apr 09, 2021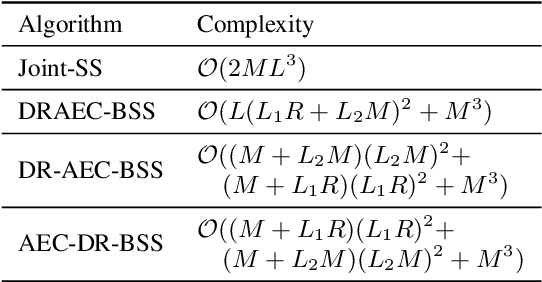
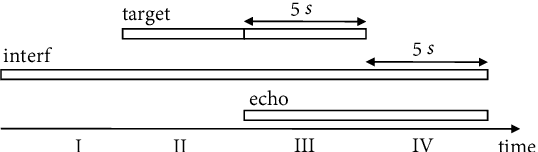
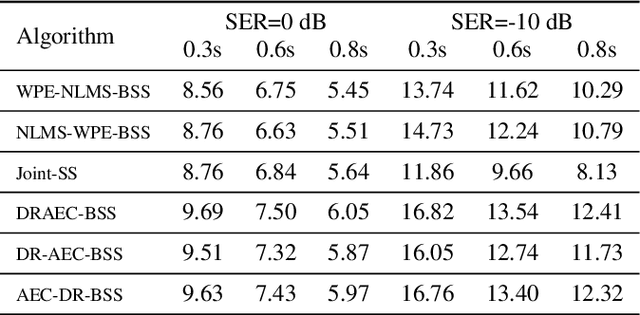
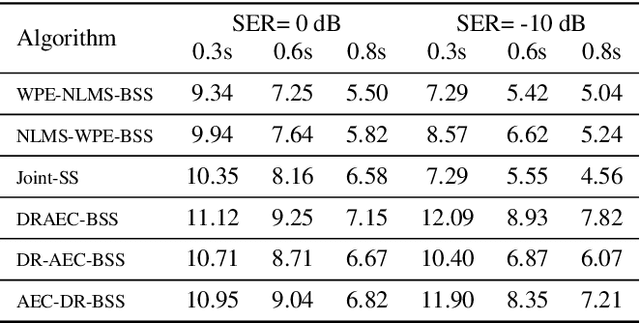
This paper presents a joint source separation algorithm that simultaneously reduces acoustic echo, reverberation and interfering sources. Target speeches are separated from the mixture by maximizing independence with respect to the other sources. It is shown that the separation process can be decomposed into cascading sub-processes that separately relate to acoustic echo cancellation, speech dereverberation and source separation, all of which are solved using the auxiliary function based independent component/vector analysis techniques, and their solving orders are exchangeable. The cascaded solution not only leads to lower computational complexity but also better separation performance than the vanilla joint algorithm.
Weighted Recursive Least Square Filter and Neural Network based Residual Echo Suppression for the AEC-Challenge
Feb 18, 2021
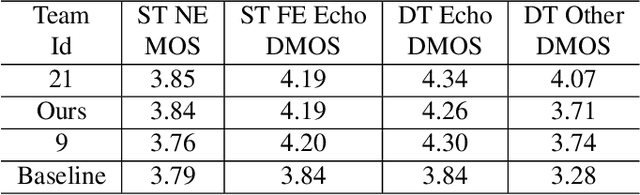
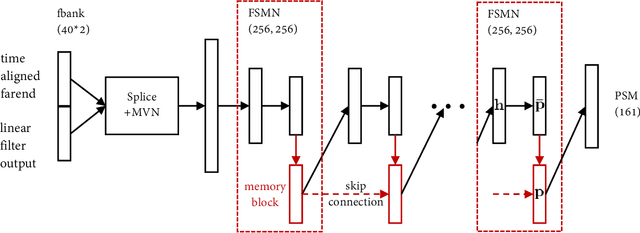

This paper presents a real-time Acoustic Echo Cancellation (AEC) algorithm submitted to the AEC-Challenge. The algorithm consists of three modules: Generalized Cross-Correlation with PHAse Transform (GCC-PHAT) based time delay compensation, weighted Recursive Least Square (wRLS) based linear adaptive filtering and neural network based residual echo suppression. The wRLS filter is derived from a novel semi-blind source separation perspective. The neural network model predicts a Phase-Sensitive Mask (PSM) based on the aligned reference and the linear filter output. The algorithm achieved a mean subjective score of 4.00 and ranked 2nd in the AEC-Challenge.