 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Multichannel Speech Dereverberation based on Deep Neural Networks
Paper and Code
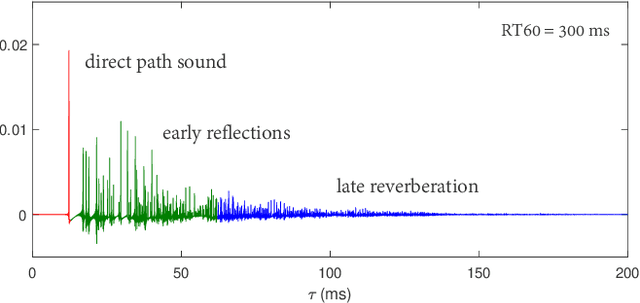
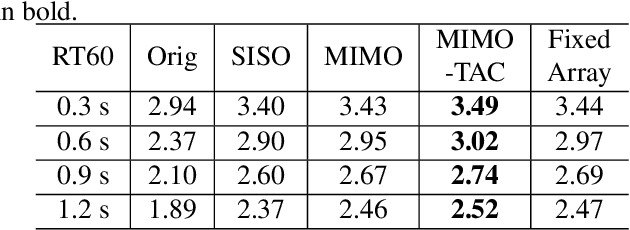
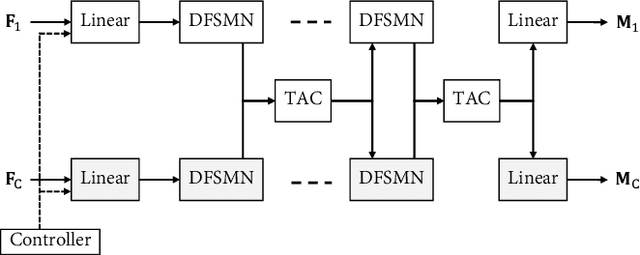
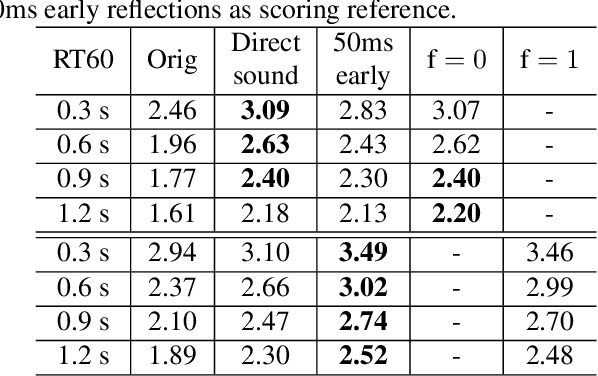
Neural network based speech dereverberation has achieved promising results in recent studies. Nevertheless, many are focused on recovery of only the direct path sound and early reflections, which could be beneficial to speech perception, are discarded. The performance of a model trained to recover clean speech degrades when evaluated on early reverberation targets, and vice versa. This paper proposes a novel deep neural network based multichannel speech dereverberation algorithm, in which the dereverberation level is controllable. This is realized by adding a simple floating-point number as target controller of the model. Experiments are conducted using spatially distributed microphones, and the efficacy of the proposed algorithm is confirmed in various simulated conditions.