 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe TEA-ASLP System for Multilingual Conversational Speech Recognition and Speech Diarization in MLC-SLM 2025 Challenge
Jul 24, 2025This paper presents the TEA-ASLP's system submitted to the MLC-SLM 2025 Challenge, addressing multilingual conversational automatic speech recognition (ASR) in Task I and speech diarization ASR in Task II. For Task I, we enhance Ideal-LLM model by integrating known language identification and a multilingual MOE LoRA structure, along with using CTC-predicted tokens as prompts to improve autoregressive generation. The model is trained on approximately 180k hours of multilingual ASR data. In Task II, we replace the baseline English-Chinese speaker diarization model with a more suitable English-only version. Our approach achieves a 30.8% reduction in word error rate (WER) compared to the baseline speech language model, resulting in a final WER of 9.60% in Task I and a time-constrained minimum-permutation WER of 17.49% in Task II, earning first and second place in the respective challenge tasks.
Chain of Correction for Full-text Speech Recognition with Large Language Models
Apr 02, 2025Full-text error correction with Large Language Models (LLMs) for Automatic Speech Recognition (ASR) has gained increased attention due to its potential to correct errors across long contexts and address a broader spectrum of error types, including punctuation restoration and inverse text normalization. Nevertheless, many challenges persist, including issues related to stability, controllability, completeness, and fluency. To mitigate these challenges, this paper proposes the Chain of Correction (CoC) for full-text error correction with LLMs, which corrects errors segment by segment using pre-recognized text as guidance within a regular multi-turn chat format. The CoC also uses pre-recognized full text for context, allowing the model to better grasp global semantics and maintain a comprehensive overview of the entire content. Utilizing the open-sourced full-text error correction dataset ChFT, we fine-tune a pre-trained LLM to evaluate the performance of the CoC framework. Experimental results demonstrate that the CoC effectively corrects errors in full-text ASR outputs, significantly outperforming baseline and benchmark systems. We further analyze how to set the correction threshold to balance under-correction and over-rephrasing, extrapolate the CoC model on extremely long ASR outputs, and investigate whether other types of information can be employed to guide the error correction process.
Full-text Error Correction for Chinese Speech Recognition with Large Language Model
Sep 12, 2024



Large Language Models (LLMs) have demonstrated substantial potential for error correction in Automatic Speech Recognition (ASR). However, most research focuses on utterances from short-duration speech recordings, which are the predominant form of speech data for supervised ASR training. This paper investigates the effectiveness of LLMs for error correction in full-text generated by ASR systems from longer speech recordings, such as transcripts from podcasts, news broadcasts, and meetings. First, we develop a Chinese dataset for full-text error correction, named ChFT, utilizing a pipeline that involves text-to-speech synthesis, ASR, and error-correction pair extractor. This dataset enables us to correct errors across contexts, including both full-text and segment, and to address a broader range of error types, such as punctuation restoration and inverse text normalization, thus making the correction process comprehensive. Second, we fine-tune a pre-trained LLM on the constructed dataset using a diverse set of prompts and target formats, and evaluate its performance on full-text error correction. Specifically, we design prompts based on full-text and segment, considering various output formats, such as directly corrected text and JSON-based error-correction pairs. Through various test settings, including homogeneous, up-to-date, and hard test sets, we find that the fine-tuned LLMs perform well in the full-text setting with different prompts, each presenting its own strengths and weaknesses. This establishes a promising baseline for further research. The dataset is available on the website.
Pinyin Regularization in Error Correction for Chinese Speech Recognition with Large Language Models
Jul 02, 2024Recent studies have demonstrated the efficacy of large language models (LLMs) in error correction for automatic speech recognition (ASR). However, much of the research focuses on the English language. This paper redirects the attention to Chinese. Firstly, we construct a specialized benchmark dataset aimed at error correction for Chinese ASR with 724K hypotheses-transcription pairs, named the Chinese Hypotheses Paradise dataset (ChineseHP), which contains a wide range of scenarios and presents significant challenges. Subsequently, we conduct a preliminary evaluation using the dataset for both direct-prompting and fine-tuning pre-trained LLMs. Furthermore, we propose a straightforward method of Pinyin regularization for prompts, which involves the transcription of Pinyin directly from text hypotheses. The experimental results reveal that Pinyin regularization consistently enhances the error-correcting ability of LLMs when compared with those without regularization. The dataset is available on the website.
A High Fidelity and Low Complexity Neural Audio Coding
Oct 17, 2023Audio coding is an essential module in the real-time communication system. Neural audio codecs can compress audio samples with a low bitrate due to the strong modeling and generative capabilities of deep neural networks. To address the poor high-frequency expression and high computational cost and storage consumption, we proposed an integrated framework that utilizes a neural network to model wide-band components and adopts traditional signal processing to compress high-band components according to psychological hearing knowledge. Inspired by auditory perception theory, a perception-based loss function is designed to improve harmonic modeling. Besides, generative adversarial network (GAN) compression is proposed for the first time for neural audio codecs. Our method is superior to prior advanced neural codecs across subjective and objective metrics and allows real-time inference on desktop and mobile.
Inter-SubNet: Speech Enhancement with Subband Interaction
May 09, 2023



Subband-based approaches process subbands in parallel through the model with shared parameters to learn the commonality of local spectrums for noise reduction. In this way, they have achieved remarkable results with fewer parameters. However, in some complex environments, the lack of global spectral information has a negative impact on the performance of these subband-based approaches. To this end, this paper introduces the subband interaction as a new way to complement the subband model with the global spectral information such as cross-band dependencies and global spectral patterns, and proposes a new lightweight single-channel speech enhancement framework called Interactive Subband Network (Inter-SubNet). Experimental results on DNS Challenge - Interspeech 2021 dataset show that the proposed Inter-SubNet yields a significant improvement over the subband model and outperforms other state-of-the-art speech enhancement approaches, which demonstrate the effectiveness of subband interaction.
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhancement System For ICASSP 2023 DNS Challenge
Mar 14, 2023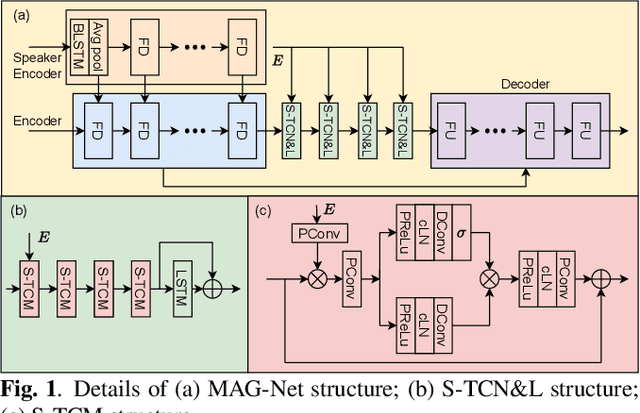


This paper introduces the Unbeatable Team's submission to the ICASSP 2023 Deep Noise Suppression (DNS) Challenge. We expand our previous work, TEA-PSE, to its upgraded version -- TEA-PSE 3.0. Specifically, TEA-PSE 3.0 incorporates a residual LSTM after squeezed temporal convolution network (S-TCN) to enhance sequence modeling capabilities. Additionally, the local-global representation (LGR) structure is introduced to boost speaker information extraction, and multi-STFT resolution loss is used to effectively capture the time-frequency characteristics of the speech signals. Moreover, retraining methods are employed based on the freeze training strategy to fine-tune the system. According to the official results, TEA-PSE 3.0 ranks 1st in both ICASSP 2023 DNS-Challenge track 1 and track 2.
Speech Enhancement with Fullband-Subband Cross-Attention Network
Nov 10, 2022FullSubNet has shown its promising performance on speech enhancement by utilizing both fullband and subband information. However, the relationship between fullband and subband in FullSubNet is achieved by simply concatenating the output of fullband model and subband units. It only supplements the subband units with a small quantity of global information and has not considered the interaction between fullband and subband. This paper proposes a fullband-subband cross-attention (FSCA) module to interactively fuse the global and local information and applies it to FullSubNet. This new framework is called as FS-CANet. Moreover, different from FullSubNet, the proposed FS-CANet optimize the fullband extractor by temporal convolutional network (TCN) blocks to further reduce the model size. Experimental results on DNS Challenge - Interspeech 2021 dataset show that the proposed FS-CANet outperforms other state-of-the-art speech enhancement approaches, and demonstrate the effectiveness of fullband-subband cross-attention.
Local-global speaker representation for target speaker extraction
Oct 28, 2022



Target speaker extraction is to extract the target speaker's voice from a mixture of signals according to the given enrollment utterance. The target speaker's enrollment utterance is also called as anchor speech. The effective utilization of anchor speech is crucial for speaker extraction. In this study, we propose a new system to exploit speaker information from anchor speech fully. Unlike models that use only local or global features of the anchor, the proposed method extracts speaker information on global and local levels and feeds the features into a speech separation network. Our approach benefits from the complementary advantages of both global and local features, and the performance of speaker extraction is improved. We verified the feasibility of this local-global representation (LGR) method using multiple speaker extraction models. Systematic experiments were conducted on the open-source dataset Libri-2talker, and the results showed that the proposed method significantly outperformed the baseline models.
Speech Enhancement with Intelligent Neural Homomorphic Synthesis
Oct 28, 2022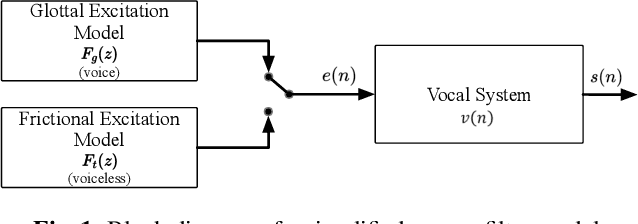
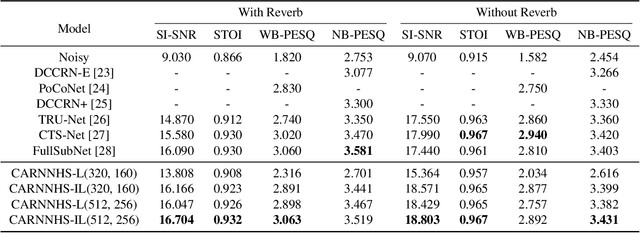

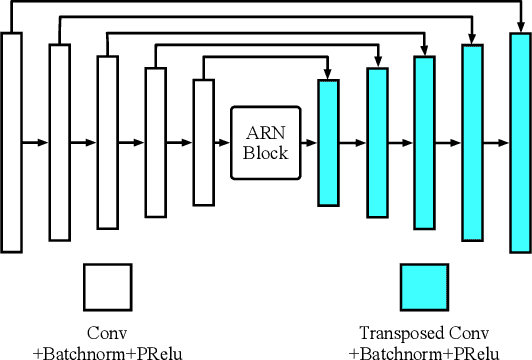
Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.