 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatch Made with Matrix Completion: Efficient Learning under Matching Interference
Jan 11, 2026Matching markets face increasing needs to learn the matching qualities between demand and supply for effective design of matching policies. In practice, the matching rewards are high-dimensional due to the growing diversity of participants. We leverage a natural low-rank matrix structure of the matching rewards in these two-sided markets, and propose to utilize matrix completion to accelerate reward learning with limited offline data. A unique property for matrix completion in this setting is that the entries of the reward matrix are observed with matching interference -- i.e., the entries are not observed independently but dependently due to matching or budget constraints. Such matching dependence renders unique technical challenges, such as sub-optimality or inapplicability of the existing analytical tools in the matrix completion literature, since they typically rely on sample independence. In this paper, we first show that standard nuclear norm regularization remains theoretically effective under matching interference. We provide a near-optimal Frobenius norm guarantee in this setting, coupled with a new analytical technique. Next, to guide certain matching decisions, we develop a novel ``double-enhanced'' estimator, based off the nuclear norm estimator, with a near-optimal entry-wise guarantee. Our double-enhancement procedure can apply to broader sampling schemes even with dependence, which may be of independent interest. Additionally, we extend our approach to online learning settings with matching constraints such as optimal matching and stable matching, and present improved regret bounds in matrix dimensions. Finally, we demonstrate the practical value of our methods using both synthetic data and real data of labor markets.
Cross-Modal Knowledge Distillation for Speech Large Language Models
Sep 18, 2025In this work, we present the first systematic evaluation of catastrophic forgetting and modality inequivalence in speech large language models, showing that introducing speech capabilities can degrade knowledge and reasoning even when inputs remain textual, and performance further decreases with spoken queries. To address these challenges, we propose a cross-modal knowledge distillation framework that leverages both text-to-text and speech-to-text channels to transfer knowledge from a text-based teacher model to a speech LLM. Extensive experiments on dialogue and audio understanding tasks validate the effectiveness of our approach in preserving textual knowledge, improving cross-modal alignment, and enhancing reasoning in speech-based interactions.
Chain of Correction for Full-text Speech Recognition with Large Language Models
Apr 02, 2025Full-text error correction with Large Language Models (LLMs) for Automatic Speech Recognition (ASR) has gained increased attention due to its potential to correct errors across long contexts and address a broader spectrum of error types, including punctuation restoration and inverse text normalization. Nevertheless, many challenges persist, including issues related to stability, controllability, completeness, and fluency. To mitigate these challenges, this paper proposes the Chain of Correction (CoC) for full-text error correction with LLMs, which corrects errors segment by segment using pre-recognized text as guidance within a regular multi-turn chat format. The CoC also uses pre-recognized full text for context, allowing the model to better grasp global semantics and maintain a comprehensive overview of the entire content. Utilizing the open-sourced full-text error correction dataset ChFT, we fine-tune a pre-trained LLM to evaluate the performance of the CoC framework. Experimental results demonstrate that the CoC effectively corrects errors in full-text ASR outputs, significantly outperforming baseline and benchmark systems. We further analyze how to set the correction threshold to balance under-correction and over-rephrasing, extrapolate the CoC model on extremely long ASR outputs, and investigate whether other types of information can be employed to guide the error correction process.
Full-text Error Correction for Chinese Speech Recognition with Large Language Model
Sep 12, 2024



Large Language Models (LLMs) have demonstrated substantial potential for error correction in Automatic Speech Recognition (ASR). However, most research focuses on utterances from short-duration speech recordings, which are the predominant form of speech data for supervised ASR training. This paper investigates the effectiveness of LLMs for error correction in full-text generated by ASR systems from longer speech recordings, such as transcripts from podcasts, news broadcasts, and meetings. First, we develop a Chinese dataset for full-text error correction, named ChFT, utilizing a pipeline that involves text-to-speech synthesis, ASR, and error-correction pair extractor. This dataset enables us to correct errors across contexts, including both full-text and segment, and to address a broader range of error types, such as punctuation restoration and inverse text normalization, thus making the correction process comprehensive. Second, we fine-tune a pre-trained LLM on the constructed dataset using a diverse set of prompts and target formats, and evaluate its performance on full-text error correction. Specifically, we design prompts based on full-text and segment, considering various output formats, such as directly corrected text and JSON-based error-correction pairs. Through various test settings, including homogeneous, up-to-date, and hard test sets, we find that the fine-tuned LLMs perform well in the full-text setting with different prompts, each presenting its own strengths and weaknesses. This establishes a promising baseline for further research. The dataset is available on the website.
Pinyin Regularization in Error Correction for Chinese Speech Recognition with Large Language Models
Jul 02, 2024Recent studies have demonstrated the efficacy of large language models (LLMs) in error correction for automatic speech recognition (ASR). However, much of the research focuses on the English language. This paper redirects the attention to Chinese. Firstly, we construct a specialized benchmark dataset aimed at error correction for Chinese ASR with 724K hypotheses-transcription pairs, named the Chinese Hypotheses Paradise dataset (ChineseHP), which contains a wide range of scenarios and presents significant challenges. Subsequently, we conduct a preliminary evaluation using the dataset for both direct-prompting and fine-tuning pre-trained LLMs. Furthermore, we propose a straightforward method of Pinyin regularization for prompts, which involves the transcription of Pinyin directly from text hypotheses. The experimental results reveal that Pinyin regularization consistently enhances the error-correcting ability of LLMs when compared with those without regularization. The dataset is available on the website.
Semantic Data Augmentation for End-to-End Mandarin Speech Recognition
Apr 26, 2021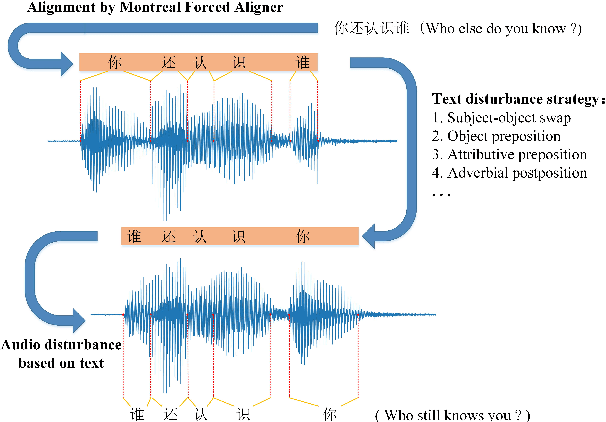


End-to-end models have gradually become the preferred option for automatic speech recognition (ASR) applications. During the training of end-to-end ASR, data augmentation is a quite effective technique for regularizing the neural networks. This paper proposes a novel data augmentation technique based on semantic transposition of the transcriptions via syntax rules for end-to-end Mandarin ASR. Specifically, we first segment the transcriptions based on part-of-speech tags. Then transposition strategies, such as placing the object in front of the subject or swapping the subject and the object, are applied on the segmented sentences. Finally, the acoustic features corresponding to the transposed transcription are reassembled based on the audio-to-text forced-alignment produced by a pre-trained ASR system. The combination of original data and augmented one is used for training a new ASR system. The experiments are conducted on the Transformer[2] and Conformer[3] based ASR. The results show that the proposed method can give consistent performance gain to the system. Augmentation related issues, such as comparison of different strategies and ratios for data combination are also investigated.
Can We Trust Deep Speech Prior?
Nov 04, 2020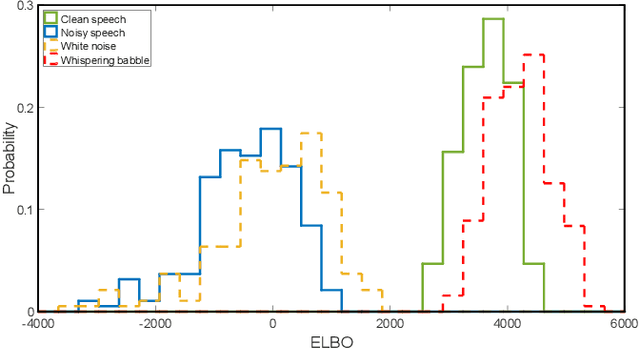
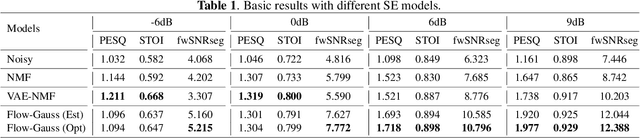
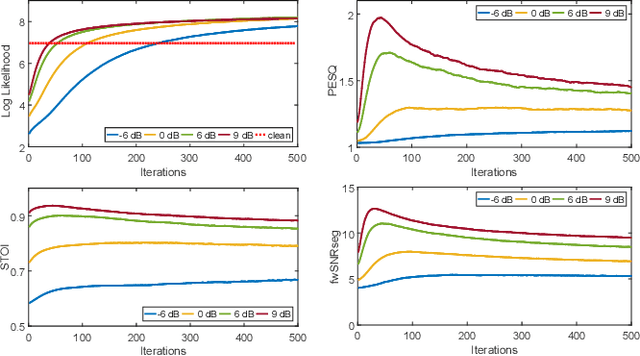
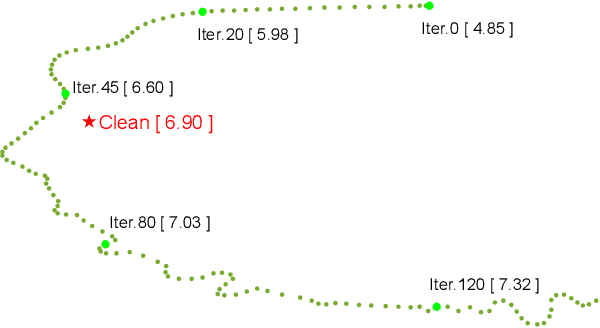
Recently, speech enhancement (SE) based on deep speech prior has attracted much attention, such as the variational auto-encoder with non-negative matrix factorization (VAE-NMF) architecture. Compared to conventional approaches that represent clean speech by shallow models such as Gaussians with a low-rank covariance, the new approach employs deep generative models to represent the clean speech, which often provides a better prior. Despite the clear advantage in theory, we argue that deep priors must be used with much caution, since the likelihood produced by a deep generative model does not always coincide with the speech quality. We designed a comprehensive study on this issue and demonstrated that based on deep speech priors, a reasonable SE performance can be achieved, but the results might be suboptimal. A careful analysis showed that this problem is deeply rooted in the disharmony between the flexibility of deep generative models and the nature of the maximum-likelihood (ML) training.
AP20-OLR Challenge: Three Tasks and Their Baselines
Jun 04, 2020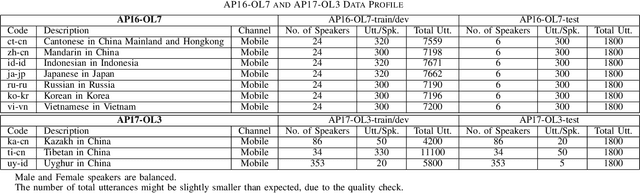
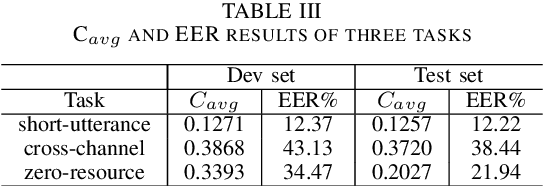
This paper introduces the fifth oriental language recognition (OLR) challenge AP20-OLR, which intends to improve the performance of language recognition systems, along with APSIPA Annual Summit and Conference (APSIPA ASC). The data profile, three tasks, the corresponding baselines, and the evaluation principles are introduced in this paper. The AP20-OLR challenge includes more languages, dialects and real-life data provided by Speechocean and the NSFC M2ASR project, and all the data is free for participants. The challenge this year still focuses on practical and challenging problems, with three tasks: (1) cross-channel LID, (2) dialect identification and (3) noisy LID. Based on Kaldi and Pytorch, recipes for i-vector and x-vector systems are also conducted as baselines for the three tasks. These recipes will be online-published, and available for participants to configure LID systems. The baseline results on the three tasks demonstrate that those tasks in this challenge are worth paying more efforts to achieve better performance.
AP19-OLR Challenge: Three Tasks and Their Baselines
Sep 01, 2019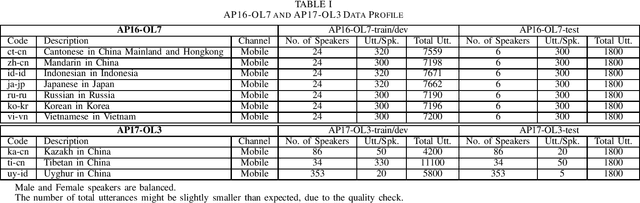
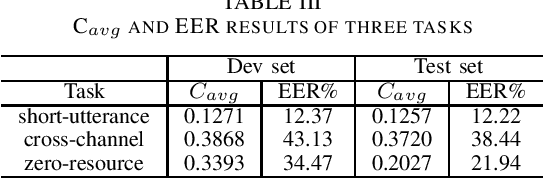
This paper introduces the fourth oriental language recognition (OLR) challenge AP19-OLR, including the data profile, the tasks and the evaluation principles. The OLR challenge has been held successfully for three consecutive years, along with APSIPA Annual Summit and Conference (APSIPA ASC). The challenge this year still focuses on practical and challenging tasks, precisely (1) short-utterance LID, (2) cross-channel LID and (3) zero-resource LID. The event this year includes more languages and more real-life data provided by SpeechOcean and the NSFC M2ASR project. All the data is free for participants. Recipes for x-vector system and back-end evaluation are also conducted as baselines for the three tasks. The participants can refer to these online-published recipes to deploy LID systems for convenience. We report the baseline results on the three tasks and demonstrate that the three tasks are worth some efforts to achieve better performance.
Gaussian-Constrained training for speaker verification
Nov 08, 2018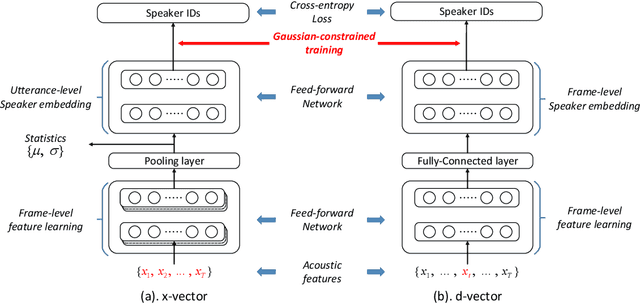
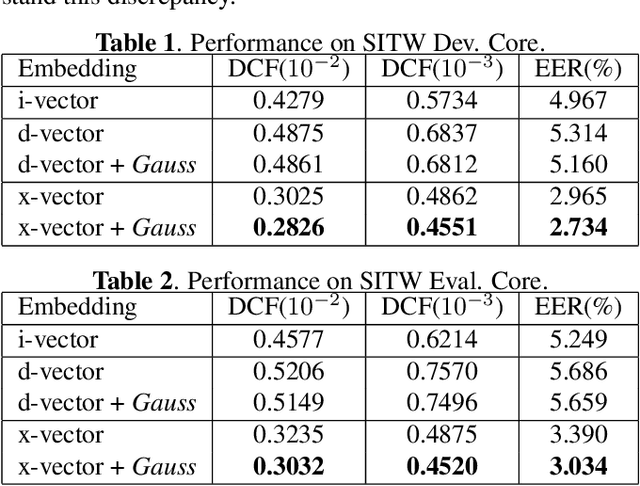
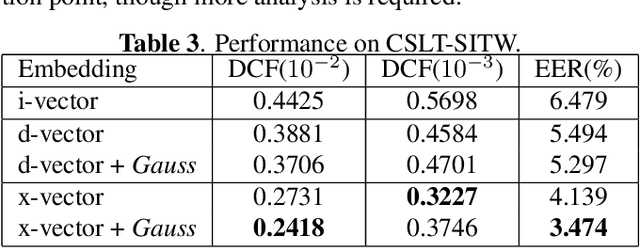
Neural models, in particular the d-vector and x-vector architectures, have produced state-of-the-art performance on many speaker verification tasks. However, two potential problems of these neural models deserve more investigation. Firstly, both models suffer from `information leak', which means that some parameters participating in model training will be discarded during inference, i.e, the layers that are used as the classifier. Secondly, both models do not regulate the distribution of the derived speaker vectors. This `unconstrained distribution' may degrade the performance of the subsequent scoring component, e.g., PLDA. This paper proposes a Gaussian-constrained training approach that (1) discards the parametric classifier, and (2) enforces the distribution of the derived speaker vectors to be Gaussian. Our experiments on the VoxCeleb and SITW databases demonstrated that this new training approach produced more representative and regular speaker embeddings, leading to consistent performance improvement.