 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Input-Output: Rethinking Creativity through Design-by-Analogy in Human-AI Collaboration
Feb 10, 2026While the proliferation of foundation models has significantly boosted individual productivity, it also introduces a potential challenge: the homogenization of creative content. In response, we revisit Design-by-Analogy (DbA), a cognitively grounded approach that fosters novel solutions by mapping inspiration across domains. However, prevailing perspectives often restrict DbA to early ideation or specific data modalities, while reducing AI-driven design to simplified input-output pipelines. Such conceptual limitations inadvertently foster widespread design fixation. To address this, we expand the understanding of DbA by embedding it into the entire creative process, thereby demonstrating its capacity to mitigate such fixation. Through a systematic review of 85 studies, we identify six forms of representation and classify techniques across seven stages of the creative process. We further discuss three major application domains: creative industries, intelligent manufacturing, and education and services, demonstrating DbA's practical relevance. Building on this synthesis, we frame DbA as a mediating technology for human-AI collaboration and outline the potential opportunities and inherent risks for advancing creativity support in HCI and design research.
* 20 pages, 9 figures. Accepted to the 2026 CHI Conference on Human Factors in Computing Systems
PathOrchestra: A Comprehensive Foundation Model for Computational Pathology with Over 100 Diverse Clinical-Grade Tasks
Mar 31, 2025The complexity and variability inherent in high-resolution pathological images present significant challenges in computational pathology. While pathology foundation models leveraging AI have catalyzed transformative advancements, their development demands large-scale datasets, considerable storage capacity, and substantial computational resources. Furthermore, ensuring their clinical applicability and generalizability requires rigorous validation across a broad spectrum of clinical tasks. Here, we present PathOrchestra, a versatile pathology foundation model trained via self-supervised learning on a dataset comprising 300K pathological slides from 20 tissue and organ types across multiple centers. The model was rigorously evaluated on 112 clinical tasks using a combination of 61 private and 51 public datasets. These tasks encompass digital slide preprocessing, pan-cancer classification, lesion identification, multi-cancer subtype classification, biomarker assessment, gene expression prediction, and the generation of structured reports. PathOrchestra demonstrated exceptional performance across 27,755 WSIs and 9,415,729 ROIs, achieving over 0.950 accuracy in 47 tasks, including pan-cancer classification across various organs, lymphoma subtype diagnosis, and bladder cancer screening. Notably, it is the first model to generate structured reports for high-incidence colorectal cancer and diagnostically complex lymphoma-areas that are infrequently addressed by foundational models but hold immense clinical potential. Overall, PathOrchestra exemplifies the feasibility and efficacy of a large-scale, self-supervised pathology foundation model, validated across a broad range of clinical-grade tasks. Its high accuracy and reduced reliance on extensive data annotation underline its potential for clinical integration, offering a pathway toward more efficient and high-quality medical services.
Multi-Level Contrastive Learning for Few-Shot Problems
Jul 15, 2021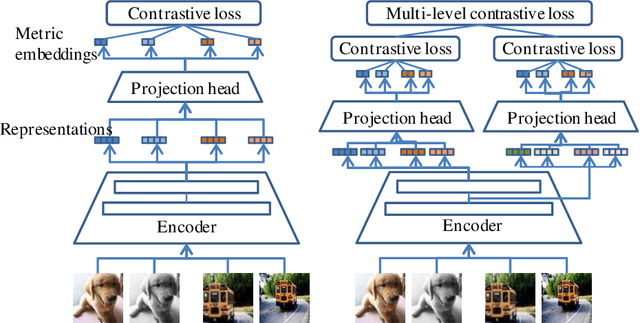
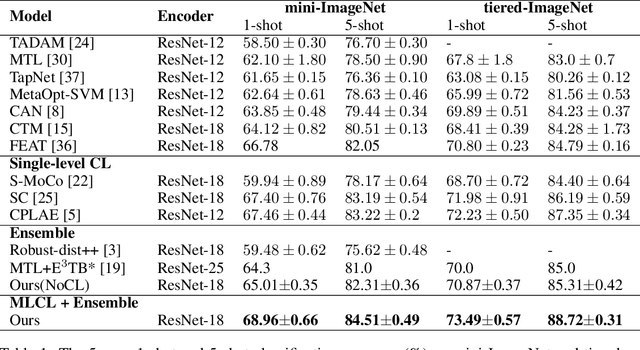
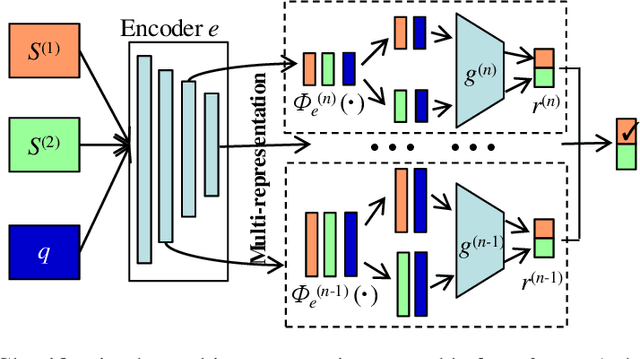
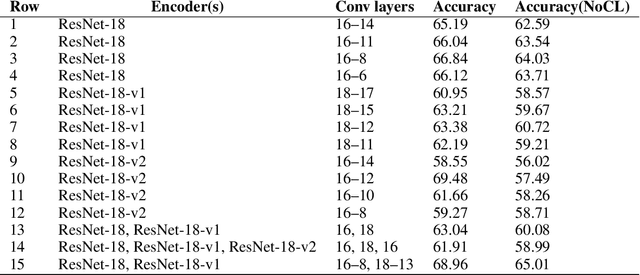
Contrastive learning is a discriminative approach that aims at grouping similar samples closer and diverse samples far from each other. It it an efficient technique to train an encoder generating distinguishable and informative representations, and it may even increase the encoder's transferability. Most current applications of contrastive learning benefit only a single representation from the last layer of an encoder.In this paper, we propose a multi-level contrasitive learning approach which applies contrastive losses at different layers of an encoder to learn multiple representations from the encoder. Afterward, an ensemble can be constructed to take advantage of the multiple representations for the downstream tasks. We evaluated the proposed method on few-shot learning problems and conducted experiments using the mini-ImageNet and the tiered-ImageNet datasets. Our model achieved the new state-of-the-art results for both datasets, comparing to previous regular, ensemble, and contrastive learing (single-level) based approaches.
AP18-OLR Challenge: Three Tasks and Their Baselines
Jun 02, 2018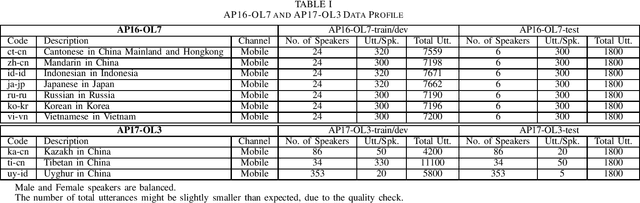
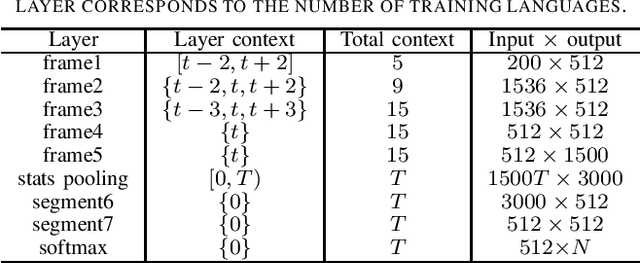
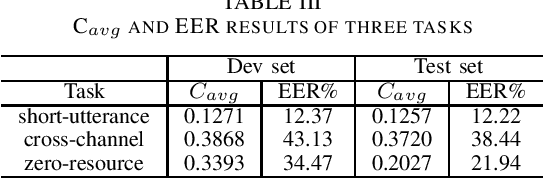
The third oriental language recognition (OLR) challenge AP18-OLR is introduced in this paper, including the data profile, the tasks and the evaluation principles. Following the events in the last two years, namely AP16-OLR and AP17-OLR, the challenge this year focuses on more challenging tasks, including (1) short-duration utterances, (2) confusing languages, and (3) open-set recognition. The same as the previous events, the data of AP18-OLR is also provided by SpeechOcean and the NSFC M2ASR project. Baselines based on both the i-vector model and neural networks are constructed for the participants' reference. We report the baseline results on the three tasks and demonstrate that the three tasks are truly challenging. All the data is free for participants, and the Kaldi recipes for the baselines have been published online.
AP17-OLR Challenge: Data, Plan, and Baseline
Jun 28, 2017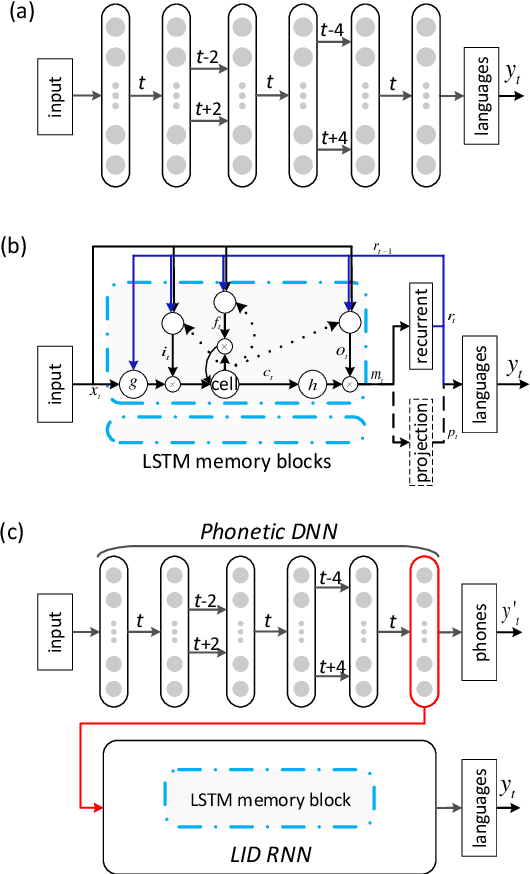



We present the data profile and the evaluation plan of the second oriental language recognition (OLR) challenge AP17-OLR. Compared to the event last year (AP16-OLR), the new challenge involves more languages and focuses more on short utterances. The data is offered by SpeechOcean and the NSFC M2ASR project. Two types of baselines are constructed to assist the participants, one is based on the i-vector model and the other is based on various neural networks. We report the baseline results evaluated with various metrics defined by the AP17-OLR evaluation plan and demonstrate that the combined database is a reasonable data resource for multilingual research. All the data is free for participants, and the Kaldi recipes for the baselines have been published online.
A deep learning approach for predicting the quality of online health expert question-answering services
Dec 21, 2016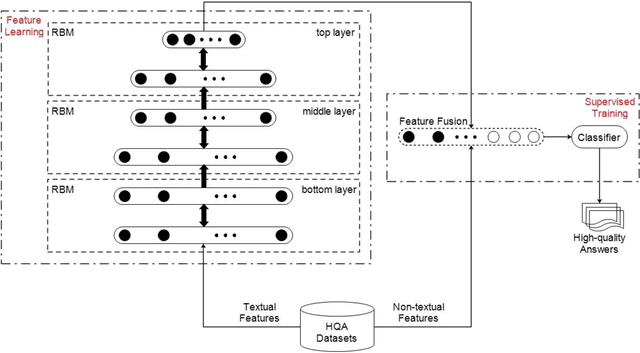
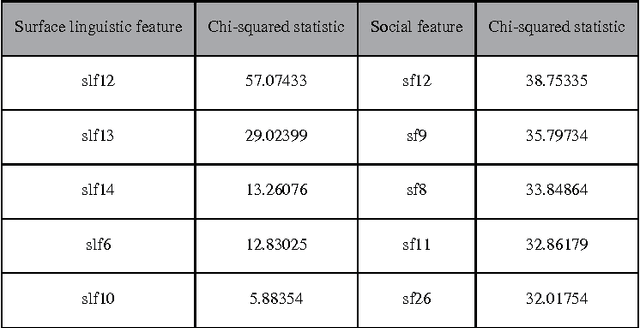
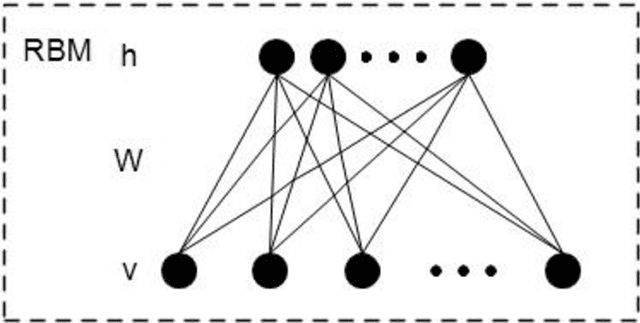
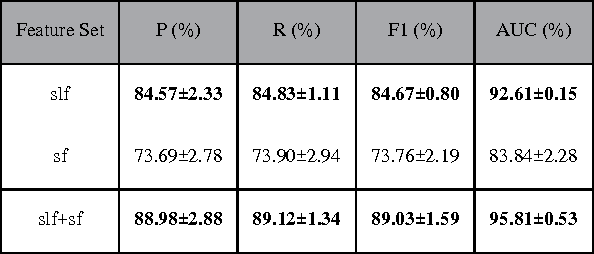
Currently, a growing number of health consumers are asking health-related questions online, at any time and from anywhere, which effectively lowers the cost of health care. The most common approach is using online health expert question-answering (HQA) services, as health consumers are more willing to trust answers from professional physicians. However, these answers can be of varying quality depending on circumstance. In addition, as the available HQA services grow, how to predict the answer quality of HQA services via machine learning becomes increasingly important and challenging. In an HQA service, answers are normally short texts, which are severely affected by the data sparsity problem. Furthermore, HQA services lack community features such as best answer and user votes. Therefore, the wisdom of the crowd is not available to rate answer quality. To address these problems, in this paper, the prediction of HQA answer quality is defined as a classification task. First, based on the characteristics of HQA services and feedback from medical experts, a standard for HQA service answer quality evaluation is defined. Next, based on the characteristics of HQA services, several novel non-textual features are proposed, including surface linguistic features and social features. Finally, a deep belief network (DBN)-based HQA answer quality prediction framework is proposed to predict the quality of answers by learning the high-level hidden semantic representation from the physicians' answers. Our results prove that the proposed framework overcomes the problem of overly sparse textual features in short text answers and effectively identifies high-quality answers.
AP16-OL7: A Multilingual Database for Oriental Languages and A Language Recognition Baseline
Sep 27, 2016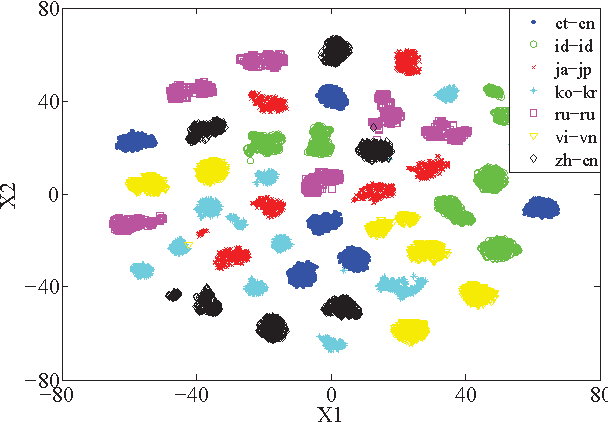
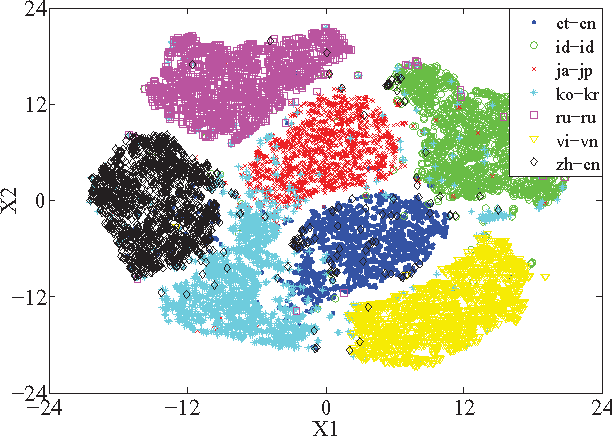
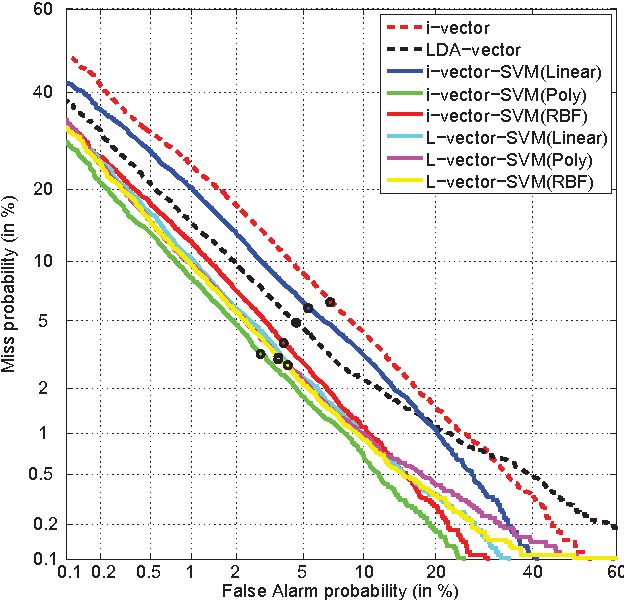
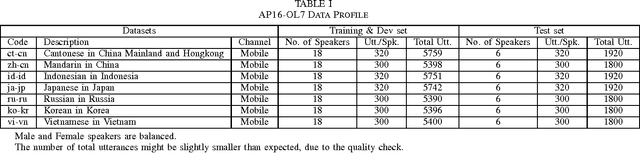
We present the AP16-OL7 database which was released as the training and test data for the oriental language recognition (OLR) challenge on APSIPA 2016. Based on the database, a baseline system was constructed on the basis of the i-vector model. We report the baseline results evaluated in various metrics defined by the AP16-OLR evaluation plan and demonstrate that AP16-OL7 is a reasonable data resource for multilingual research.
OC16-CE80: A Chinese-English Mixlingual Database and A Speech Recognition Baseline
Sep 27, 2016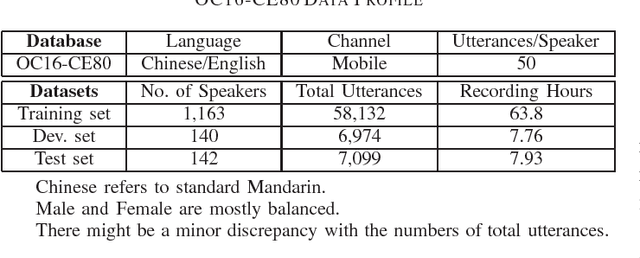
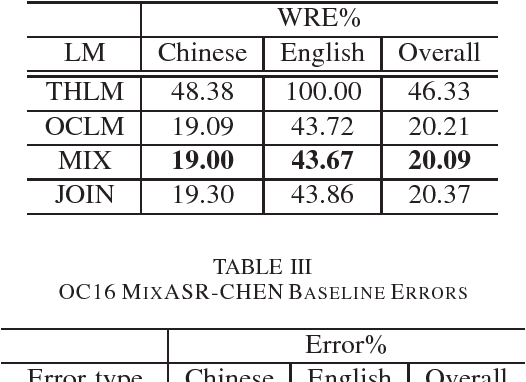
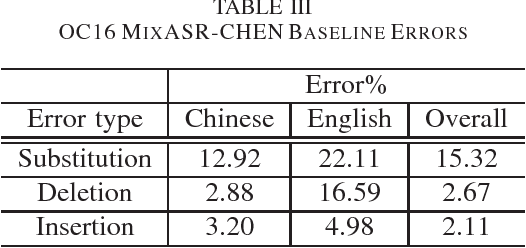
We present the OC16-CE80 Chinese-English mixlingual speech database which was released as a main resource for training, development and test for the Chinese-English mixlingual speech recognition (MixASR-CHEN) challenge on O-COCOSDA 2016. This database consists of 80 hours of speech signals recorded from more than 1,400 speakers, where the utterances are in Chinese but each involves one or several English words. Based on the database and another two free data resources (THCHS30 and the CMU dictionary), a speech recognition (ASR) baseline was constructed with the deep neural network-hidden Markov model (DNN-HMM) hybrid system. We then report the baseline results following the MixASR-CHEN evaluation rules and demonstrate that OC16-CE80 is a reasonable data resource for mixlingual research.