 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP18-OLR Challenge: Three Tasks and Their Baselines
Paper and Code
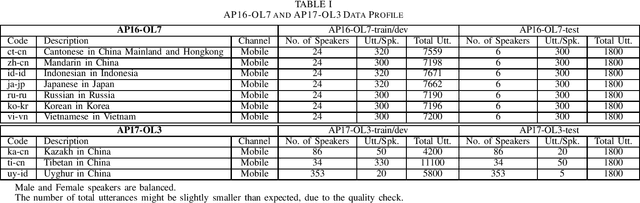
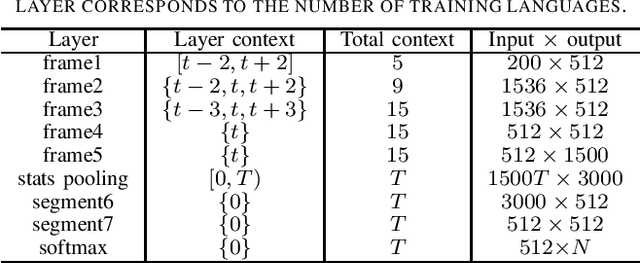
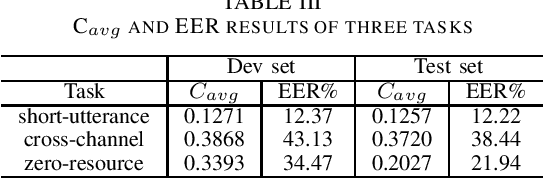
The third oriental language recognition (OLR) challenge AP18-OLR is introduced in this paper, including the data profile, the tasks and the evaluation principles. Following the events in the last two years, namely AP16-OLR and AP17-OLR, the challenge this year focuses on more challenging tasks, including (1) short-duration utterances, (2) confusing languages, and (3) open-set recognition. The same as the previous events, the data of AP18-OLR is also provided by SpeechOcean and the NSFC M2ASR project. Baselines based on both the i-vector model and neural networks are constructed for the participants' reference. We report the baseline results on the three tasks and demonstrate that the three tasks are truly challenging. All the data is free for participants, and the Kaldi recipes for the baselines have been published online.