 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluator for Emotionally Consistent Chatbots
Dec 02, 2021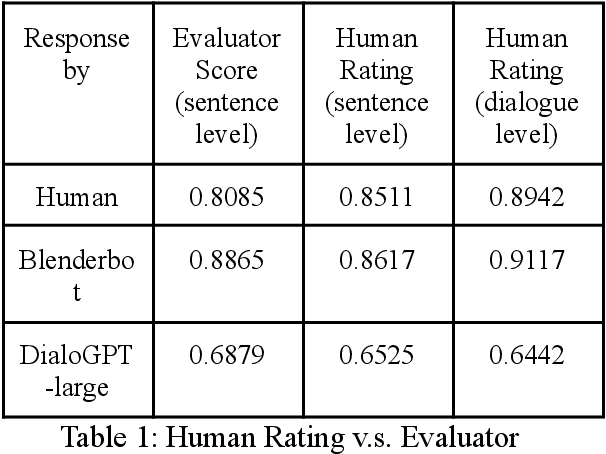
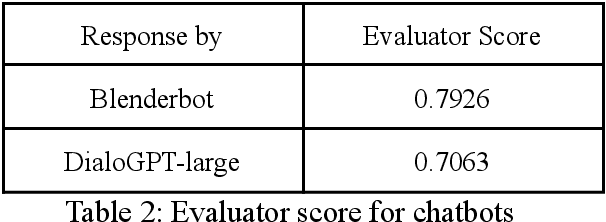

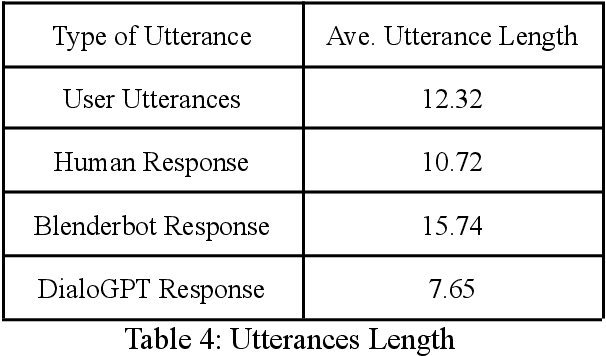
One challenge for evaluating current sequence- or dialogue-level chatbots, such as Empathetic Open-domain Conversation Models, is to determine whether the chatbot performs in an emotionally consistent way. The most recent work only evaluates on the aspects of context coherence, language fluency, response diversity, or logical self-consistency between dialogues. This work proposes training an evaluator to determine the emotional consistency of chatbots.
AP16-OL7: A Multilingual Database for Oriental Languages and A Language Recognition Baseline
Sep 27, 2016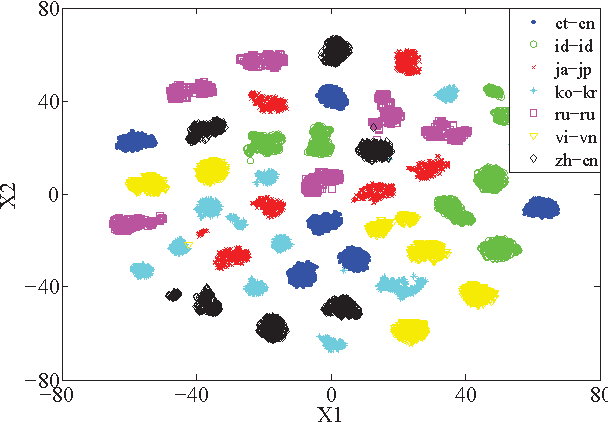
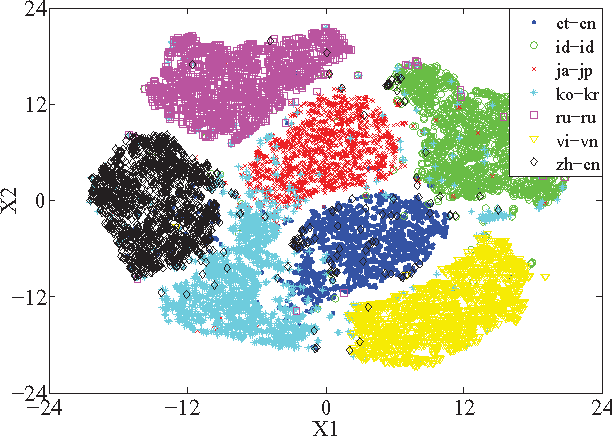
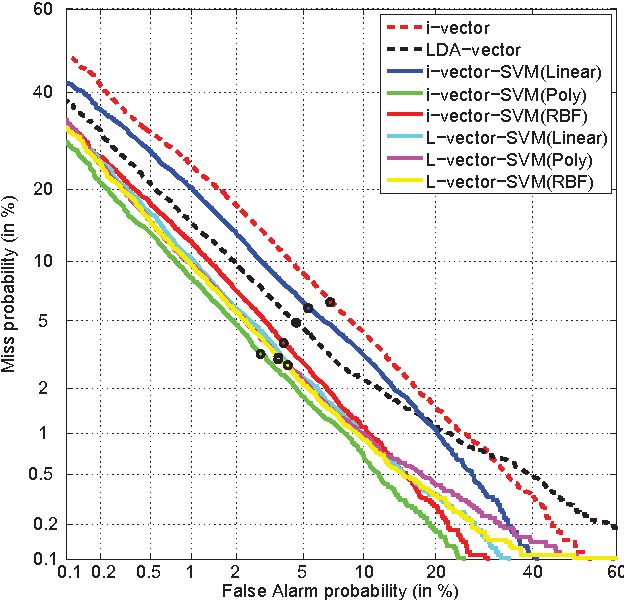
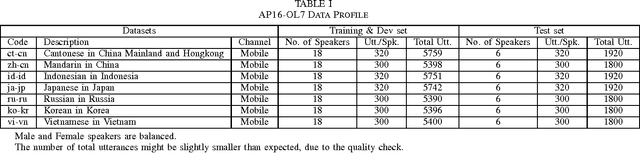
We present the AP16-OL7 database which was released as the training and test data for the oriental language recognition (OLR) challenge on APSIPA 2016. Based on the database, a baseline system was constructed on the basis of the i-vector model. We report the baseline results evaluated in various metrics defined by the AP16-OLR evaluation plan and demonstrate that AP16-OL7 is a reasonable data resource for multilingual research.
OC16-CE80: A Chinese-English Mixlingual Database and A Speech Recognition Baseline
Sep 27, 2016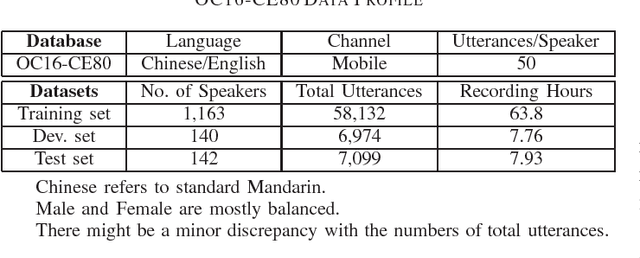
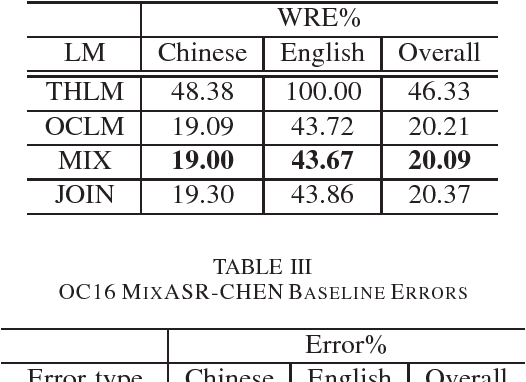
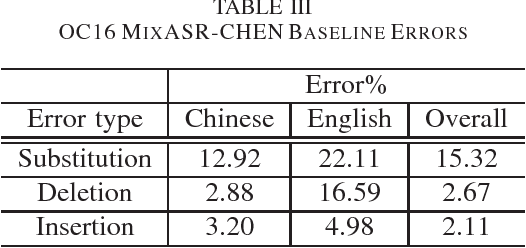
We present the OC16-CE80 Chinese-English mixlingual speech database which was released as a main resource for training, development and test for the Chinese-English mixlingual speech recognition (MixASR-CHEN) challenge on O-COCOSDA 2016. This database consists of 80 hours of speech signals recorded from more than 1,400 speakers, where the utterances are in Chinese but each involves one or several English words. Based on the database and another two free data resources (THCHS30 and the CMU dictionary), a speech recognition (ASR) baseline was constructed with the deep neural network-hidden Markov model (DNN-HMM) hybrid system. We then report the baseline results following the MixASR-CHEN evaluation rules and demonstrate that OC16-CE80 is a reasonable data resource for mixlingual research.