Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP16-OL7: A Multilingual Database for Oriental Languages and A Language Recognition Baseline
Paper and Code
Sep 27, 2016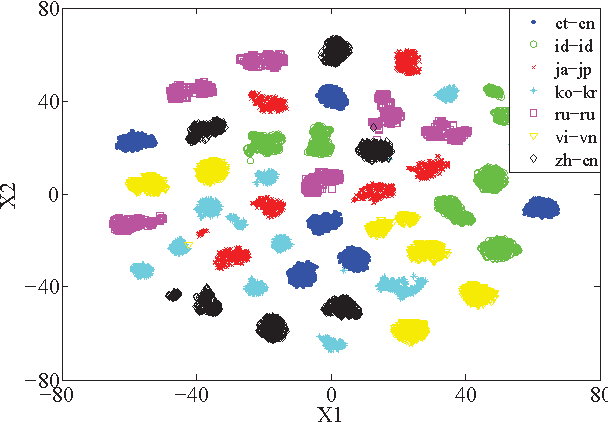
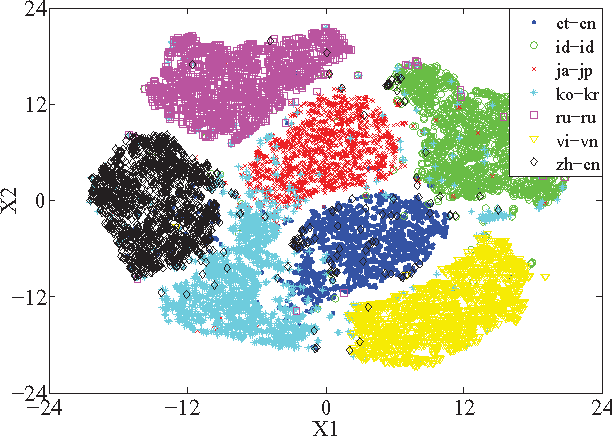
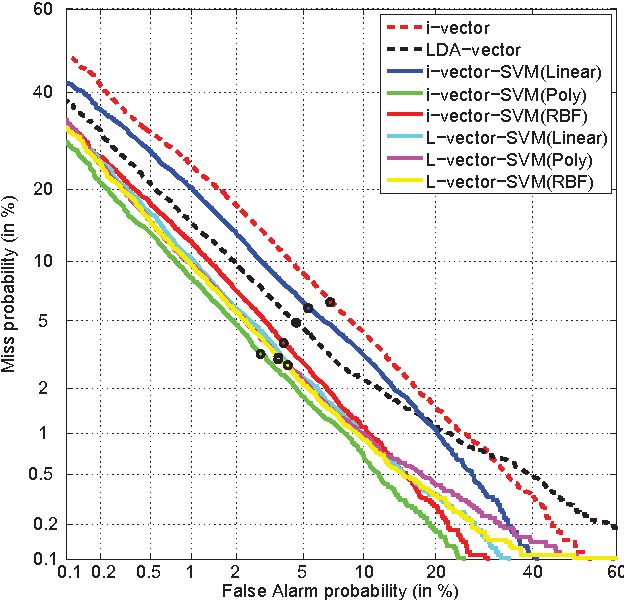
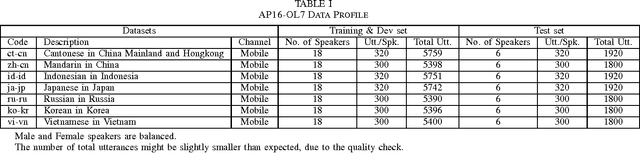
We present the AP16-OL7 database which was released as the training and test data for the oriental language recognition (OLR) challenge on APSIPA 2016. Based on the database, a baseline system was constructed on the basis of the i-vector model. We report the baseline results evaluated in various metrics defined by the AP16-OLR evaluation plan and demonstrate that AP16-OL7 is a reasonable data resource for multilingual research.
* APSIPA ASC 2016
View paper on