 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP20-OLR Challenge: Three Tasks and Their Baselines
Paper and Code
Jun 04, 2020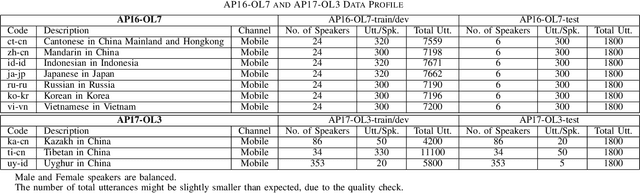
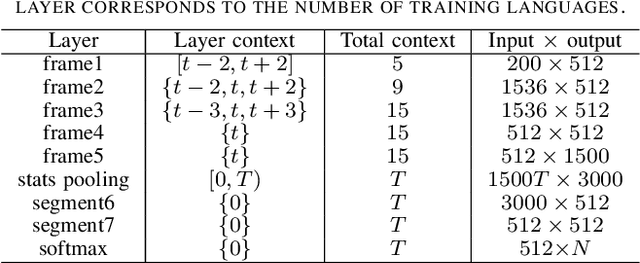
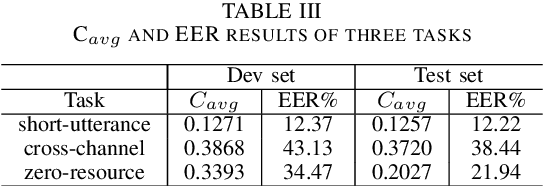
This paper introduces the fifth oriental language recognition (OLR) challenge AP20-OLR, which intends to improve the performance of language recognition systems, along with APSIPA Annual Summit and Conference (APSIPA ASC). The data profile, three tasks, the corresponding baselines, and the evaluation principles are introduced in this paper. The AP20-OLR challenge includes more languages, dialects and real-life data provided by Speechocean and the NSFC M2ASR project, and all the data is free for participants. The challenge this year still focuses on practical and challenging problems, with three tasks: (1) cross-channel LID, (2) dialect identification and (3) noisy LID. Based on Kaldi and Pytorch, recipes for i-vector and x-vector systems are also conducted as baselines for the three tasks. These recipes will be online-published, and available for participants to configure LID systems. The baseline results on the three tasks demonstrate that those tasks in this challenge are worth paying more efforts to achieve better performance.