 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian-Constrained training for speaker verification
Paper and Code
Nov 08, 2018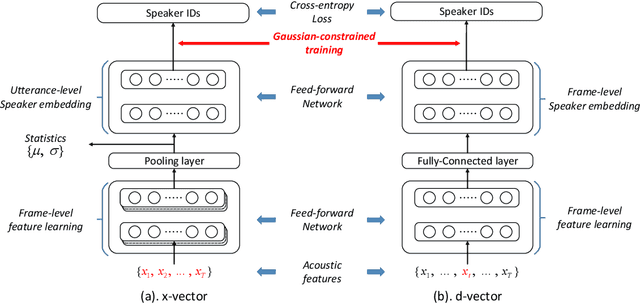
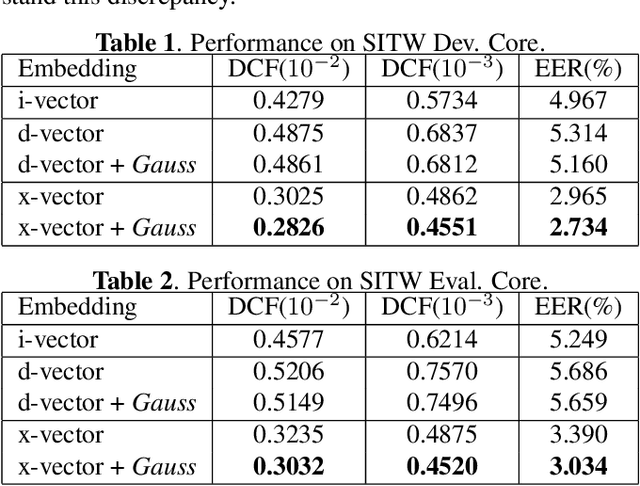
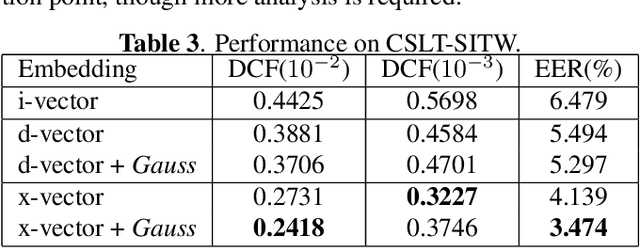
Neural models, in particular the d-vector and x-vector architectures, have produced state-of-the-art performance on many speaker verification tasks. However, two potential problems of these neural models deserve more investigation. Firstly, both models suffer from `information leak', which means that some parameters participating in model training will be discarded during inference, i.e, the layers that are used as the classifier. Secondly, both models do not regulate the distribution of the derived speaker vectors. This `unconstrained distribution' may degrade the performance of the subsequent scoring component, e.g., PLDA. This paper proposes a Gaussian-constrained training approach that (1) discards the parametric classifier, and (2) enforces the distribution of the derived speaker vectors to be Gaussian. Our experiments on the VoxCeleb and SITW databases demonstrated that this new training approach produced more representative and regular speaker embeddings, leading to consistent performance improvement.