 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Stochastic Object Models from Noisy Data via Ambient Measurement-Integrated Diffusion
Dec 16, 2025Task-based measures of image quality (IQ) are critical for evaluating medical imaging systems, which must account for randomness including anatomical variability. Stochastic object models (SOMs) provide a statistical description of such variability, but conventional mathematical SOMs fail to capture realistic anatomy, while data-driven approaches typically require clean data rarely available in clinical tasks. To address this challenge, we propose AMID, an unsupervised Ambient Measurement-Integrated Diffusion with noise decoupling, which establishes clean SOMs directly from noisy measurements. AMID introduces a measurement-integrated strategy aligning measurement noise with the diffusion trajectory, and explicitly models coupling between measurement and diffusion noise across steps, an ambient loss is thus designed base on it to learn clean SOMs. Experiments on real CT and mammography datasets show that AMID outperforms existing methods in generation fidelity and yields more reliable task-based IQ evaluation, demonstrating its potential for unsupervised medical imaging analysis.
A Multi-Agent System for Information Extraction from the Chemical Literature
Jul 27, 2025To fully expedite AI-powered chemical research, high-quality chemical databases are the cornerstone. Automatic extraction of chemical information from the literature is essential for constructing reaction databases, but it is currently limited by the multimodality and style variability of chemical information. In this work, we developed a multimodal large language model (MLLM)-based multi-agent system for automatic chemical information extraction. We used the MLLM's strong reasoning capability to understand the structure of complex chemical graphics, decompose the extraction task into sub-tasks and coordinate a set of specialized agents to solve them. Our system achieved an F1 score of 80.8% on a benchmark dataset of complex chemical reaction graphics from the literature, surpassing the previous state-of-the-art model (F1 score: 35.6%) by a significant margin. Additionally, it demonstrated consistent improvements in key sub-tasks, including molecular image recognition, reaction image parsing, named entity recognition and text-based reaction extraction. This work is a critical step toward automated chemical information extraction into structured datasets, which will be a strong promoter of AI-driven chemical research.
Towards Large-scale Chemical Reaction Image Parsing via a Multimodal Large Language Model
Mar 11, 2025Artificial intelligence (AI) has demonstrated significant promise in advancing organic chemistry research; however, its effectiveness depends on the availability of high-quality chemical reaction data. Currently, most published chemical reactions are not available in machine-readable form, limiting the broader application of AI in this field. The extraction of published chemical reactions into structured databases still relies heavily on manual curation, and robust automatic parsing of chemical reaction images into machine-readable data remains a significant challenge. To address this, we introduce the Reaction Image Multimodal large language model (RxnIM), the first multimodal large language model specifically designed to parse chemical reaction images into machine-readable reaction data. RxnIM not only extracts key chemical components from reaction images but also interprets the textual content that describes reaction conditions. Together with specially designed large-scale dataset generation method to support model training, our approach achieves excellent performance, with an average F1 score of 88% on various benchmarks, surpassing literature methods by 5%. This represents a crucial step toward the automatic construction of large databases of machine-readable reaction data parsed from images in the chemistry literature, providing essential data resources for AI research in chemistry. The source code, model checkpoints, and datasets developed in this work are released under permissive licenses. An instance of the RxnIM web application can be accessed at https://huggingface.co/spaces/CYF200127/RxnIM.
Dial-insight: Fine-tuning Large Language Models with High-Quality Domain-Specific Data Preventing Capability Collapse
Mar 14, 2024The efficacy of large language models (LLMs) is heavily dependent on the quality of the underlying data, particularly within specialized domains. A common challenge when fine-tuning LLMs for domain-specific applications is the potential degradation of the model's generalization capabilities. To address these issues, we propose a two-stage approach for the construction of production prompts designed to yield high-quality data. This method involves the generation of a diverse array of prompts that encompass a broad spectrum of tasks and exhibit a rich variety of expressions. Furthermore, we introduce a cost-effective, multi-dimensional quality assessment framework to ensure the integrity of the generated labeling data. Utilizing a dataset comprised of service provider and customer interactions from the real estate sector, we demonstrate a positive correlation between data quality and model performance. Notably, our findings indicate that the domain-specific proficiency of general LLMs can be enhanced through fine-tuning with data produced via our proposed method, without compromising their overall generalization abilities, even when exclusively domain-specific data is employed for fine-tuning.
MolNexTR: A Generalized Deep Learning Model for Molecular Image Recognition
Mar 08, 2024

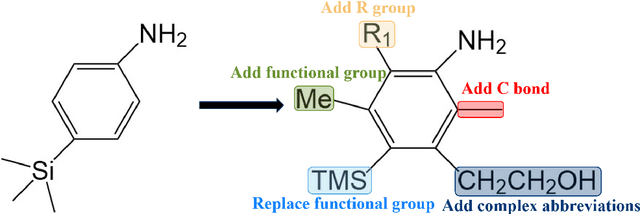
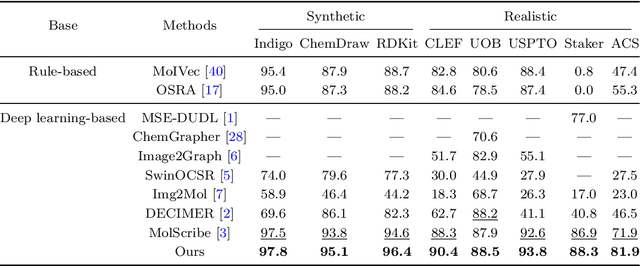
In the field of chemical structure recognition, the task of converting molecular images into graph structures and SMILES string stands as a significant challenge, primarily due to the varied drawing styles and conventions prevalent in chemical literature. To bridge this gap, we proposed MolNexTR, a novel image-to-graph deep learning model that collaborates to fuse the strengths of ConvNext, a powerful Convolutional Neural Network variant, and Vision-TRansformer. This integration facilitates a more nuanced extraction of both local and global features from molecular images. MolNexTR can predict atoms and bonds simultaneously and understand their layout rules. It also excels at flexibly integrating symbolic chemistry principles to discern chirality and decipher abbreviated structures. We further incorporate a series of advanced algorithms, including improved data augmentation module, image contamination module, and a post-processing module to get the final SMILES output. These modules synergistically enhance the model's robustness against the diverse styles of molecular imagery found in real literature. In our test sets, MolNexTR has demonstrated superior performance, achieving an accuracy rate of 81-97%, marking a significant advancement in the domain of molecular structure recognition. Scientific contribution: MolNexTR is a novel image-to-graph model that incorporates a unique dual-stream encoder to extract complex molecular image features, and combines chemical rules to predict atoms and bonds while understanding atom and bond layout rules. In addition, it employs a series of novel augmentation algorithms to significantly enhance the robustness and performance of the model.
Audio-Visual Wake Word Spotting System For MISP Challenge 2021
Apr 20, 2022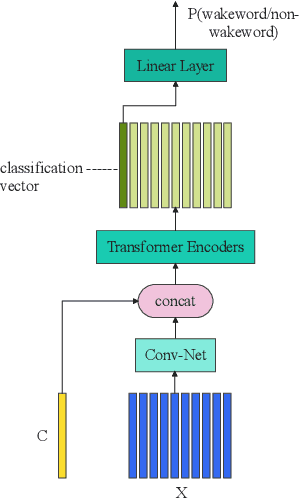
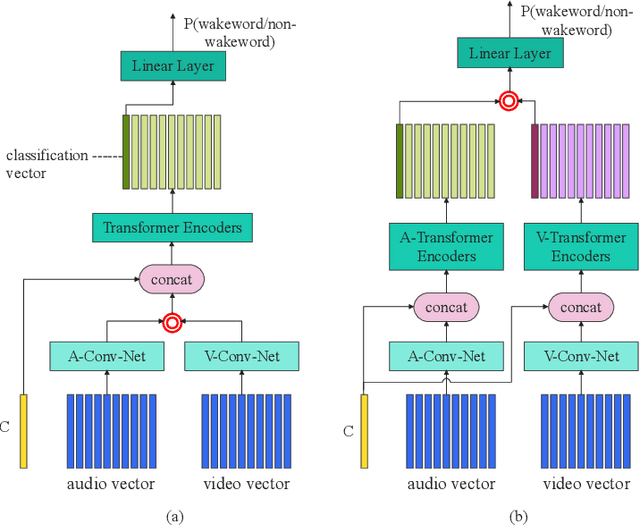

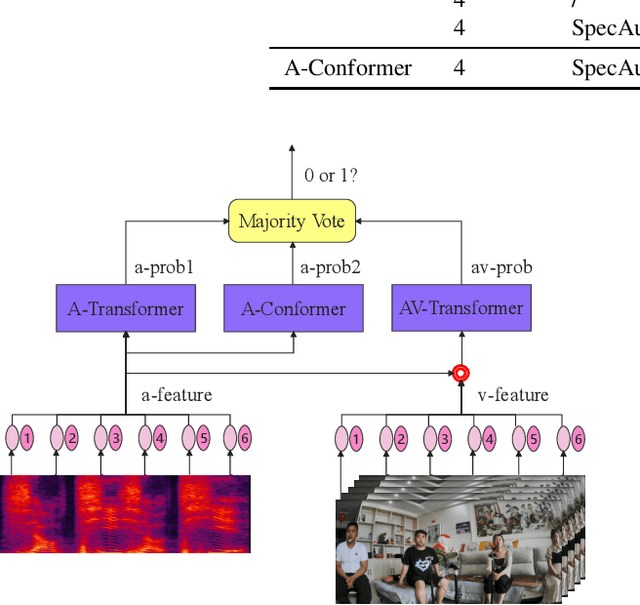
This paper presents the details of our system designed for the Task 1 of Multimodal Information Based Speech Processing (MISP) Challenge 2021. The purpose of Task 1 is to leverage both audio and video information to improve the environmental robustness of far-field wake word spotting. In the proposed system, firstly, we take advantage of speech enhancement algorithms such as beamforming and weighted prediction error (WPE) to address the multi-microphone conversational audio. Secondly, several data augmentation techniques are applied to simulate a more realistic far-field scenario. For the video information, the provided region of interest (ROI) is used to obtain visual representation. Then the multi-layer CNN is proposed to learn audio and visual representations, and these representations are fed into our two-branch attention-based network which can be employed for fusion, such as transformer and conformed. The focal loss is used to fine-tune the model and improve the performance significantly. Finally, multiple trained models are integrated by casting vote to achieve our final 0.091 score.
Semantic Data Augmentation for End-to-End Mandarin Speech Recognition
Apr 26, 2021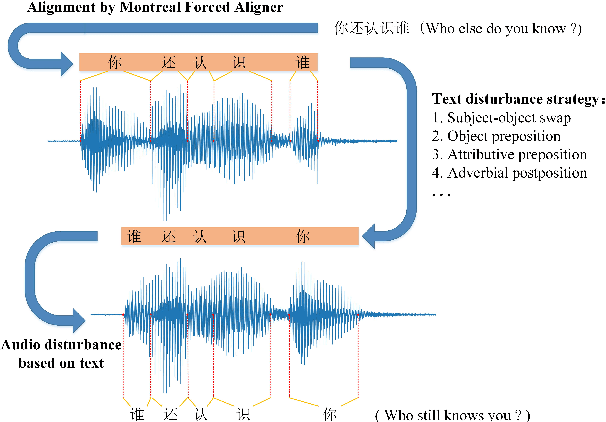


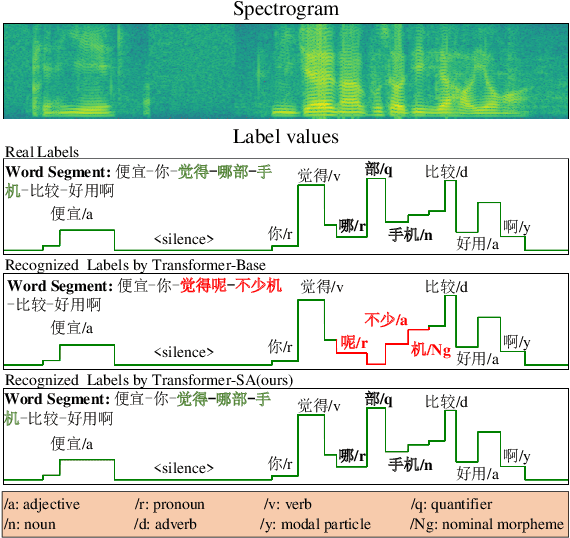
End-to-end models have gradually become the preferred option for automatic speech recognition (ASR) applications. During the training of end-to-end ASR, data augmentation is a quite effective technique for regularizing the neural networks. This paper proposes a novel data augmentation technique based on semantic transposition of the transcriptions via syntax rules for end-to-end Mandarin ASR. Specifically, we first segment the transcriptions based on part-of-speech tags. Then transposition strategies, such as placing the object in front of the subject or swapping the subject and the object, are applied on the segmented sentences. Finally, the acoustic features corresponding to the transposed transcription are reassembled based on the audio-to-text forced-alignment produced by a pre-trained ASR system. The combination of original data and augmented one is used for training a new ASR system. The experiments are conducted on the Transformer[2] and Conformer[3] based ASR. The results show that the proposed method can give consistent performance gain to the system. Augmentation related issues, such as comparison of different strategies and ratios for data combination are also investigated.