 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Wake Word Spotting System For MISP Challenge 2021
Apr 20, 2022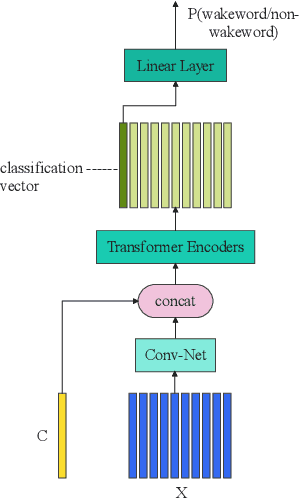
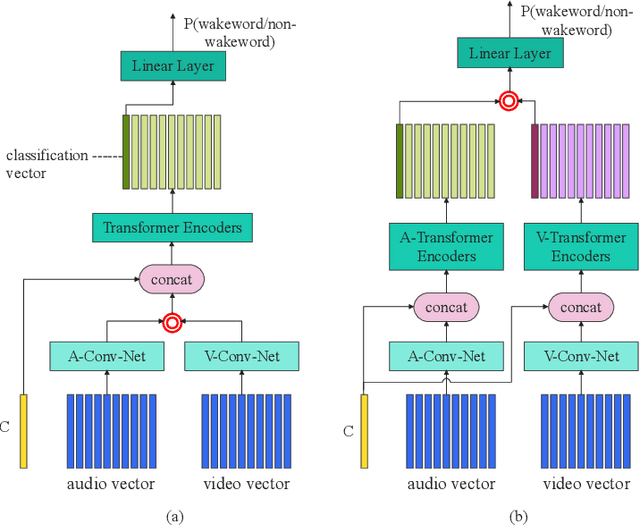

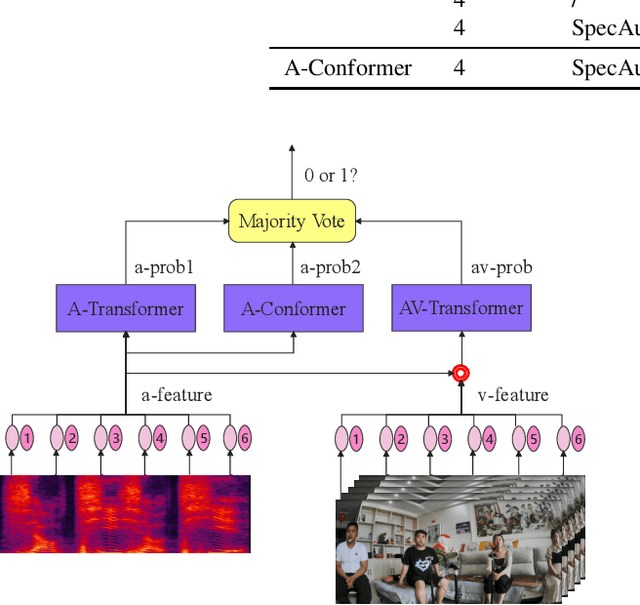
This paper presents the details of our system designed for the Task 1 of Multimodal Information Based Speech Processing (MISP) Challenge 2021. The purpose of Task 1 is to leverage both audio and video information to improve the environmental robustness of far-field wake word spotting. In the proposed system, firstly, we take advantage of speech enhancement algorithms such as beamforming and weighted prediction error (WPE) to address the multi-microphone conversational audio. Secondly, several data augmentation techniques are applied to simulate a more realistic far-field scenario. For the video information, the provided region of interest (ROI) is used to obtain visual representation. Then the multi-layer CNN is proposed to learn audio and visual representations, and these representations are fed into our two-branch attention-based network which can be employed for fusion, such as transformer and conformed. The focal loss is used to fine-tune the model and improve the performance significantly. Finally, multiple trained models are integrated by casting vote to achieve our final 0.091 score.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022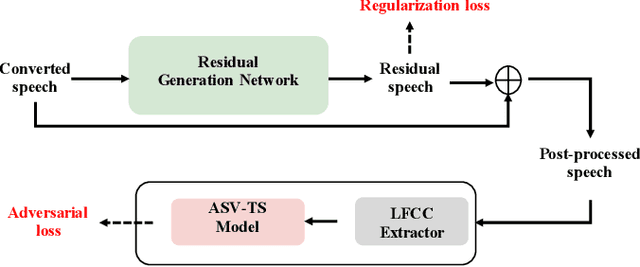

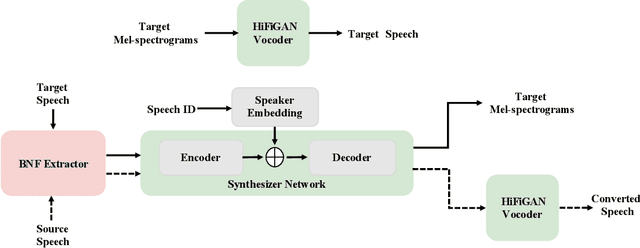
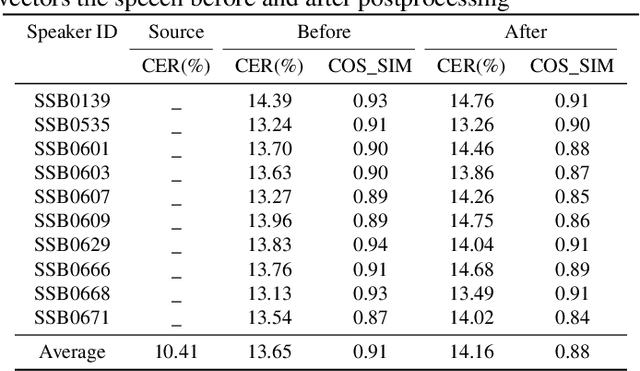
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.