 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-SpEx: Towards Effective Speaker Extraction with Multi-Scale Interfusion and Conditional Speaker Modulation
Paper and Code
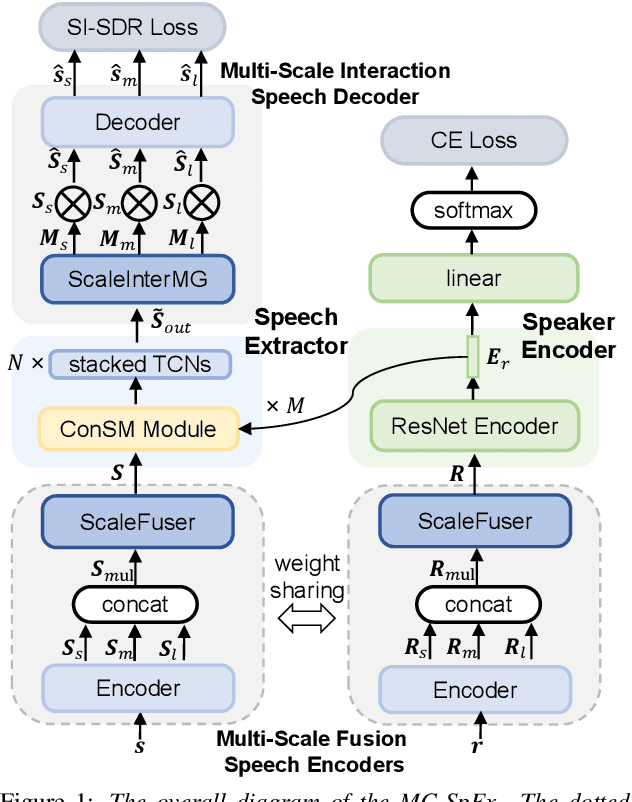

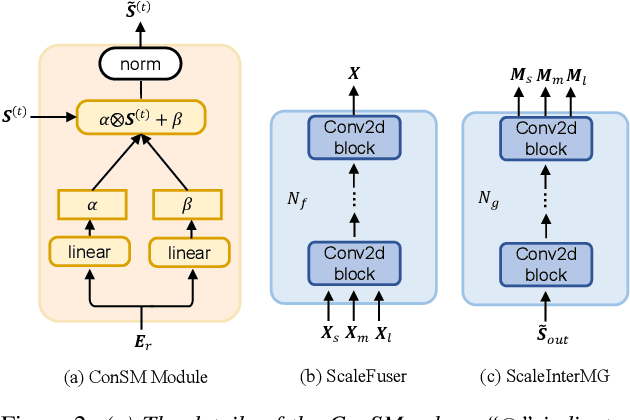

The previous SpEx+ has yielded outstanding performance in speaker extraction and attracted much attention. However, it still encounters inadequate utilization of multi-scale information and speaker embedding. To this end, this paper proposes a new effective speaker extraction system with multi-scale interfusion and conditional speaker modulation (ConSM), which is called MC-SpEx. First of all, we design the weight-share multi-scale fusers (ScaleFusers) for efficiently leveraging multi-scale information as well as ensuring consistency of the model's feature space. Then, to consider different scale information while generating masks, the multi-scale interactive mask generator (ScaleInterMG) is presented. Moreover, we introduce ConSM module to fully exploit speaker embedding in the speech extractor. Experimental results on the Libri2Mix dataset demonstrate the effectiveness of our improvements and the state-of-the-art performance of our proposed MC-SpEx.