 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrames2Residual: Spatiotemporal Decoupling for Self-Supervised Video Denoising
Mar 11, 2026Self-supervised video denoising methods typically extend image-based frameworks into the temporal dimension, yet they often struggle to integrate inter-frame temporal consistency with intra-frame spatial specificity. Existing Video Blind-Spot Networks (BSNs) require noise independence by masking the center pixel, this constraint prevents the use of spatial evidence for texture recovery, thereby severing spatiotemporal correlations and causing texture loss. To address this, we propose Frames2Residual (F2R), a spatiotemporal decoupling framework that explicitly divides self-supervised training into two distinct stages: blind temporal consistency modeling and non-blind spatial texture recovery. In Stage 1, a blind temporal estimator learns inter-frame consistency using a frame-wise blind strategy, producing a temporally consistent anchor. In Stage 2, a non-blind spatial refiner leverages this anchor to safely reintroduce the center frame and recover intra-frame high-frequency spatial residuals while preserving temporal stability. Extensive experiments demonstrate that our decoupling strategy allows F2R to outperform existing self-supervised methods on both sRGB and raw video benchmarks.
Gaseous Object Detection
Feb 18, 2025



Object detection, a fundamental and challenging problem in computer vision, has experienced rapid development due to the effectiveness of deep learning. The current objects to be detected are mostly rigid solid substances with apparent and distinct visual characteristics. In this paper, we endeavor on a scarcely explored task named Gaseous Object Detection (GOD), which is undertaken to explore whether the object detection techniques can be extended from solid substances to gaseous substances. Nevertheless, the gas exhibits significantly different visual characteristics: 1) saliency deficiency, 2) arbitrary and ever-changing shapes, 3) lack of distinct boundaries. To facilitate the study on this challenging task, we construct a GOD-Video dataset comprising 600 videos (141,017 frames) that cover various attributes with multiple types of gases. A comprehensive benchmark is established based on this dataset, allowing for a rigorous evaluation of frame-level and video-level detectors. Deduced from the Gaussian dispersion model, the physics-inspired Voxel Shift Field (VSF) is designed to model geometric irregularities and ever-changing shapes in potential 3D space. By integrating VSF into Faster RCNN, the VSF RCNN serves as a simple but strong baseline for gaseous object detection. Our work aims to attract further research into this valuable albeit challenging area.
Joint RGB-Spectral Decomposition Model Guided Image Enhancement in Mobile Photography
Jul 25, 2024



The integration of miniaturized spectrometers into mobile devices offers new avenues for image quality enhancement and facilitates novel downstream tasks. However, the broader application of spectral sensors in mobile photography is hindered by the inherent complexity of spectral images and the constraints of spectral imaging capabilities. To overcome these challenges, we propose a joint RGB-Spectral decomposition model guided enhancement framework, which consists of two steps: joint decomposition and prior-guided enhancement. Firstly, we leverage the complementarity between RGB and Low-resolution Multi-Spectral Images (Lr-MSI) to predict shading, reflectance, and material semantic priors. Subsequently, these priors are seamlessly integrated into the established HDRNet to promote dynamic range enhancement, color mapping, and grid expert learning, respectively. Additionally, we construct a high-quality Mobile-Spec dataset to support our research, and our experiments validate the effectiveness of Lr-MSI in the tone enhancement task. This work aims to establish a solid foundation for advancing spectral vision in mobile photography. The code is available at \url{https://github.com/CalayZhou/JDM-HDRNet}.
Explore Spatio-temporal Aggregation for Insubstantial Object Detection: Benchmark Dataset and Baseline
Jun 23, 2022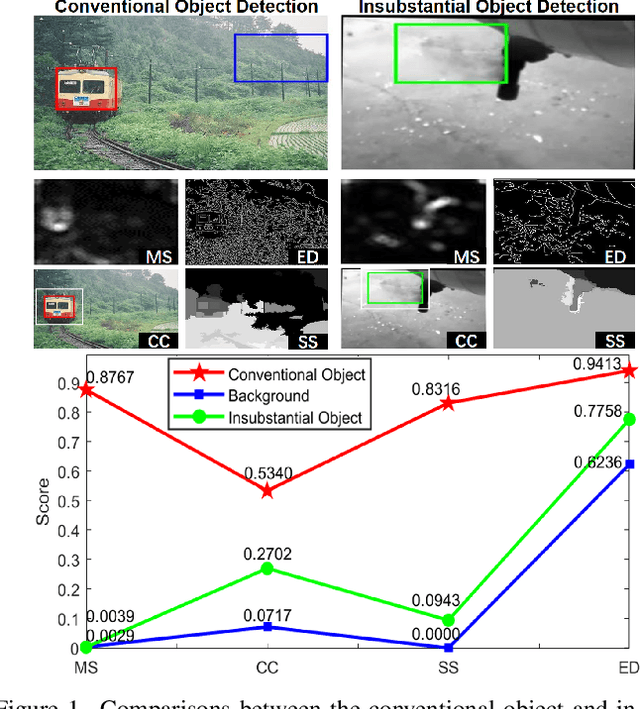
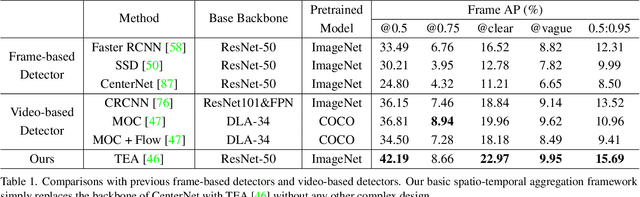
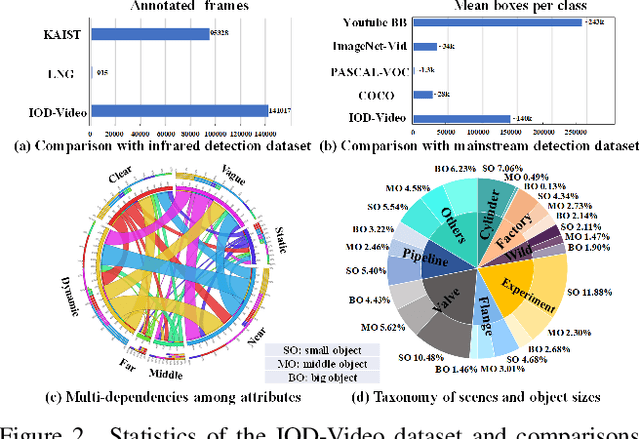
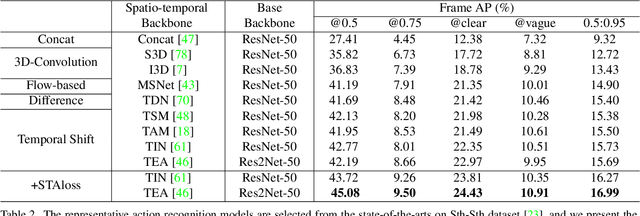
We endeavor on a rarely explored task named Insubstantial Object Detection (IOD), which aims to localize the object with following characteristics: (1) amorphous shape with indistinct boundary; (2) similarity to surroundings; (3) absence in color. Accordingly, it is far more challenging to distinguish insubstantial objects in a single static frame and the collaborative representation of spatial and temporal information is crucial. Thus, we construct an IOD-Video dataset comprised of 600 videos (141,017 frames) covering various distances, sizes, visibility, and scenes captured by different spectral ranges. In addition, we develop a spatio-temporal aggregation framework for IOD, in which different backbones are deployed and a spatio-temporal aggregation loss (STAloss) is elaborately designed to leverage the consistency along the time axis. Experiments conducted on IOD-Video dataset demonstrate that spatio-temporal aggregation can significantly improve the performance of IOD. We hope our work will attract further researches into this valuable yet challenging task. The code will be available at: \url{https://github.com/CalayZhou/IOD-Video}.
Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems
Aug 17, 2020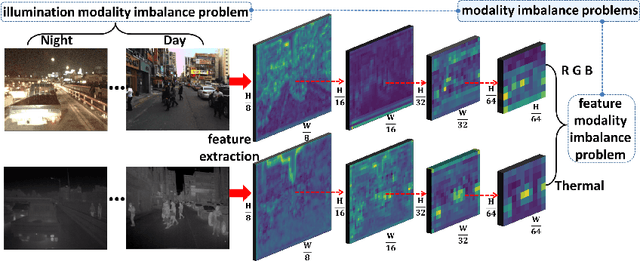
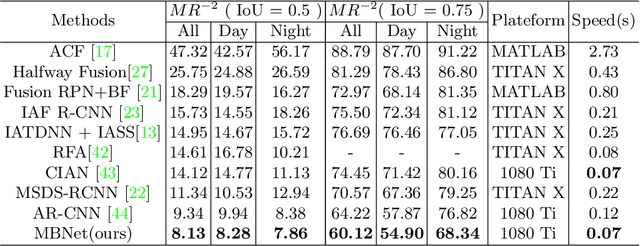
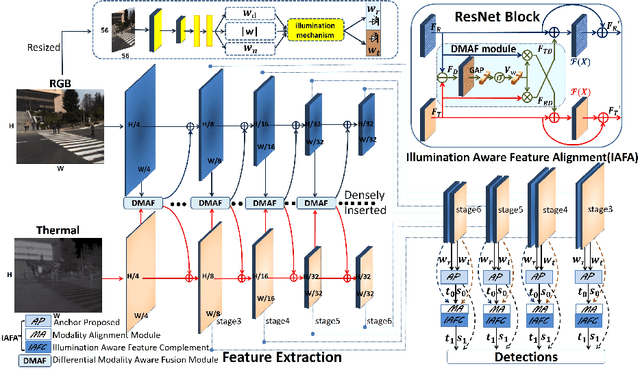
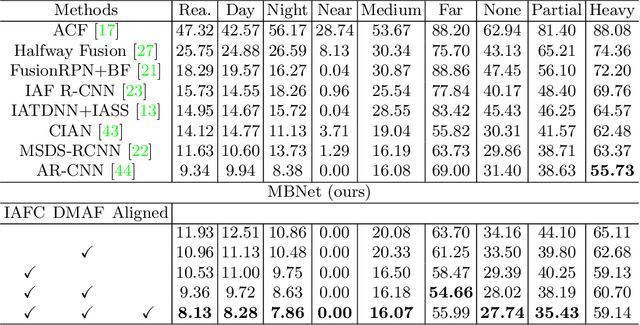
Multispectral pedestrian detection is capable of adapting to insufficient illumination conditions by leveraging color-thermal modalities. On the other hand, it is still lacking of in-depth insights on how to fuse the two modalities effectively. Compared with traditional pedestrian detection, we find multispectral pedestrian detection suffers from modality imbalance problems which will hinder the optimization process of dual-modality network and depress the performance of detector. Inspired by this observation, we propose Modality Balance Network (MBNet) which facilitates the optimization process in a much more flexible and balanced manner. Firstly, we design a novel Differential Modality Aware Fusion (DMAF) module to make the two modalities complement each other. Secondly, an illumination aware feature alignment module selects complementary features according to the illumination conditions and aligns the two modality features adaptively. Extensive experimental results demonstrate MBNet outperforms the state-of-the-arts on both the challenging KAIST and CVC-14 multispectral pedestrian datasets in terms of the accuracy and the computational efficiency. Code is available at https://github.com/CalayZhou/MBNet.