 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecorobos: A Design for Mobile Robots Enabling Cooperative Transitions between Table and Wall Surfaces
Feb 25, 2025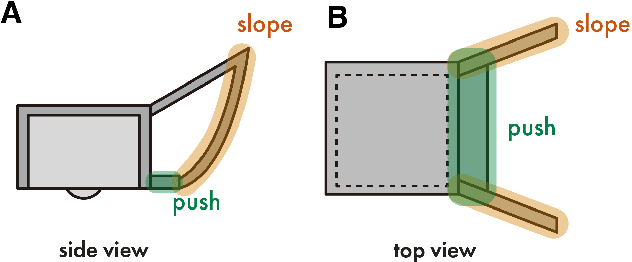
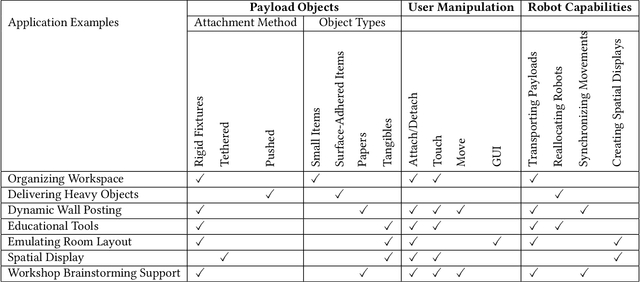
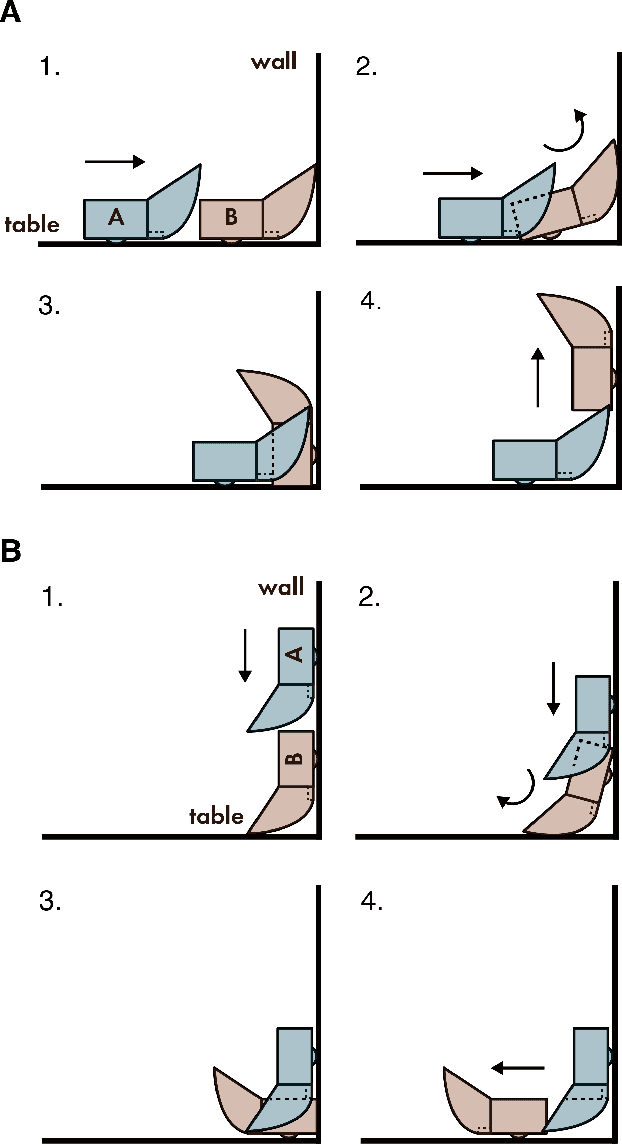
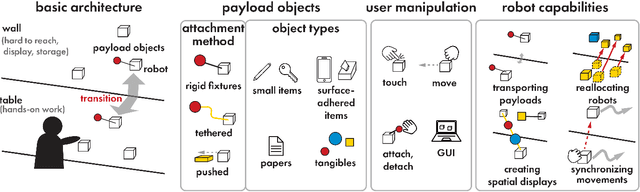
Swarm User Interfaces allow dynamic arrangement of user environments through the use of multiple mobile robots, but their operational range is typically confined to a single plane due to constraints imposed by their two-wheel propulsion systems. We present corobos, a proof-of-concept design that enables these robots to cooperatively transition between table (horizontal) and wall (vertical) surfaces seamlessly, without human intervention. Each robot is equipped with a uniquely designed slope structure that facilitates smooth rotation when another robot pushes it toward a target surface. Notably, this design relies solely on passive mechanical elements, eliminating the need for additional active electrical components. We investigated the design parameters of this structure and evaluated its transition success rate through experiments. Furthermore, we demonstrate various application examples to showcase the potential of corobos in enhancing user environments.
Finding a Needle in a Haystack: Tiny Flying Object Detection in 4K Videos using a Joint Detection-and-Tracking Approach
May 18, 2021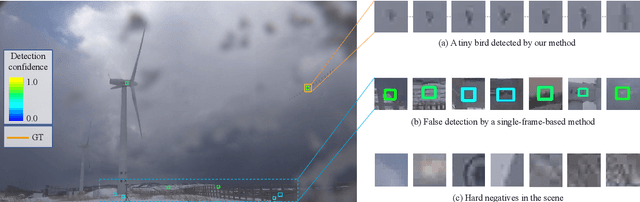
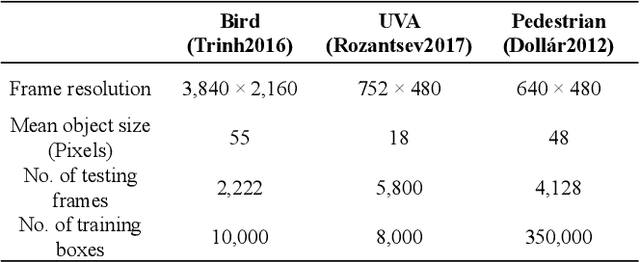

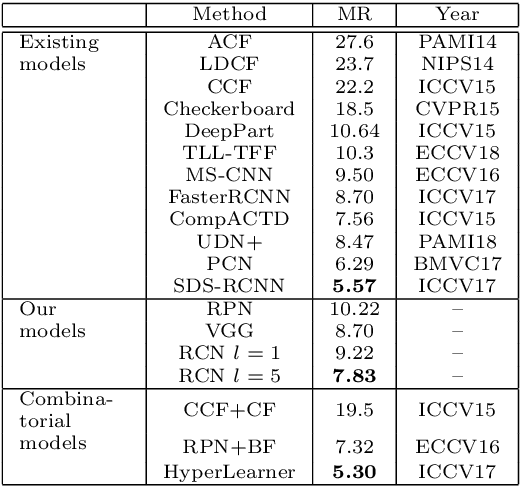
Detecting tiny objects in a high-resolution video is challenging because the visual information is little and unreliable. Specifically, the challenge includes very low resolution of the objects, MPEG artifacts due to compression and a large searching area with many hard negatives. Tracking is equally difficult because of the unreliable appearance, and the unreliable motion estimation. Luckily, we found that by combining this two challenging tasks together, there will be mutual benefits. Following the idea, in this paper, we present a neural network model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. The framework exploits a convolutional long short-term memory network for learning informative appearance changes for detection, while the learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on a bird image dataset.
Hybrid Loss for Learning Single-Image-based HDR Reconstruction
Dec 18, 2018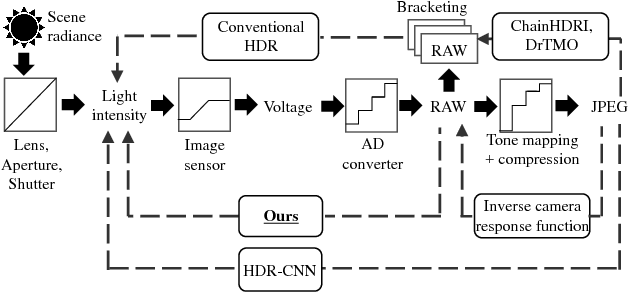

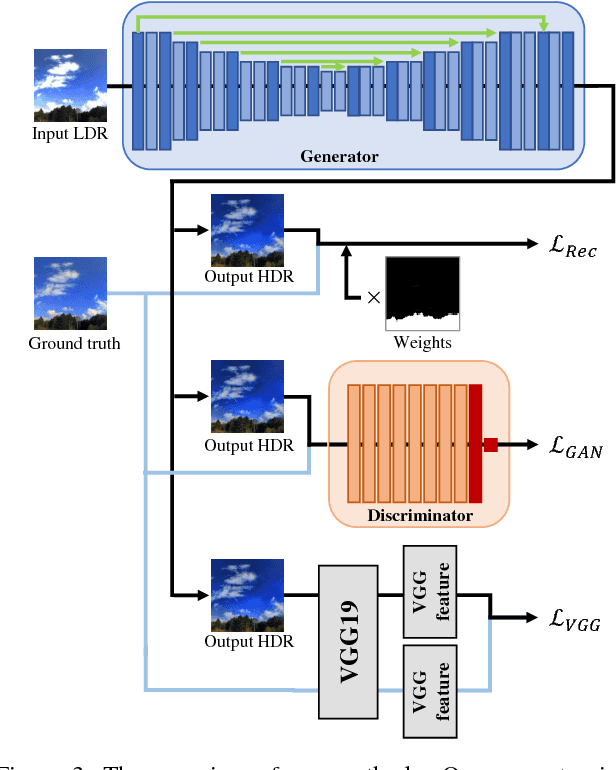

This paper tackles high-dynamic-range (HDR) image reconstruction given only a single low-dynamic-range (LDR) image as input. While the existing methods focus on minimizing the mean-squared-error (MSE) between the target and reconstructed images, we minimize a hybrid loss that consists of perceptual and adversarial losses in addition to HDR-reconstruction loss. The reconstruction loss instead of MSE is more suitable for HDR since it puts more weight on both over- and under- exposed areas. It makes the reconstruction faithful to the input. Perceptual loss enables the networks to utilize knowledge about objects and image structure for recovering the intensity gradients of saturated and grossly quantized areas. Adversarial loss helps to select the most plausible appearance from multiple solutions. The hybrid loss that combines all the three losses is calculated in logarithmic space of image intensity so that the outputs retain a large dynamic range and meanwhile the learning becomes tractable. Comparative experiments conducted with other state-of-the-art methods demonstrated that our method produces a leap in image quality.
Classification-Reconstruction Learning for Open-Set Recognition
Dec 17, 2018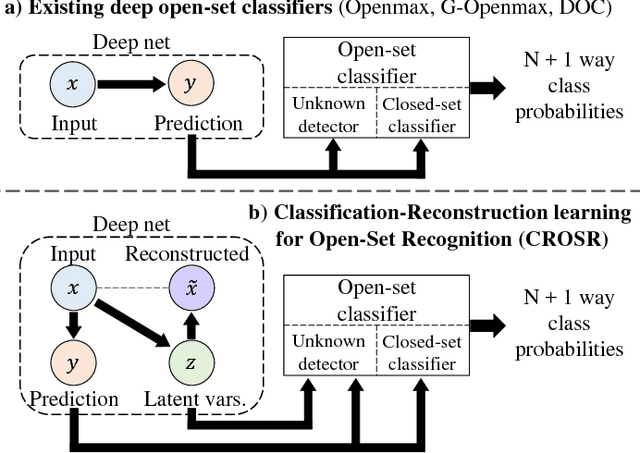
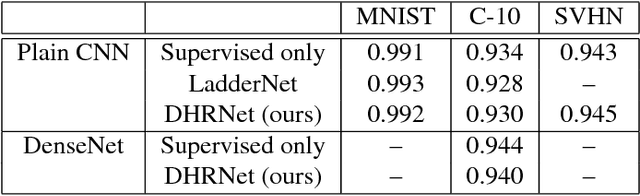
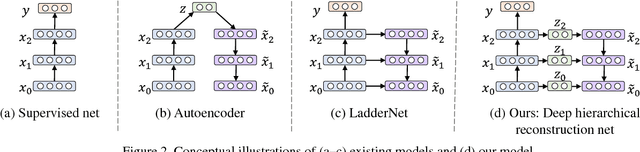
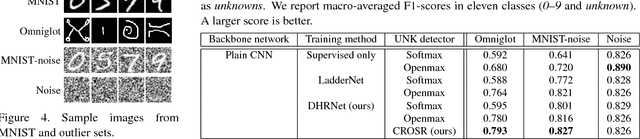
Open-set classification is a problem of handling `unknown' classes that are not contained in the training dataset, whereas traditional classifiers assume that only known classes appear in the test environment. Existing open-set classifiers rely on deep networks trained in a supervised manner on known classes in the training set; this causes specialization of learned representations to known classes and makes it hard to distinguish unknowns from knowns. In contrast, we train networks for joint classification and reconstruction of input data. This enhances the learned representation so as to preserve information useful for separating unknowns from knowns, as well as to discriminate classes of knowns. Our novel Classification-Reconstruction learning for Open-Set Recognition (CROSR) utilizes latent representations for reconstruction and enables robust unknown detection without harming the known-class classification accuracy. Extensive experiments reveal that the proposed method outperforms existing deep open-set classifiers in multiple standard datasets and is robust to diverse outliers.
Differentiating Objects by Motion: Joint Detection and Tracking of Small Flying Objects
May 15, 2018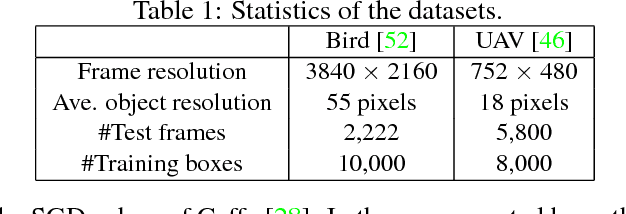
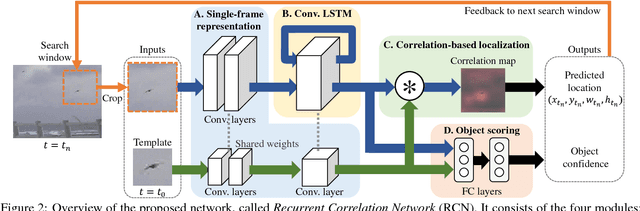
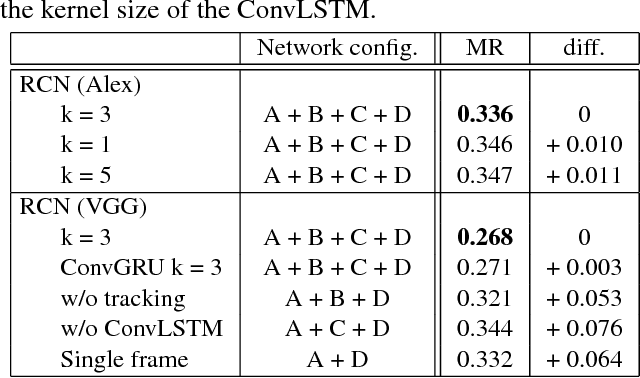
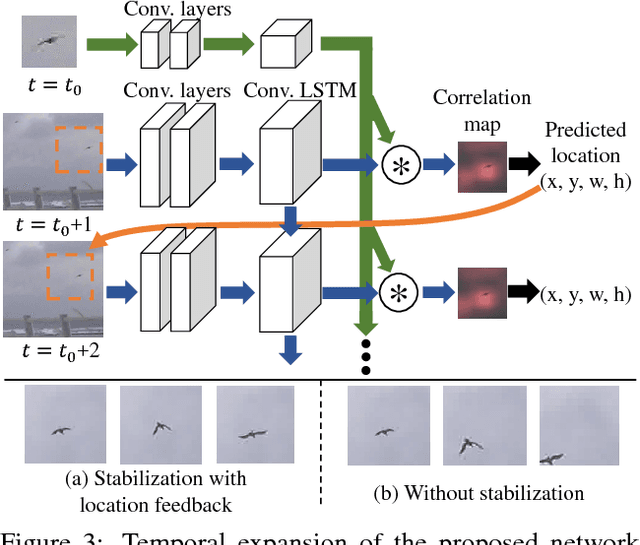
While generic object detection has achieved large improvements with rich feature hierarchies from deep nets, detecting small objects with poor visual cues remains challenging. Motion cues from multiple frames may be more informative for detecting such hard-to-distinguish objects in each frame. However, how to encode discriminative motion patterns, such as deformations and pose changes that characterize objects, has remained an open question. To learn them and thereby realize small object detection, we present a neural model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. A convolutional long short-term memory network is utilized for learning informative appearance change for detection, while learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on the bird dataset.
Cross-connected Networks for Multi-task Learning of Detection and Segmentation
May 15, 2018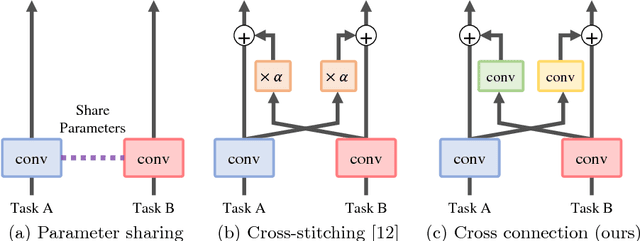
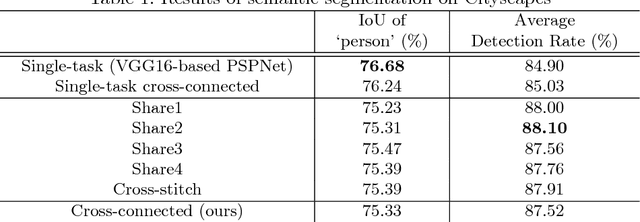
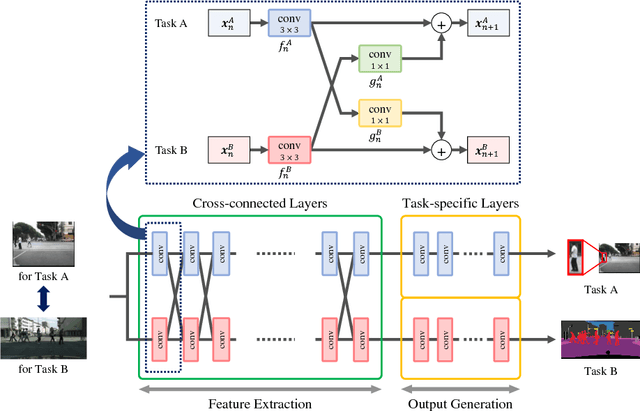
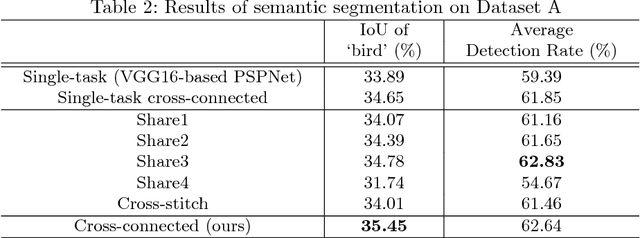
Multi-task learning improves generalization performance by sharing knowledge among related tasks. Existing models are for task combinations annotated on the same dataset, while there are cases where multiple datasets are available for each task. How to utilize knowledge of successful single-task CNNs that are trained on each dataset has been explored less than multi-task learning with a single dataset. We propose a cross-connected CNN, a new architecture that connects single-task CNNs through convolutional layers, which transfer useful information for the counterpart. We evaluated our proposed architecture on a combination of detection and segmentation using two datasets. Experiments on pedestrians show our CNN achieved a higher detection performance compared to baseline CNNs, while maintaining high quality for segmentation. It is the first known attempt to tackle multi-task learning with different training datasets between detection and segmentation. Experiments with wild birds demonstrate how our CNN learns general representations from limited datasets.
Continuous 3D Label Stereo Matching using Local Expansion Moves
Oct 17, 2017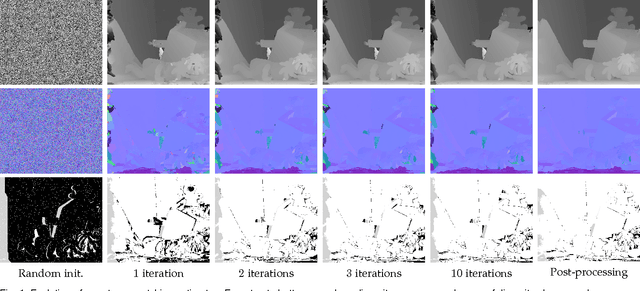
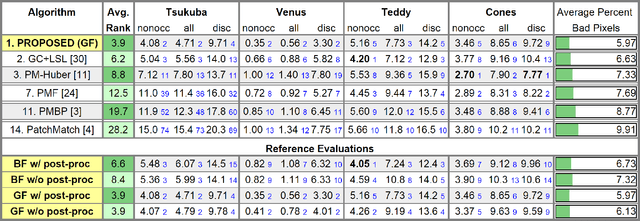

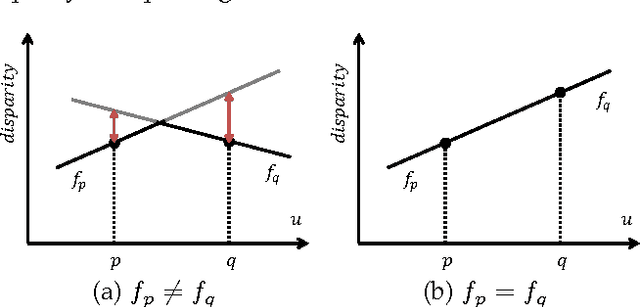
We present an accurate stereo matching method using local expansion moves based on graph cuts. This new move-making scheme is used to efficiently infer per-pixel 3D plane labels on a pairwise Markov random field (MRF) that effectively combines recently proposed slanted patch matching and curvature regularization terms. The local expansion moves are presented as many alpha-expansions defined for small grid regions. The local expansion moves extend traditional expansion moves by two ways: localization and spatial propagation. By localization, we use different candidate alpha-labels according to the locations of local alpha-expansions. By spatial propagation, we design our local alpha-expansions to propagate currently assigned labels for nearby regions. With this localization and spatial propagation, our method can efficiently infer MRF models with a continuous label space using randomized search. Our method has several advantages over previous approaches that are based on fusion moves or belief propagation; it produces submodular moves deriving a subproblem optimality; it helps find good, smooth, piecewise linear disparity maps; it is suitable for parallelization; it can use cost-volume filtering techniques for accelerating the matching cost computations. Even using a simple pairwise MRF, our method is shown to have best performance in the Middlebury stereo benchmark V2 and V3.
* 14 pages. An extended version of our preliminary conference paper [39], Taniai et al. "Graph Cut based Continuous Stereo Matching using Locally Shared Labels" in the proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014). Our results were submitted to Middlebury Stereo Benchmark Version 2 on April 22, 2015, and to Version 3 on July 4, 2017