 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Low-Altitude SAR Imaging into UAV Data Backhaul
Dec 26, 2025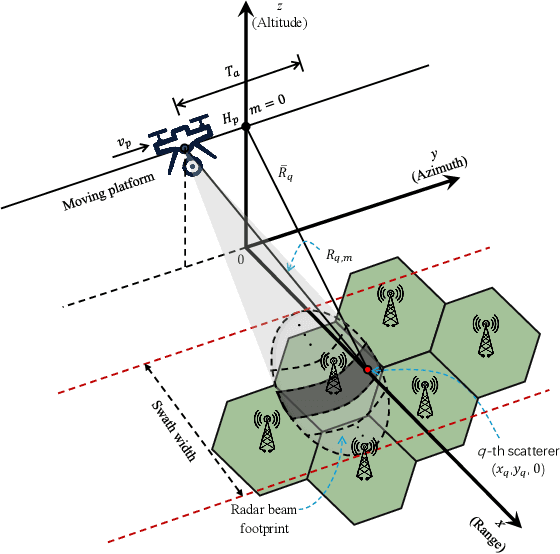
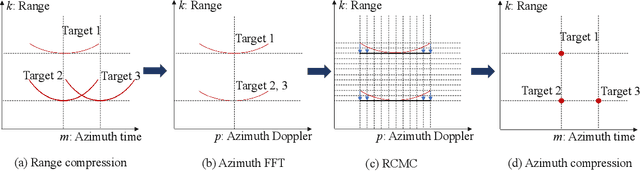
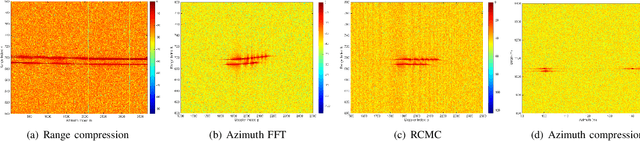
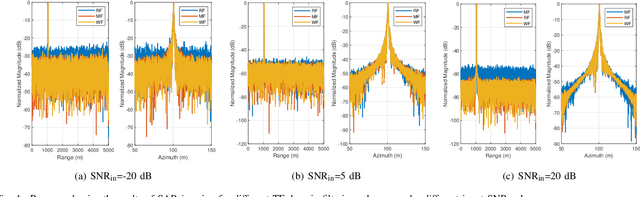
Synthetic aperture radar (SAR) deployed on unmanned aerial vehicles (UAVs) is expected to provide burgeoning imaging services for low-altitude wireless networks (LAWNs), thereby enabling large-scale environmental sensing and timely situational awareness. Conventional SAR systems typically leverages a deterministic radar waveform, while it conflicts with the integrated sensing and communications (ISAC) paradigm by discarding signaling randomness, in whole or in part. In fact, this approach reduces to the uplink pilot sensing in 5G New Radio (NR) with sounding reference signals (SRS), underutilizing data symbols. To explore the potential of data-aided imaging, we develop a low-altitude SAR imaging framework that sufficiently leverages data symbols carried by the native orthogonal frequency division multiplexing (OFDM) communication waveform. The randomness of modulated data in the temporal-frequency (TF) domain, introduced by non-constant modulus constellations such as quadrature amplitude modulation (QAM), may however severely degrade the imaging quality. To mitigate this effect, we incorporate several TF-domain filtering schemes within a rangeDoppler (RD) imaging framework and evaluate their impact. We further propose using the normalized mean square error (NMSE) of a reference point target's profile as an imaging performance metric. Simulation results with 5G NR parameters demonstrate that data-aided imaging substantially outperforms pilot-only counterpart, accordingly validating the effectiveness of the proposed OFDM-SAR imaging approach in LAWNs.
Perception-Inspired Color Space Design for Photo White Balance Editing
Dec 11, 2025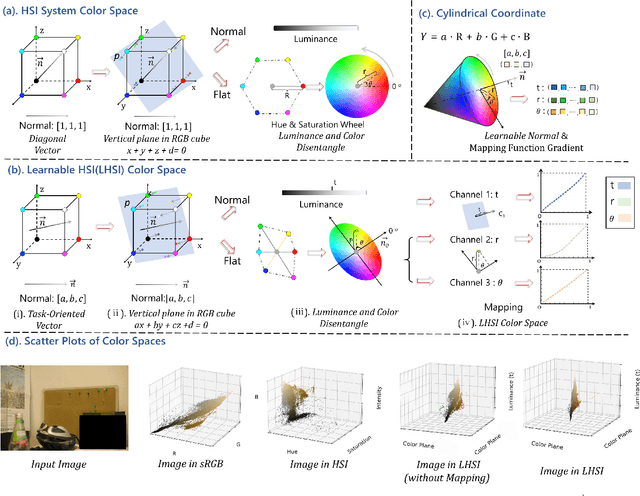
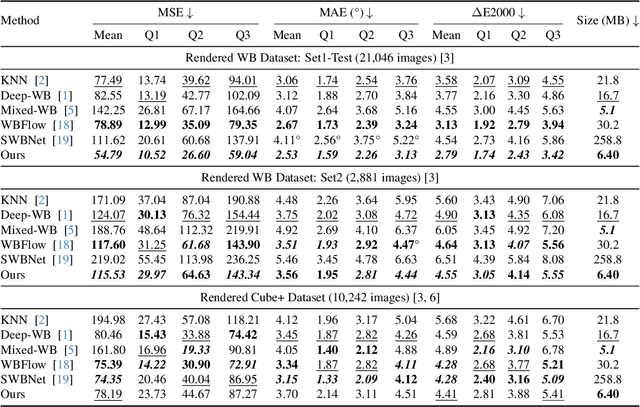
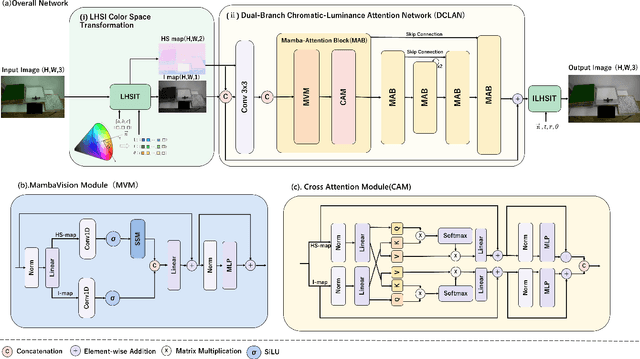
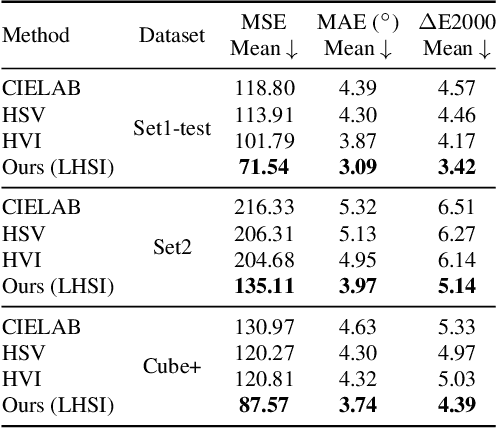
White balance (WB) is a key step in the image signal processor (ISP) pipeline that mitigates color casts caused by varying illumination and restores the scene's true colors. Currently, sRGB-based WB editing for post-ISP WB correction is widely used to address color constancy failures in the ISP pipeline when the original camera RAW is unavailable. However, additive color models (e.g., sRGB) are inherently limited by fixed nonlinear transformations and entangled color channels, which often impede their generalization to complex lighting conditions. To address these challenges, we propose a novel framework for WB correction that leverages a perception-inspired Learnable HSI (LHSI) color space. Built upon a cylindrical color model that naturally separates luminance from chromatic components, our framework further introduces dedicated parameters to enhance this disentanglement and learnable mapping to adaptively refine the flexibility. Moreover, a new Mamba-based network is introduced, which is tailored to the characteristics of the proposed LHSI color space. Experimental results on benchmark datasets demonstrate the superiority of our method, highlighting the potential of perception-inspired color space design in computational photography. The source code is available at https://github.com/YangCheng58/WB_Color_Space.
UMSPU: Universal Multi-Size Phase Unwrapping via Mutual Self-Distillation and Adaptive Boosting Ensemble Segmenters
Dec 07, 2024



Spatial phase unwrapping is a key technique for extracting phase information to obtain 3D morphology and other features. Modern industrial measurement scenarios demand high precision, large image sizes, and high speed. However, conventional methods struggle with noise resistance and processing speed. Current deep learning methods are limited by the receptive field size and sparse semantic information, making them ineffective for large size images. To address this issue, we propose a mutual self-distillation (MSD) mechanism and adaptive boosting ensemble segmenters to construct a universal multi-size phase unwrapping network (UMSPU). MSD performs hierarchical attention refinement and achieves cross-layer collaborative learning through bidirectional distillation, ensuring fine-grained semantic representation across image sizes. The adaptive boosting ensemble segmenters combine weak segmenters with different receptive fields into a strong one, ensuring stable segmentation across spatial frequencies. Experimental results show that UMSPU overcomes image size limitations, achieving high precision across image sizes ranging from 256*256 to 2048*2048 (an 8 times increase). It also outperforms existing methods in speed, robustness, and generalization. Its practicality is further validated in structured light imaging and InSAR. We believe that UMSPU offers a universal solution for phase unwrapping, with broad potential for industrial applications.
Sharp inequality for $\ell_p$ quasi-norm and $\ell_q$-norm with $0<p\leq 1$ and $q>1$
Dec 27, 2023A sharp inequality for $\ell_p$ quasi-norm with $0<p\leq 1$ and $\ell_q$-norm with $q>1$ is derived, which shows that the difference between $\|\textbf{\textit{x}}\|_p$ and $\|\textbf{\textit{x}}\|_q$ of an $n$-dimensional signal $\textbf{\textit{x}}$ is upper bounded by the difference between the maximum and minimum absolute value in $\textbf{\textit{x}}$. The inequality could be used to develop new $\ell_p$-minimization algorithms.
Interference-Resilient OFDM Waveform Design with Subcarrier Interval Constraint for ISAC Systems
Dec 26, 2023Conventional orthogonal frequency division multiplexing (OFDM) waveform design in integrated sensing and communications (ISAC) systems usually selects the channels with high-frequency responses to transmit communication data, which does not fully consider the possible interference in the environment. To mitigate these adverse effects, we propose an optimization model by weighting between peak sidelobe level and communication data rate, with power and communication subcarrier interval constraints. To tackle the resultant nonconvex problem, an iterative adaptive cyclic minimization (ACM) algorithm is developed, where an adaptive iterative factor is introduced to improve convergence. Subsequently, the least squares algorithm is used to reduce the coefficient of variation of envelopes by further optimizing the phase of the OFDM waveform. Finally, the numerical simulations are provided to demonstrate the interference-resilient ability of the proposed OFDM strategy and the robustness of the ACM algorithm.
Towards ISAC-Empowered Vehicular Networks: Framework, Advances, and Opportunities
May 01, 2023



Connected and autonomous vehicle (CAV) networks face several challenges, such as low throughput, high latency, and poor localization accuracy. These challenges severely impede the implementation of CAV networks for immersive metaverse applications and driving safety in future 6G wireless networks. To alleviate these issues, integrated sensing and communications (ISAC) is envisioned as a game-changing technology for future CAV networks. This article presents a comprehensive overview on the application of ISAC techniques in vehicle-to-infrastructure (V2I) networks. We cover the general system framework, representative advances, and a detailed case study on using the 5G New Radio (NR) waveform for sensing-assisted communications in V2I networks. Finally, we highlight open problems and opportunities in the field.
Spatio-Temporal Point Process for Multiple Object Tracking
Feb 05, 2023



Multiple Object Tracking (MOT) focuses on modeling the relationship of detected objects among consecutive frames and merge them into different trajectories. MOT remains a challenging task as noisy and confusing detection results often hinder the final performance. Furthermore, most existing research are focusing on improving detection algorithms and association strategies. As such, we propose a novel framework that can effectively predict and mask-out the noisy and confusing detection results before associating the objects into trajectories. In particular, we formulate such "bad" detection results as a sequence of events and adopt the spatio-temporal point process}to model such events. Traditionally, the occurrence rate in a point process is characterized by an explicitly defined intensity function, which depends on the prior knowledge of some specific tasks. Thus, designing a proper model is expensive and time-consuming, with also limited ability to generalize well. To tackle this problem, we adopt the convolutional recurrent neural network (conv-RNN) to instantiate the point process, where its intensity function is automatically modeled by the training data. Furthermore, we show that our method captures both temporal and spatial evolution, which is essential in modeling events for MOT. Experimental results demonstrate notable improvements in addressing noisy and confusing detection results in MOT datasets. An improved state-of-the-art performance is achieved by incorporating our baseline MOT algorithm with the spatio-temporal point process model.
Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer
Dec 07, 2022



The long-standing theory that a colour-naming system evolves under the dual pressure of efficient communication and perceptual mechanism is supported by more and more linguistic studies including the analysis of four decades' diachronic data from the Nafaanra language. This inspires us to explore whether artificial intelligence could evolve and discover a similar colour-naming system via optimising the communication efficiency represented by high-level recognition performance. Here, we propose a novel colour quantisation transformer, CQFormer, that quantises colour space while maintaining the accuracy of machine recognition on the quantised images. Given an RGB image, Annotation Branch maps it into an index map before generating the quantised image with a colour palette, meanwhile the Palette Branch utilises a key-point detection way to find proper colours in palette among whole colour space. By interacting with colour annotation, CQFormer is able to balance both the machine vision accuracy and colour perceptual structure such as distinct and stable colour distribution for discovered colour system. Very interestingly, we even observe the consistent evolution pattern between our artificial colour system and basic colour terms across human languages. Besides, our colour quantisation method also offers an efficient quantisation method that effectively compresses the image storage while maintaining a high performance in high-level recognition tasks such as classification and detection. Extensive experiments demonstrate the superior performance of our method with extremely low bit-rate colours. We will release the source code soon.
Exploring Resolution and Degradation Clues as Self-supervised Signal for Low Quality Object Detection
Aug 05, 2022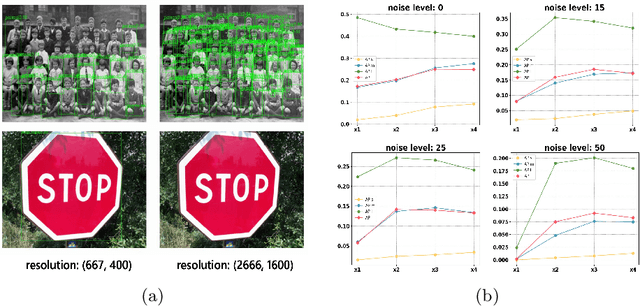
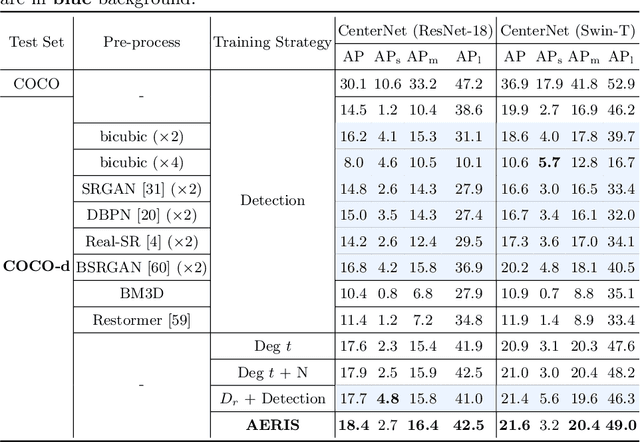
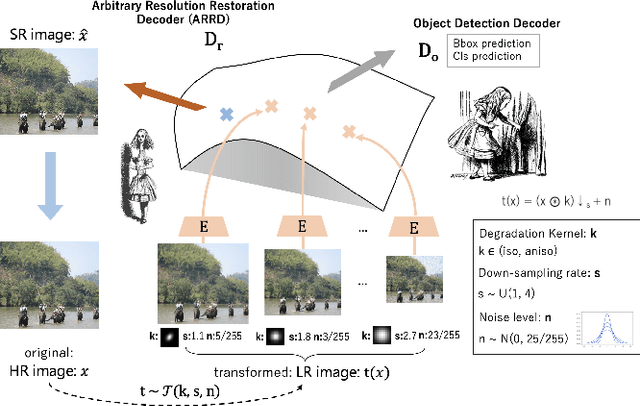
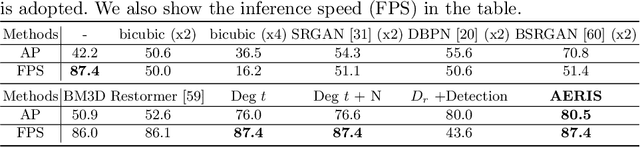
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in low quality images. Most of these algorithms assume the degradation is fixed and known a priori. However, in practical, either the real degradation or optimal up-sampling ratio rate is unknown or differs from assumption, leading to a deteriorating performance for both the pre-processing module and the consequent high-level task such as object detection. Here, we propose a novel self-supervised framework to detect objects in degraded low resolution images. We utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. The Auto Encoding Resolution in Self-supervision (AERIS) framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. The generic AERIS framework could be implemented on various mainstream object detection architectures with different backbones. The extensive experiments show that our methods has achieved superior performance compared with existing methods when facing variant degradation situations. Code would be released at https://github.com/cuiziteng/ECCV_AERIS.
Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection
May 06, 2022

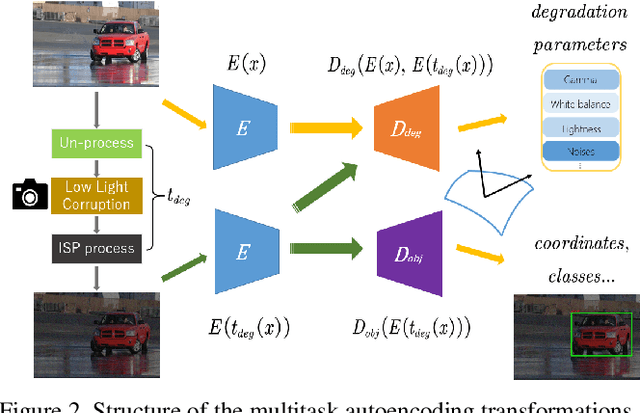

Dark environment becomes a challenge for computer vision algorithms owing to insufficient photons and undesirable noise. To enhance object detection in a dark environment, we propose a novel multitask auto encoding transformation (MAET) model which is able to explore the intrinsic pattern behind illumination translation. In a self-supervision manner, the MAET learns the intrinsic visual structure by encoding and decoding the realistic illumination-degrading transformation considering the physical noise model and image signal processing (ISP). Based on this representation, we achieve the object detection task by decoding the bounding box coordinates and classes. To avoid the over-entanglement of two tasks, our MAET disentangles the object and degrading features by imposing an orthogonal tangent regularity. This forms a parametric manifold along which multitask predictions can be geometrically formulated by maximizing the orthogonality between the tangents along the outputs of respective tasks. Our framework can be implemented based on the mainstream object detection architecture and directly trained end-to-end using normal target detection datasets, such as VOC and COCO. We have achieved the state-of-the-art performance using synthetic and real-world datasets. Code is available at https://github.com/cuiziteng/MAET.