 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoiseSDF2NoiseSDF: Learning Clean Neural Fields from Noisy Supervision
Jul 18, 2025Reconstructing accurate implicit surface representations from point clouds remains a challenging task, particularly when data is captured using low-quality scanning devices. These point clouds often contain substantial noise, leading to inaccurate surface reconstructions. Inspired by the Noise2Noise paradigm for 2D images, we introduce NoiseSDF2NoiseSDF, a novel method designed to extend this concept to 3D neural fields. Our approach enables learning clean neural SDFs directly from noisy point clouds through noisy supervision by minimizing the MSE loss between noisy SDF representations, allowing the network to implicitly denoise and refine surface estimations. We evaluate the effectiveness of NoiseSDF2NoiseSDF on benchmarks, including the ShapeNet, ABC, Famous, and Real datasets. Experimental results demonstrate that our framework significantly improves surface reconstruction quality from noisy inputs.
NumGrad-Pull: Numerical Gradient Guided Tri-plane Representation for Surface Reconstruction from Point Clouds
Nov 26, 2024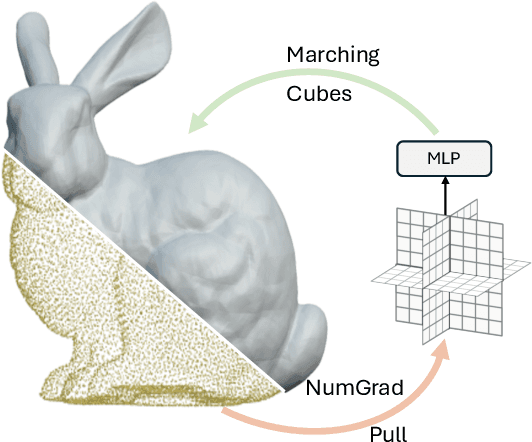
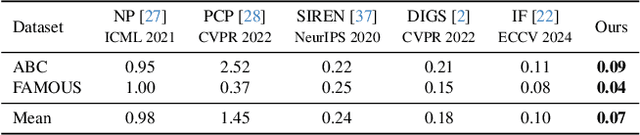
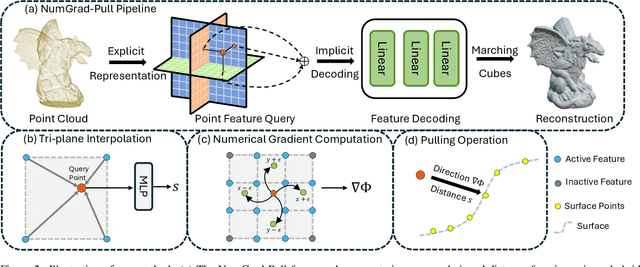
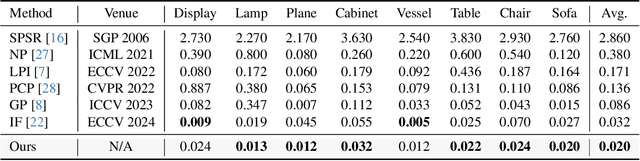
Reconstructing continuous surfaces from unoriented and unordered 3D points is a fundamental challenge in computer vision and graphics. Recent advancements address this problem by training neural signed distance functions to pull 3D location queries to their closest points on a surface, following the predicted signed distances and the analytical gradients computed by the network. In this paper, we introduce NumGrad-Pull, leveraging the representation capability of tri-plane structures to accelerate the learning of signed distance functions and enhance the fidelity of local details in surface reconstruction. To further improve the training stability of grid-based tri-planes, we propose to exploit numerical gradients, replacing conventional analytical computations. Additionally, we present a progressive plane expansion strategy to facilitate faster signed distance function convergence and design a data sampling strategy to mitigate reconstruction artifacts. Our extensive experiments across a variety of benchmarks demonstrate the effectiveness and robustness of our approach. Code is available at https://github.com/CuiRuikai/NumGrad-Pull
LAM3D: Large Image-Point-Cloud Alignment Model for 3D Reconstruction from Single Image
May 24, 2024

Large Reconstruction Models have made significant strides in the realm of automated 3D content generation from single or multiple input images. Despite their success, these models often produce 3D meshes with geometric inaccuracies, stemming from the inherent challenges of deducing 3D shapes solely from image data. In this work, we introduce a novel framework, the Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. Our methodology begins with the development of a point-cloud-based network that effectively generates precise and meaningful latent tri-planes, laying the groundwork for accurate 3D mesh reconstruction. Building upon this, our Image-Point-Cloud Feature Alignment technique processes a single input image, aligning to the latent tri-planes to imbue image features with robust 3D information. This process not only enriches the image features but also facilitates the production of high-fidelity 3D meshes without the need for multi-view input, significantly reducing geometric distortions. Our approach achieves state-of-the-art high-fidelity 3D mesh reconstruction from a single image in just 6 seconds, and experiments on various datasets demonstrate its effectiveness.
NeuSDFusion: A Spatial-Aware Generative Model for 3D Shape Completion, Reconstruction, and Generation
Mar 27, 2024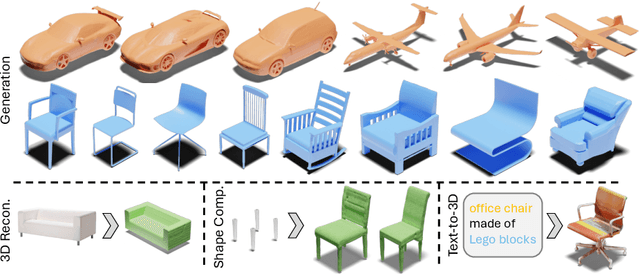
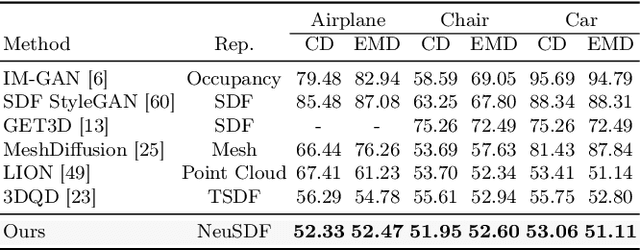

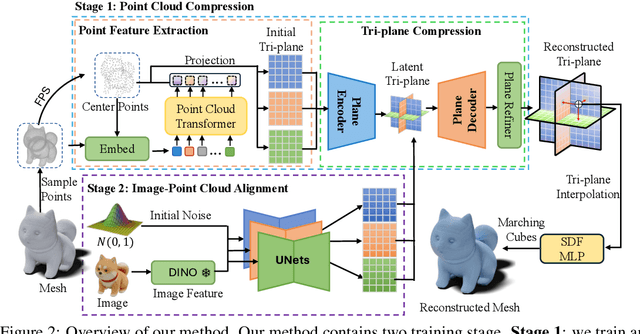
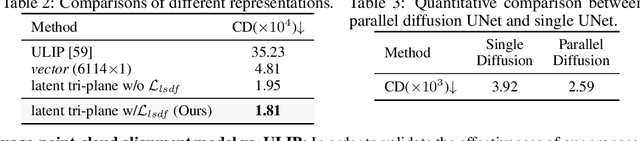
3D shape generation aims to produce innovative 3D content adhering to specific conditions and constraints. Existing methods often decompose 3D shapes into a sequence of localized components, treating each element in isolation without considering spatial consistency. As a result, these approaches exhibit limited versatility in 3D data representation and shape generation, hindering their ability to generate highly diverse 3D shapes that comply with the specified constraints. In this paper, we introduce a novel spatial-aware 3D shape generation framework that leverages 2D plane representations for enhanced 3D shape modeling. To ensure spatial coherence and reduce memory usage, we incorporate a hybrid shape representation technique that directly learns a continuous signed distance field representation of the 3D shape using orthogonal 2D planes. Additionally, we meticulously enforce spatial correspondences across distinct planes using a transformer-based autoencoder structure, promoting the preservation of spatial relationships in the generated 3D shapes. This yields an algorithm that consistently outperforms state-of-the-art 3D shape generation methods on various tasks, including unconditional shape generation, multi-modal shape completion, single-view reconstruction, and text-to-shape synthesis.
BlockFusion: Expandable 3D Scene Generation using Latent Tri-plane Extrapolation
Jan 31, 2024



We present BlockFusion, a diffusion-based model that generates 3D scenes as unit blocks and seamlessly incorporates new blocks to extend the scene. BlockFusion is trained using datasets of 3D blocks that are randomly cropped from complete 3D scene meshes. Through per-block fitting, all training blocks are converted into the hybrid neural fields: with a tri-plane containing the geometry features, followed by a Multi-layer Perceptron (MLP) for decoding the signed distance values. A variational auto-encoder is employed to compress the tri-planes into the latent tri-plane space, on which the denoising diffusion process is performed. Diffusion applied to the latent representations allows for high-quality and diverse 3D scene generation. To expand a scene during generation, one needs only to append empty blocks to overlap with the current scene and extrapolate existing latent tri-planes to populate new blocks. The extrapolation is done by conditioning the generation process with the feature samples from the overlapping tri-planes during the denoising iterations. Latent tri-plane extrapolation produces semantically and geometrically meaningful transitions that harmoniously blend with the existing scene. A 2D layout conditioning mechanism is used to control the placement and arrangement of scene elements. Experimental results indicate that BlockFusion is capable of generating diverse, geometrically consistent and unbounded large 3D scenes with unprecedented high-quality shapes in both indoor and outdoor scenarios.
Adaptive Low Rank Adaptation of Segment Anything to Salient Object Detection
Aug 10, 2023
Foundation models, such as OpenAI's GPT-3 and GPT-4, Meta's LLaMA, and Google's PaLM2, have revolutionized the field of artificial intelligence. A notable paradigm shift has been the advent of the Segment Anything Model (SAM), which has exhibited a remarkable capability to segment real-world objects, trained on 1 billion masks and 11 million images. Although SAM excels in general object segmentation, it lacks the intrinsic ability to detect salient objects, resulting in suboptimal performance in this domain. To address this challenge, we present the Segment Salient Object Model (SSOM), an innovative approach that adaptively fine-tunes SAM for salient object detection by harnessing the low-rank structure inherent in deep learning. Comprehensive qualitative and quantitative evaluations across five challenging RGB benchmark datasets demonstrate the superior performance of our approach, surpassing state-of-the-art methods.
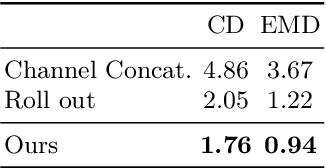
Model Calibration in Dense Classification with Adaptive Label Perturbation
Aug 03, 2023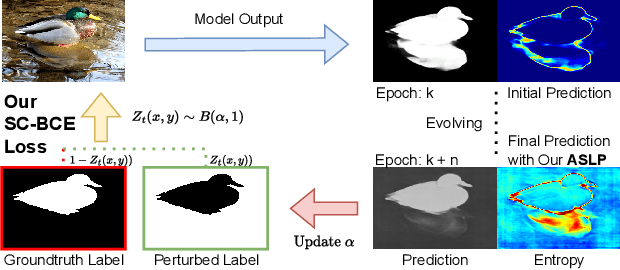
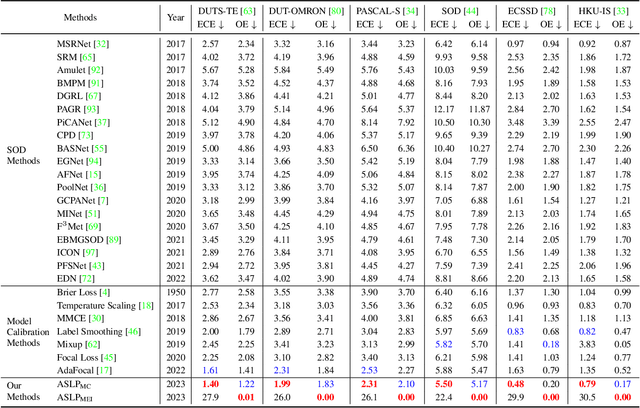
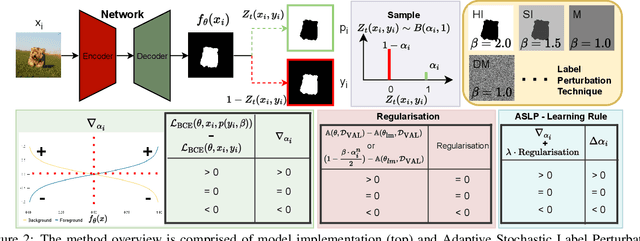
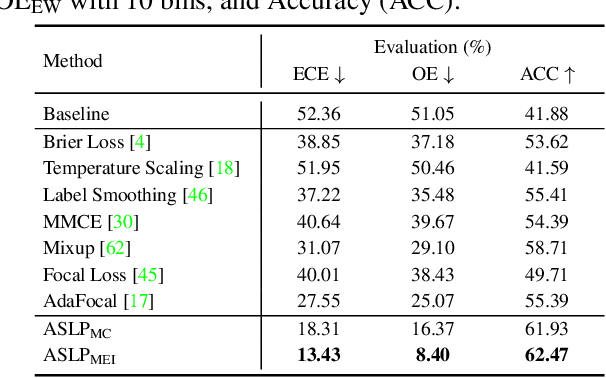
For safety-related applications, it is crucial to produce trustworthy deep neural networks whose prediction is associated with confidence that can represent the likelihood of correctness for subsequent decision-making. Existing dense binary classification models are prone to being over-confident. To improve model calibration, we propose Adaptive Stochastic Label Perturbation (ASLP) which learns a unique label perturbation level for each training image. ASLP employs our proposed Self-Calibrating Binary Cross Entropy (SC-BCE) loss, which unifies label perturbation processes including stochastic approaches (like DisturbLabel), and label smoothing, to correct calibration while maintaining classification rates. ASLP follows Maximum Entropy Inference of classic statistical mechanics to maximise prediction entropy with respect to missing information. It performs this while: (1) preserving classification accuracy on known data as a conservative solution, or (2) specifically improves model calibration degree by minimising the gap between the prediction accuracy and expected confidence of the target training label. Extensive results demonstrate that ASLP can significantly improve calibration degrees of dense binary classification models on both in-distribution and out-of-distribution data. The code is available on https://github.com/Carlisle-Liu/ASLP.
P2C: Self-Supervised Point Cloud Completion from Single Partial Clouds
Jul 27, 2023



Point cloud completion aims to recover the complete shape based on a partial observation. Existing methods require either complete point clouds or multiple partial observations of the same object for learning. In contrast to previous approaches, we present Partial2Complete (P2C), the first self-supervised framework that completes point cloud objects using training samples consisting of only a single incomplete point cloud per object. Specifically, our framework groups incomplete point clouds into local patches as input and predicts masked patches by learning prior information from different partial objects. We also propose Region-Aware Chamfer Distance to regularize shape mismatch without limiting completion capability, and devise the Normal Consistency Constraint to incorporate a local planarity assumption, encouraging the recovered shape surface to be continuous and complete. In this way, P2C no longer needs multiple observations or complete point clouds as ground truth. Instead, structural cues are learned from a category-specific dataset to complete partial point clouds of objects. We demonstrate the effectiveness of our approach on both synthetic ShapeNet data and real-world ScanNet data, showing that P2C produces comparable results to methods trained with complete shapes, and outperforms methods learned with multiple partial observations. Code is available at https://github.com/CuiRuikai/Partial2Complete.
Energy-Based Residual Latent Transport for Unsupervised Point Cloud Completion
Nov 13, 2022Unsupervised point cloud completion aims to infer the whole geometry of a partial object observation without requiring partial-complete correspondence. Differing from existing deterministic approaches, we advocate generative modeling based unsupervised point cloud completion to explore the missing correspondence. Specifically, we propose a novel framework that performs completion by transforming a partial shape encoding into a complete one using a latent transport module, and it is designed as a latent-space energy-based model (EBM) in an encoder-decoder architecture, aiming to learn a probability distribution conditioned on the partial shape encoding. To train the latent code transport module and the encoder-decoder network jointly, we introduce a residual sampling strategy, where the residual captures the domain gap between partial and complete shape latent spaces. As a generative model-based framework, our method can produce uncertainty maps consistent with human perception, leading to explainable unsupervised point cloud completion. We experimentally show that the proposed method produces high-fidelity completion results, outperforming state-of-the-art models by a significant margin.