 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Predictive Empowerment: Measuring Empowerment without a Simulator
Oct 15, 2024Empowerment has the potential to help agents learn large skillsets, but is not yet a scalable solution for training general-purpose agents. Recent empowerment methods learn diverse skillsets by maximizing the mutual information between skills and states; however, these approaches require a model of the transition dynamics, which can be challenging to learn in realistic settings with high-dimensional and stochastic observations. We present Latent-Predictive Empowerment (LPE), an algorithm that can compute empowerment in a more practical manner. LPE learns large skillsets by maximizing an objective that is a principled replacement for the mutual information between skills and states and that only requires a simpler latent-predictive model rather than a full simulator of the environment. We show empirically in a variety of settings--including ones with high-dimensional observations and highly stochastic transition dynamics--that our empowerment objective (i) learns similar-sized skillsets as the leading empowerment algorithm that assumes access to a model of the transition dynamics and (ii) outperforms other model-based approaches to empowerment.
Hierarchical Empowerment: Towards Tractable Empowerment-Based Skill-Learning
Jul 06, 2023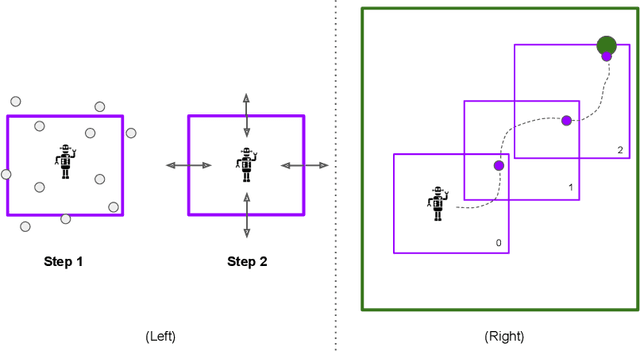

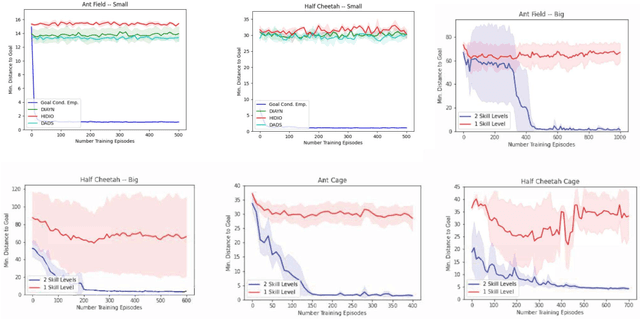

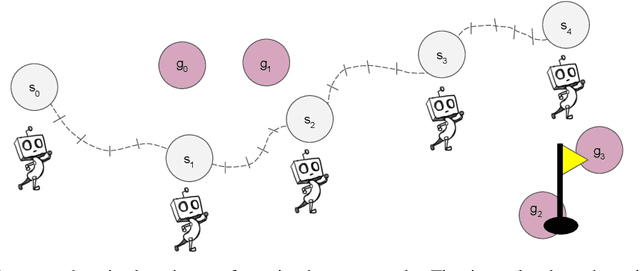
General purpose agents will require large repertoires of skills. Empowerment -- the maximum mutual information between skills and the states -- provides a pathway for learning large collections of distinct skills, but mutual information is difficult to optimize. We introduce a new framework, Hierarchical Empowerment, that makes computing empowerment more tractable by integrating concepts from Goal-Conditioned Hierarchical Reinforcement Learning. Our framework makes two specific contributions. First, we introduce a new variational lower bound on mutual information that can be used to compute empowerment over short horizons. Second, we introduce a hierarchical architecture for computing empowerment over exponentially longer time scales. We verify the contributions of the framework in a series of simulated robotics tasks. In a popular ant navigation domain, our four level agents are able to learn skills that cover a surface area over two orders of magnitude larger than prior work.
HAC Explore: Accelerating Exploration with Hierarchical Reinforcement Learning
Aug 12, 2021
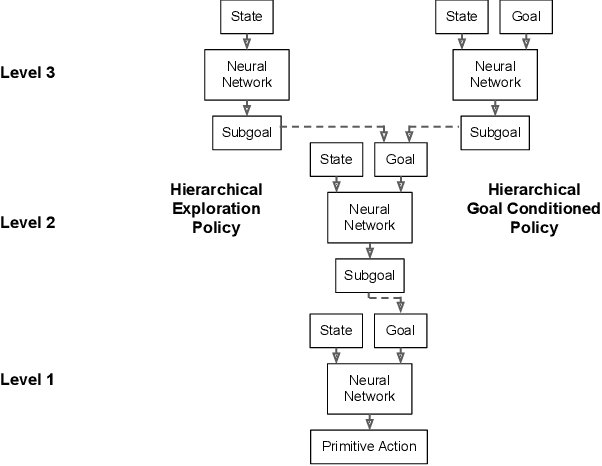

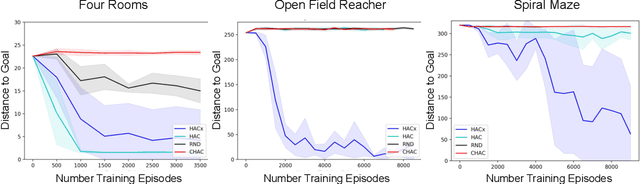
Sparse rewards and long time horizons remain challenging for reinforcement learning algorithms. Exploration bonuses can help in sparse reward settings by encouraging agents to explore the state space, while hierarchical approaches can assist with long-horizon tasks by decomposing lengthy tasks into shorter subtasks. We propose HAC Explore (HACx), a new method that combines these approaches by integrating the exploration bonus method Random Network Distillation (RND) into the hierarchical approach Hierarchical Actor-Critic (HAC). HACx outperforms either component method on its own, as well as an existing approach to combining hierarchy and exploration, in a set of difficult simulated robotics tasks. HACx is the first RL method to solve a sparse reward, continuous-control task that requires over 1,000 actions.
Hierarchical Reinforcement Learning with Hindsight
Mar 08, 2019


Reinforcement Learning (RL) algorithms can suffer from poor sample efficiency when rewards are delayed and sparse. We introduce a solution that enables agents to learn temporally extended actions at multiple levels of abstraction in a sample efficient and automated fashion. Our approach combines universal value functions and hindsight learning, allowing agents to learn policies belonging to different time scales in parallel. We show that our method significantly accelerates learning in a variety of discrete and continuous tasks.
Learning Multi-Level Hierarchies with Hindsight
Mar 01, 2019
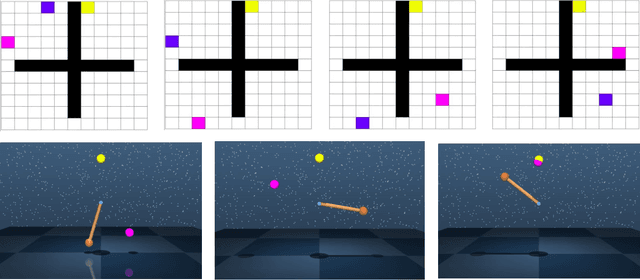
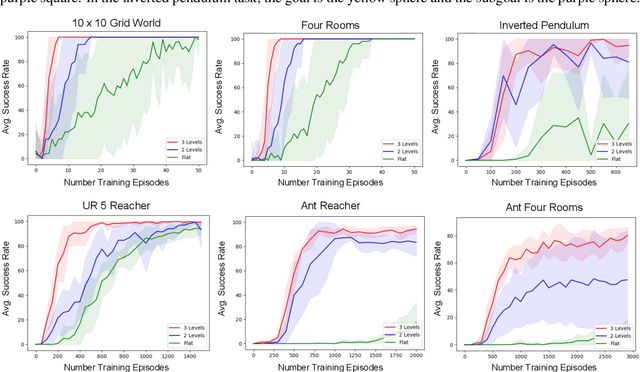
Multi-level hierarchies have the potential to accelerate learning in sparse reward tasks because they can divide a problem into a set of short horizon subproblems. In order to realize this potential, Hierarchical Reinforcement Learning (HRL) algorithms need to be able to learn the multiple levels within a hierarchy in parallel, so these simpler subproblems can be solved simultaneously. Yet most existing HRL methods that can learn hierarchies are not able to efficiently learn multiple levels of policies at the same time, particularly in continuous domains. To address this problem, we introduce a framework that can learn multiple levels of policies in parallel. Our approach consists of two main components: (i) a particular hierarchical architecture and (ii) a method for jointly learning multiple levels of policies. The hierarchies produced by our framework are comprised of a set of nested, goal-conditioned policies that use the state space to decompose a task into short subtasks. All policies in the hierarchy are learned simultaneously using two types of hindsight transitions. We demonstrate experimentally in both grid world and simulated robotics domains that our approach can significantly accelerate learning relative to other non-hierarchical and hierarchical methods. Indeed, our framework is the first to successfully learn 3-level hierarchies in parallel in tasks with continuous state and action spaces.