 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Iterative Policy Improvement for Dynamic Manipulation
Aug 20, 2025Attention-based architectures trained on internet-scale language data have demonstrated state of the art reasoning ability for various language-based tasks, such as logic problems and textual reasoning. Additionally, these Large Language Models (LLMs) have exhibited the ability to perform few-shot prediction via in-context learning, in which input-output examples provided in the prompt are generalized to new inputs. This ability furthermore extends beyond standard language tasks, enabling few-shot learning for general patterns. In this work, we consider the application of in-context learning with pre-trained language models for dynamic manipulation. Dynamic manipulation introduces several crucial challenges, including increased dimensionality, complex dynamics, and partial observability. To address this, we take an iterative approach, and formulate our in-context learning problem to predict adjustments to a parametric policy based on previous interactions. We show across several tasks in simulation and on a physical robot that utilizing in-context learning outperforms alternative methods in the low data regime. Video summary of this work and experiments can be found https://youtu.be/2inxpdrq74U?si=dAdDYsUEr25nZvRn.
Robust In-Hand Manipulation with Extrinsic Contacts
Mar 27, 2024

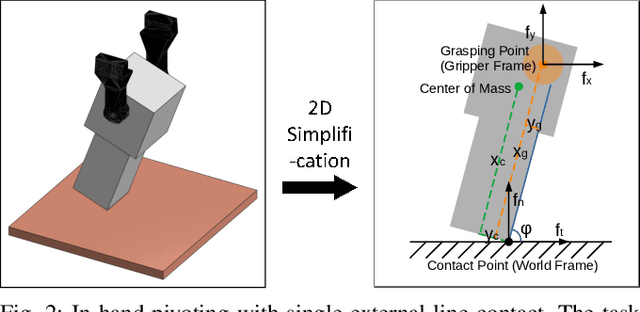
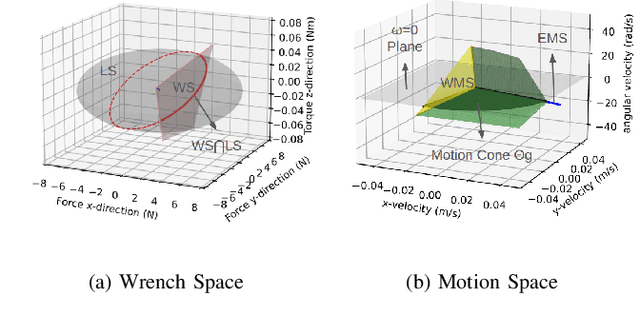
We present in-hand manipulation tasks where a robot moves an object in grasp, maintains its external contact mode with the environment, and adjusts its in-hand pose simultaneously. The proposed manipulation task leads to complex contact interactions which can be very susceptible to uncertainties in kinematic and physical parameters. Therefore, we propose a robust in-hand manipulation method, which consists of two parts. First, an in-gripper mechanics model that computes a na\"ive motion cone assuming all parameters are precise. Then, a robust planning method refines the motion cone to maintain desired contact mode regardless of parametric errors. Real-world experiments were conducted to illustrate the accuracy of the mechanics model and the effectiveness of the robust planning framework in the presence of kinematics parameter errors.
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos
Jun 27, 2023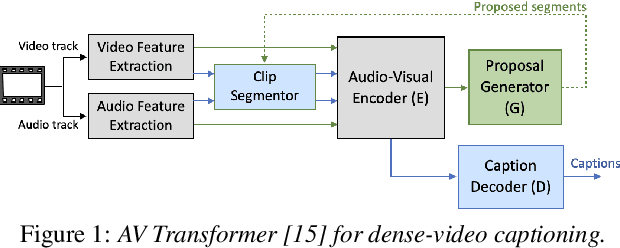

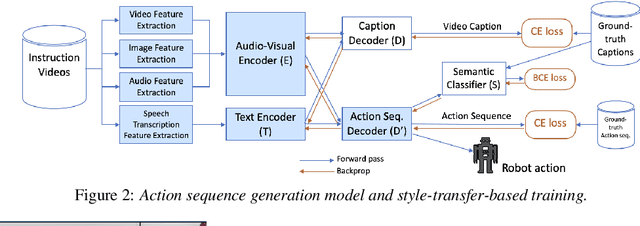
To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
Learning robot motor skills with mixed reality
Mar 21, 2022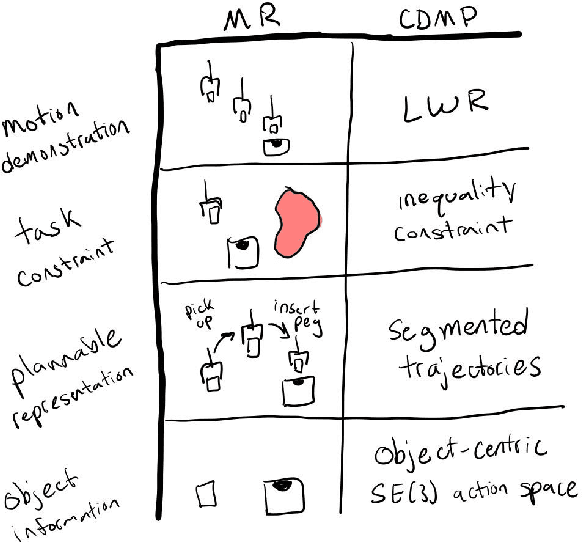

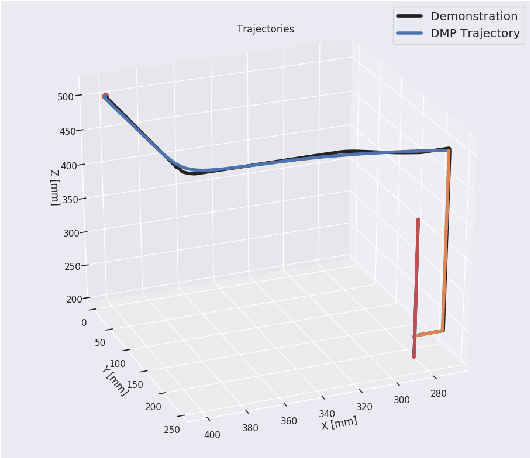
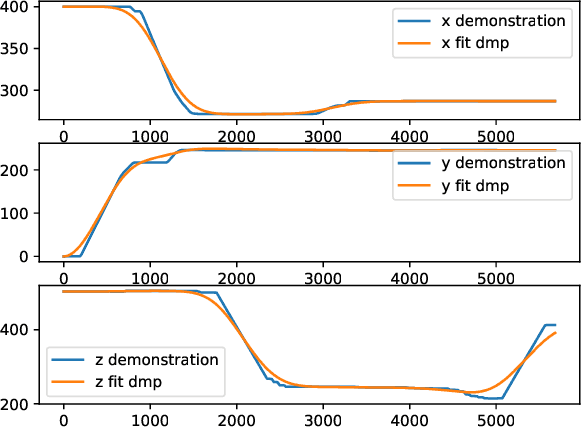
Mixed Reality (MR) has recently shown great success as an intuitive interface for enabling end-users to teach robots. Related works have used MR interfaces to communicate robot intents and beliefs to a co-located human, as well as developed algorithms for taking multi-modal human input and learning complex motor behaviors. Even with these successes, enabling end-users to teach robots complex motor tasks still poses a challenge because end-user communication is highly task dependent and world knowledge is highly varied. We propose a learning framework where end-users teach robots a) motion demonstrations, b) task constraints, c) planning representations, and d) object information, all of which are integrated into a single motor skill learning framework based on Dynamic Movement Primitives (DMPs). We hypothesize that conveying this world knowledge will be intuitive with an MR interface, and that a sample-efficient motor skill learning framework which incorporates varied modalities of world knowledge will enable robots to effectively solve complex tasks.
Quasi-Newton Trust Region Policy Optimization
Dec 26, 2019



We propose a trust region method for policy optimization that employs Quasi-Newton approximation for the Hessian, called Quasi-Newton Trust Region Policy Optimization QNTRPO. Gradient descent is the de facto algorithm for reinforcement learning tasks with continuous controls. The algorithm has achieved state-of-the-art performance when used in reinforcement learning across a wide range of tasks. However, the algorithm suffers from a number of drawbacks including: lack of stepsize selection criterion, and slow convergence. We investigate the use of a trust region method using dogleg step and a Quasi-Newton approximation for the Hessian for policy optimization. We demonstrate through numerical experiments over a wide range of challenging continuous control tasks that our particular choice is efficient in terms of number of samples and improves performance
Learning Deep Parameterized Skills from Demonstration for Re-targetable Visuomotor Control
Oct 23, 2019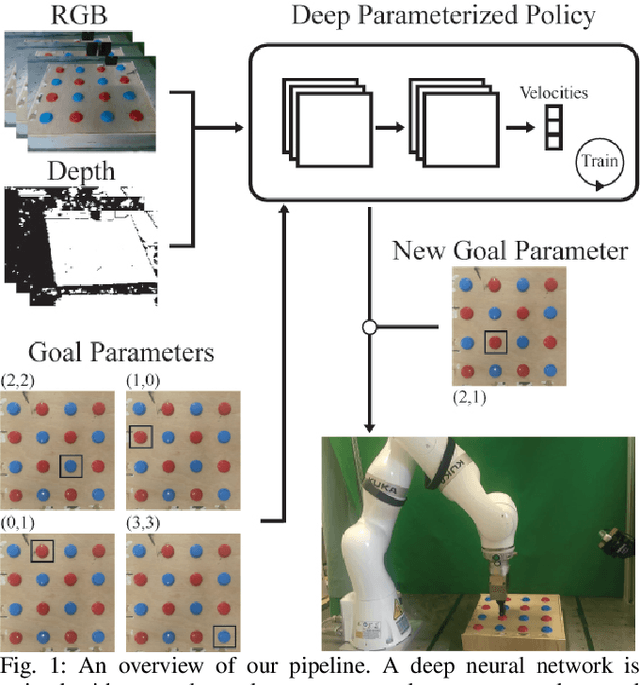

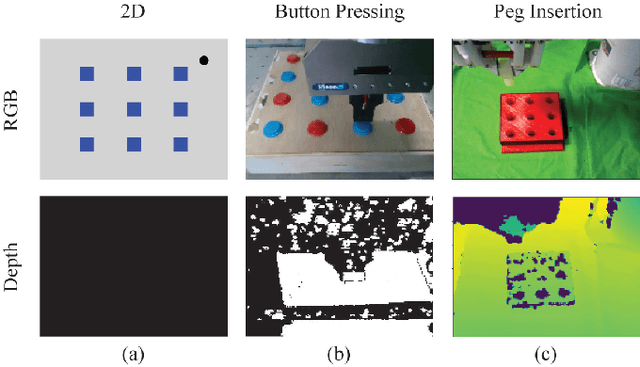
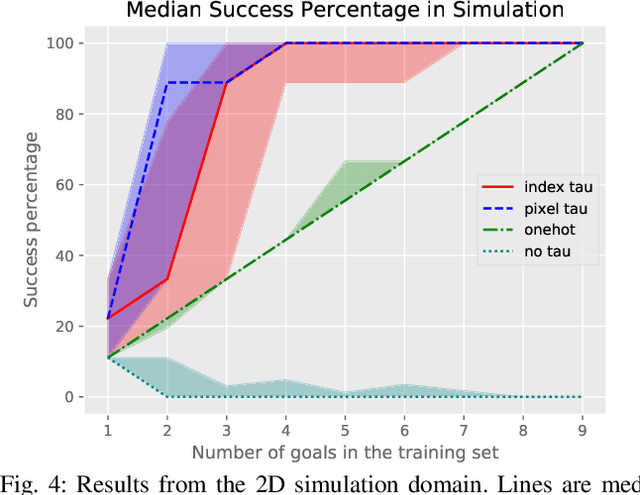
Robots need to learn skills that can not only generalize across similar problems but also be directed to a specific goal. Previous methods either train a new skill for every different goal or do not infer the specific target in the presence of multiple goals from visual data. We introduce an end-to-end method that represents targetable visuomotor skills as a goal-parameterized neural network policy. By training on an informative subset of available goals with the associated target parameters, we are able to learn a policy that can zero-shot generalize to previously unseen goals. We evaluate our method in a representative 2D simulation of a button-grid and on both button-pressing and peg-insertion tasks on two different physical arms. We demonstrate that our model trained on 33% of the possible goals is able to generalize to more than 90% of the targets in the scene for both simulation and robot experiments. We also successfully learn a mapping from target pixel coordinates to a robot policy to complete a specified goal.
Semiparametrical Gaussian Processes Learning of Forward Dynamical Models for Navigating in a Circular Maze
Sep 18, 2018

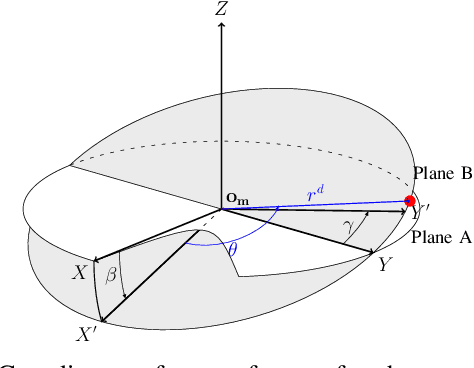
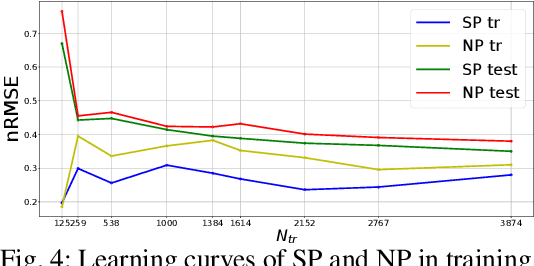
This paper presents a problem of model learning for the purpose of learning how to navigate a ball to a goal state in a circular maze environment with two degrees of freedom. The motion of the ball in the maze environment is influenced by several non-linear effects such as dry friction and contacts, which are difficult to model physically. We propose a semiparametric model to estimate the motion dynamics of the ball based on Gaussian Process Regression equipped with basis functions obtained from physics first principles. The accuracy of this semiparametric model is shown not only in estimation but also in prediction at n-steps ahead and its compared with standard algorithms for model learning. The learned model is then used in a trajectory optimization algorithm to compute ball trajectories. We propose the system presented in the paper as a benchmark problem for reinforcement and robot learning, for its interesting and challenging dynamics and its relative ease of reproducibility.
Sim-to-Real Transfer Learning using Robustified Controllers in Robotic Tasks involving Complex Dynamics
Sep 17, 2018
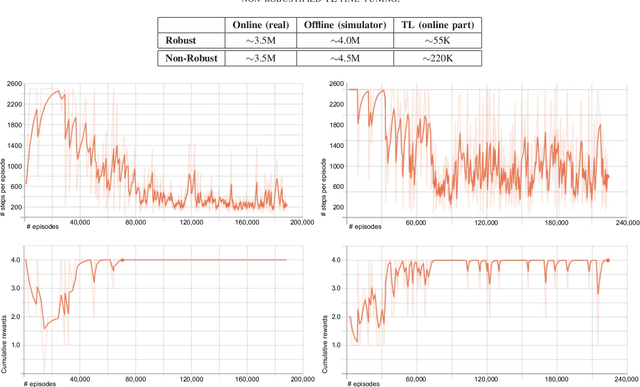
Learning robot tasks or controllers using deep reinforcement learning has been proven effective in simulations. Learning in simulation has several advantages. For example, one can fully control the simulated environment, including halting motions while performing computations. Another advantage when robots are involved, is that the amount of time a robot is occupied learning a task---rather than being productive---can be reduced by transferring the learned task to the real robot. Transfer learning requires some amount of fine-tuning on the real robot. For tasks which involve complex (non-linear) dynamics, the fine-tuning itself may take a substantial amount of time. In order to reduce the amount of fine-tuning we propose to learn robustified controllers in simulation. Robustified controllers are learned by exploiting the ability to change simulation parameters (both appearance and dynamics) for successive training episodes. An additional benefit for this approach is that it alleviates the precise determination of physics parameters for the simulator, which is a non-trivial task. We demonstrate our proposed approach on a real setup in which a robot aims to solve a maze game, which involves complex dynamics due to static friction and potentially large accelerations. We show that the amount of fine-tuning in transfer learning for a robustified controller is substantially reduced compared to a non-robustified controller.