 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Can Learn to Reason Via Off-Policy RL
Feb 22, 2026Reinforcement learning (RL) approaches for Large Language Models (LLMs) frequently use on-policy algorithms, such as PPO or GRPO. However, policy lag from distributed training architectures and differences between the training and inference policies break this assumption, making the data off-policy by design. To rectify this, prior work has focused on making this off-policy data appear more on-policy, either via importance sampling (IS), or by more closely aligning the training and inference policies by explicitly modifying the inference engine. In this work, we embrace off-policyness and propose a novel off-policy RL algorithm that does not require these modifications: Optimal Advantage-based Policy Optimization with Lagged Inference policy (OAPL). We show that OAPL outperforms GRPO with importance sampling on competition math benchmarks, and can match the performance of a publicly available coding model, DeepCoder, on LiveCodeBench, while using 3x fewer generations during training. We further empirically demonstrate that models trained via OAPL have improved test time scaling under the Pass@k metric. OAPL allows for efficient, effective post-training even with lags of more than 400 gradient steps between the training and inference policies, 100x more off-policy than prior approaches.
M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
Apr 14, 2025Effective reasoning is crucial to solving complex mathematical problems. Recent large language models (LLMs) have boosted performance by scaling test-time computation through long chain-of-thought reasoning. However, transformer-based models are inherently limited in extending context length due to their quadratic computational complexity and linear memory requirements. In this paper, we introduce a novel hybrid linear RNN reasoning model, M1, built on the Mamba architecture, which allows memory-efficient inference. Our approach leverages a distillation process from existing reasoning models and is further enhanced through RL training. Experimental results on the AIME and MATH benchmarks show that M1 not only outperforms previous linear RNN models but also matches the performance of state-of-the-art Deepseek R1 distilled reasoning models at a similar scale. We also compare our generation speed with a highly performant general purpose inference engine, vLLM, and observe more than a 3x speedup compared to a same size transformer. With throughput speedup, we are able to achieve higher accuracy compared to DeepSeek R1 distilled transformer reasoning models under a fixed generation time budget using self-consistency voting. Overall, we introduce a hybrid Mamba reasoning model and provide a more effective approach to scaling test-time generation using self-consistency or long chain of thought reasoning.
Learning Finite Linear Temporal Logic Specifications with a Specialized Neural Operator
Nov 21, 2021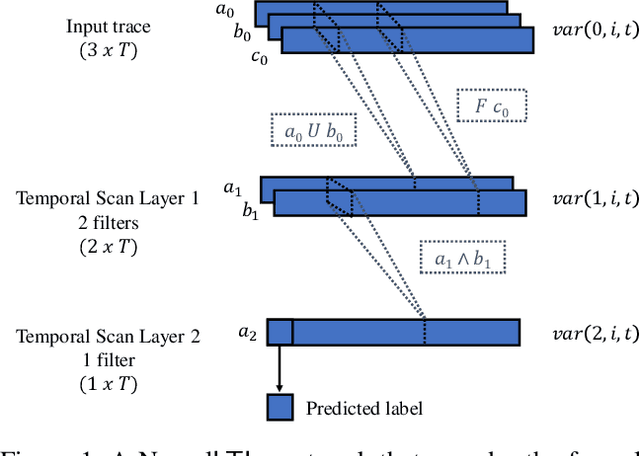
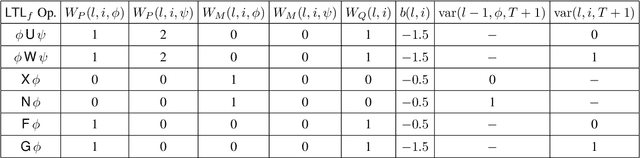

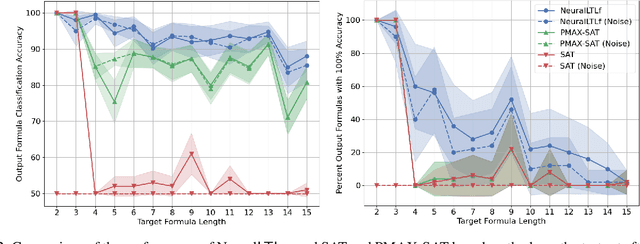
Finite linear temporal logic ($\mathsf{LTL}_f$) is a powerful formal representation for modeling temporal sequences. We address the problem of learning a compact $\mathsf{LTL}_f$ formula from labeled traces of system behavior. We propose a novel neural network operator and evaluate the resulting architecture, Neural$\mathsf{LTL}_f$. Our approach includes a specialized recurrent filter, designed to subsume $\mathsf{LTL}_f$ temporal operators, to learn a highly accurate classifier for traces. Then, it discretizes the activations and extracts the truth table represented by the learned weights. This truth table is converted to symbolic form and returned as the learned formula. Experiments on randomly generated $\mathsf{LTL}_f$ formulas show Neural$\mathsf{LTL}_f$ scales to larger formula sizes than existing approaches and maintains high accuracy even in the presence of noise.
Formalizing Integration Patterns with Multimedia Data (Extended Version)
Sep 09, 2020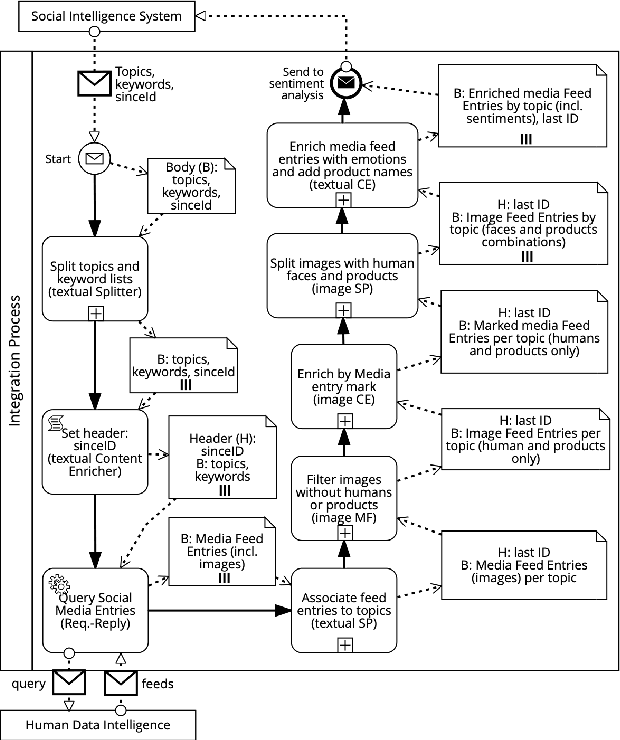
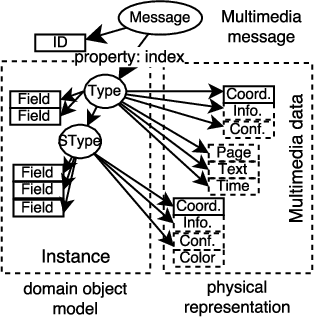
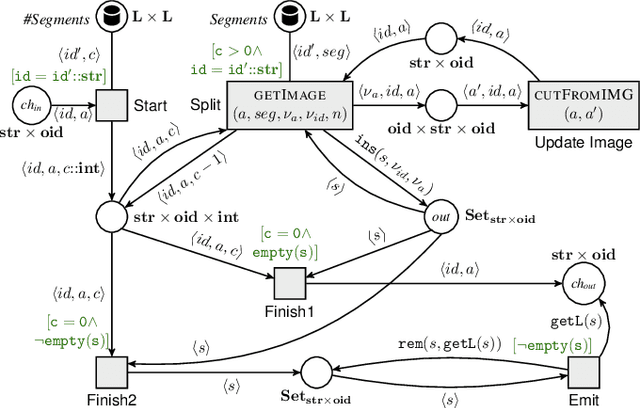
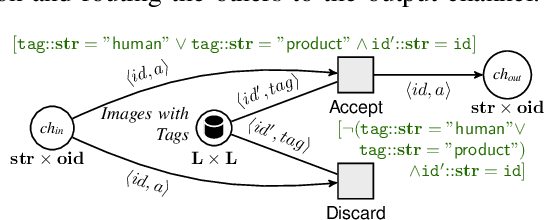
The previous works on formalizing enterprise application integration (EAI) scenarios showed an emerging need for setting up formal foundations for integration patterns, the EAI building blocks, in order to facilitate the model-driven development and ensure its correctness. So far, the formalization requirements were focusing on more "conventional" integration scenarios, in which control-flow, transactional persistent data and time aspects were considered. However, none of these works took into consideration another arising EAI trend that covers social and multimedia computing. In this work we propose a Petri net-based formalism that addresses requirements arising from the multimedia domain. We also demonstrate realizations of one of the most frequently used multimedia patterns and discuss which implications our formal proposal may bring into the area of the multimedia EAI development.
A Logic Programming Approach to Integration Network Inference
Jan 08, 2013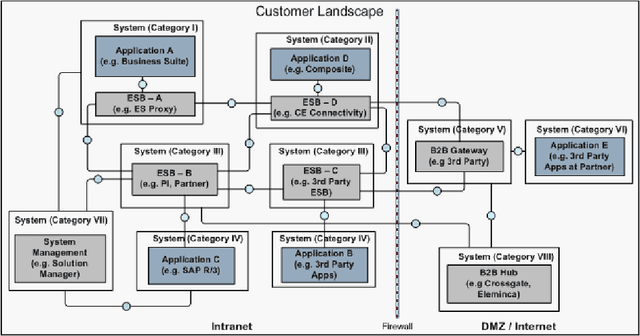

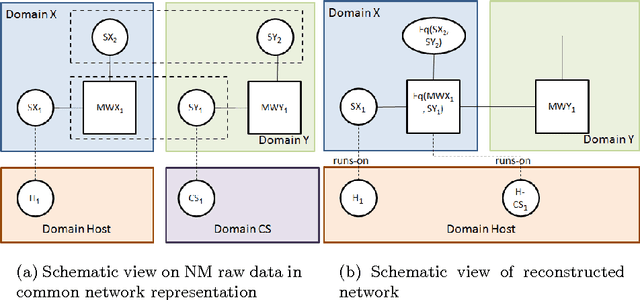

The discovery, representation and reconstruction of (technical) integration networks from Network Mining (NM) raw data is a difficult problem for enterprises. This is due to large and complex IT landscapes within and across enterprise boundaries, heterogeneous technology stacks, and fragmented data. To remain competitive, visibility into the enterprise and partner IT networks on different, interrelated abstraction levels is desirable. We present an approach to represent and reconstruct the integration networks from NM raw data using logic programming based on first-order logic. The raw data expressed as integration network model is represented as facts, on which rules are applied to reconstruct the network. We have built a system that is used to apply this approach to real-world enterprise landscapes and we report on our experience with this system.