 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Efficient Estimation using Monte Carlo Efficient Influence Functions
Mar 08, 2024



Many practical problems involve estimating low dimensional statistical quantities with high-dimensional models and datasets. Several approaches address these estimation tasks based on the theory of influence functions, such as debiased/double ML or targeted minimum loss estimation. This paper introduces \textit{Monte Carlo Efficient Influence Functions} (MC-EIF), a fully automated technique for approximating efficient influence functions that integrates seamlessly with existing differentiable probabilistic programming systems. MC-EIF automates efficient statistical estimation for a broad class of models and target functionals that would previously require rigorous custom analysis. We prove that MC-EIF is consistent, and that estimators using MC-EIF achieve optimal $\sqrt{N}$ convergence rates. We show empirically that estimators using MC-EIF are at parity with estimators using analytic EIFs. Finally, we demonstrate a novel capstone example using MC-EIF for optimal portfolio selection.
A Simulation-Based Test of Identifiability for Bayesian Causal Inference
Feb 23, 2021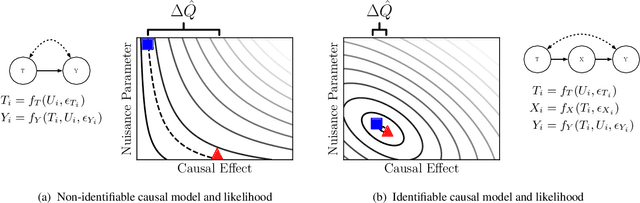

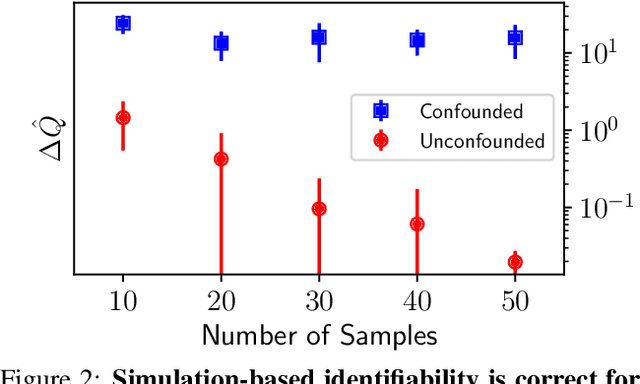
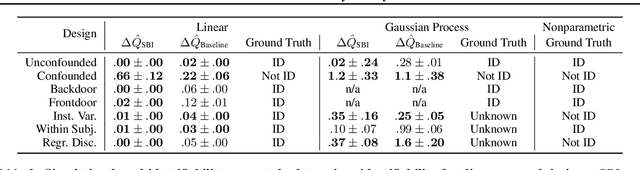
This paper introduces a procedure for testing the identifiability of Bayesian models for causal inference. Although the do-calculus is sound and complete given a causal graph, many practical assumptions cannot be expressed in terms of graph structure alone, such as the assumptions required by instrumental variable designs, regression discontinuity designs, and within-subjects designs. We present simulation-based identifiability (SBI), a fully automated identification test based on a particle optimization scheme with simulated observations. This approach expresses causal assumptions as priors over functions in a structural causal model, including flexible priors using Gaussian processes. We prove that SBI is asymptotically sound and complete, and produces practical finite-sample bounds. We also show empirically that SBI agrees with known results in graph-based identification as well as with widely-held intuitions for designs in which graph-based methods are inconclusive.
Fairkit, Fairkit, on the Wall, Who's the Fairest of Them All? Supporting Data Scientists in Training Fair Models
Dec 17, 2020
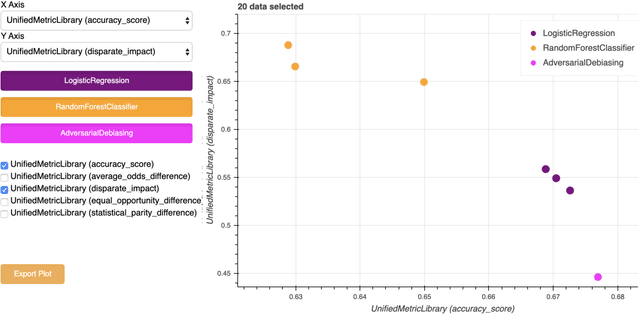
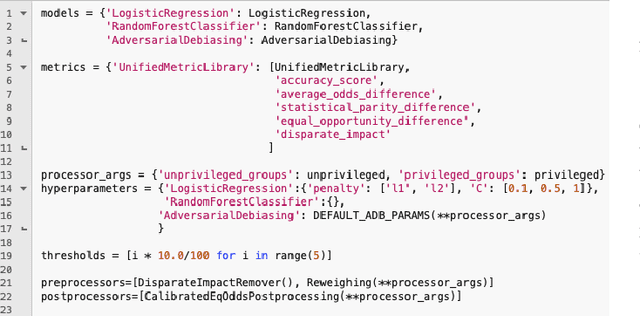

Modern software relies heavily on data and machine learning, and affects decisions that shape our world. Unfortunately, recent studies have shown that because of biases in data, software systems frequently inject bias into their decisions, from producing better closed caption transcriptions of men's voices than of women's voices to overcharging people of color for financial loans. To address bias in machine learning, data scientists need tools that help them understand the trade-offs between model quality and fairness in their specific data domains. Toward that end, we present fairkit-learn, a toolkit for helping data scientists reason about and understand fairness. Fairkit-learn works with state-of-the-art machine learning tools and uses the same interfaces to ease adoption. It can evaluate thousands of models produced by multiple machine learning algorithms, hyperparameters, and data permutations, and compute and visualize a small Pareto-optimal set of models that describe the optimal trade-offs between fairness and quality. We evaluate fairkit-learn via a user study with 54 students, showing that students using fairkit-learn produce models that provide a better balance between fairness and quality than students using scikit-learn and IBM AI Fairness 360 toolkits. With fairkit-learn, users can select models that are up to 67% more fair and 10% more accurate than the models they are likely to train with scikit-learn.
Causal Inference using Gaussian Processes with Structured Latent Confounders
Jul 14, 2020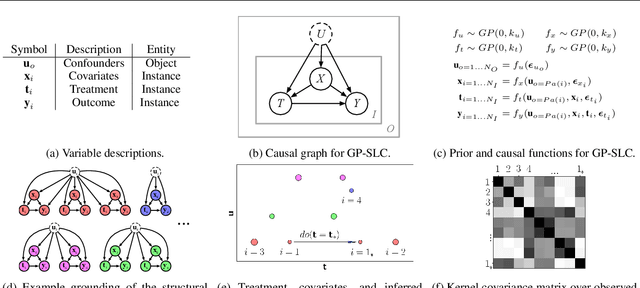
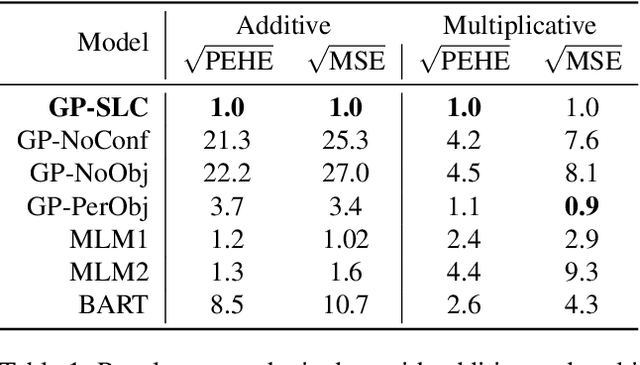
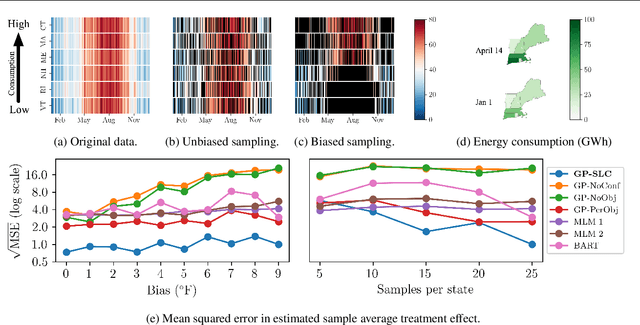
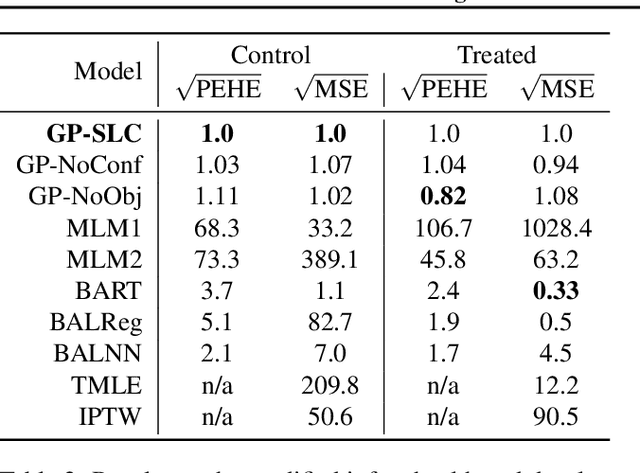
Latent confounders---unobserved variables that influence both treatment and outcome---can bias estimates of causal effects. In some cases, these confounders are shared across observations, e.g. all students taking a course are influenced by the course's difficulty in addition to any educational interventions they receive individually. This paper shows how to semiparametrically model latent confounders that have this structure and thereby improve estimates of causal effects. The key innovations are a hierarchical Bayesian model, Gaussian processes with structured latent confounders (GP-SLC), and a Monte Carlo inference algorithm for this model based on elliptical slice sampling. GP-SLC provides principled Bayesian uncertainty estimates of individual treatment effect with minimal assumptions about the functional forms relating confounders, covariates, treatment, and outcome. Finally, this paper shows GP-SLC is competitive with or more accurate than widely used causal inference techniques on three benchmark datasets, including the Infant Health and Development Program and a dataset showing the effect of changing temperatures on state-wide energy consumption across New England.
Bayesian causal inference via probabilistic program synthesis
Oct 30, 2019



Causal inference can be formalized as Bayesian inference that combines a prior distribution over causal models and likelihoods that account for both observations and interventions. We show that it is possible to implement this approach using a sufficiently expressive probabilistic programming language. Priors are represented using probabilistic programs that generate source code in a domain specific language. Interventions are represented using probabilistic programs that edit this source code to modify the original generative process. This approach makes it straightforward to incorporate data from atomic interventions, as well as shift interventions, variance-scaling interventions, and other interventions that modify causal structure. This approach also enables the use of general-purpose inference machinery for probabilistic programs to infer probable causal structures and parameters from data. This abstract describes a prototype of this approach in the Gen probabilistic programming language.
Measuring and Characterizing Generalization in Deep Reinforcement Learning
Dec 11, 2018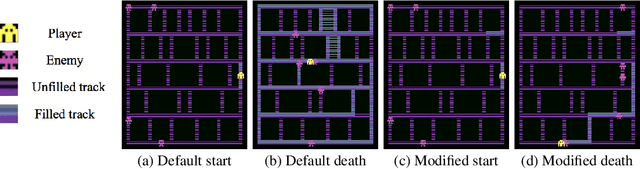
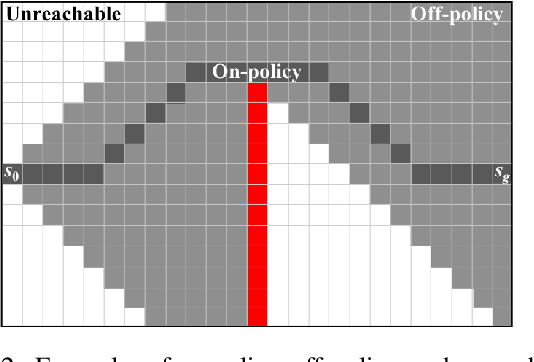
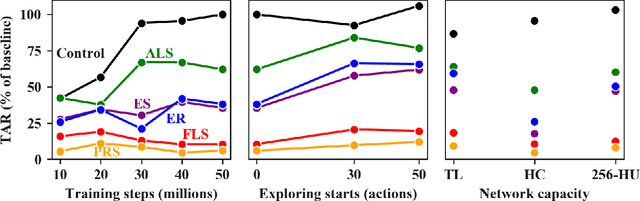
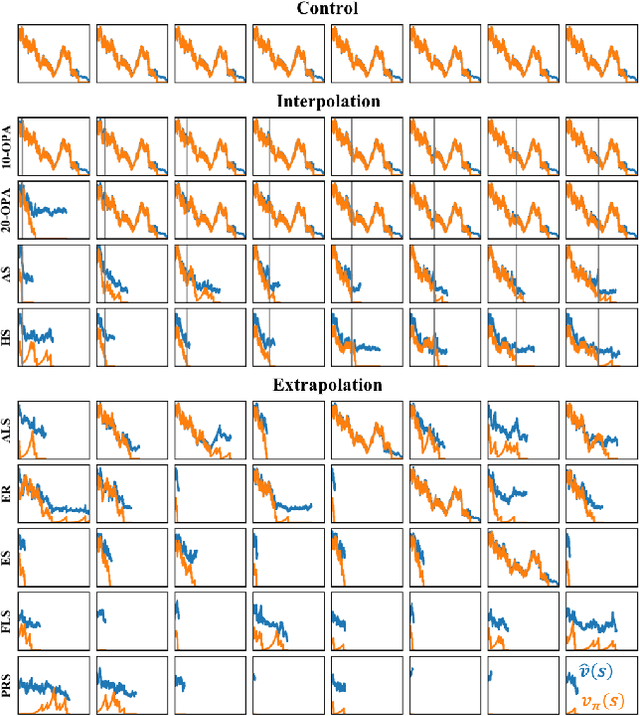
Deep reinforcement-learning methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. Taken together, these results call into question the extent to which deep Q-networks learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.