 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Learn Formal Logic? A Data-Driven Training and Evaluation Framework
Apr 28, 2025



This paper investigates the logical reasoning capabilities of large language models (LLMs). For a precisely defined yet tractable formulation, we choose the conceptually simple but technically complex task of constructing proofs in Boolean logic. A trained LLM receives as input a set of assumptions and a goal, and produces as output a proof that formally derives the goal from the assumptions. Incorrect proofs are caught by an automated proof checker. A critical obstacle for training is the scarcity of real-world proofs. We propose an efficient, randomized procedure for synthesizing valid proofs and introduce Template Transformation, a data augmentation technique that enhances the model's ability to handle complex logical expressions. The central evaluation question is whether an LLM has indeed learned to reason. We propose tests to measure the reasoning ability of a black-box LLM. By these measures, experiments demonstrate strong reasoning capabilities for assertions with short proofs, which decline with proof complexity. Notably, template transformation improves accuracy even for smaller models, suggesting its effectiveness across model scales.
SODA: Protecting Proprietary Information in On-Device Machine Learning Models
Dec 22, 2023



The growth of low-end hardware has led to a proliferation of machine learning-based services in edge applications. These applications gather contextual information about users and provide some services, such as personalized offers, through a machine learning (ML) model. A growing practice has been to deploy such ML models on the user's device to reduce latency, maintain user privacy, and minimize continuous reliance on a centralized source. However, deploying ML models on the user's edge device can leak proprietary information about the service provider. In this work, we investigate on-device ML models that are used to provide mobile services and demonstrate how simple attacks can leak proprietary information of the service provider. We show that different adversaries can easily exploit such models to maximize their profit and accomplish content theft. Motivated by the need to thwart such attacks, we present an end-to-end framework, SODA, for deploying and serving on edge devices while defending against adversarial usage. Our results demonstrate that SODA can detect adversarial usage with 89% accuracy in less than 50 queries with minimal impact on service performance, latency, and storage.
Preserving Privacy in Personalized Models for Distributed Mobile Services
Jan 14, 2021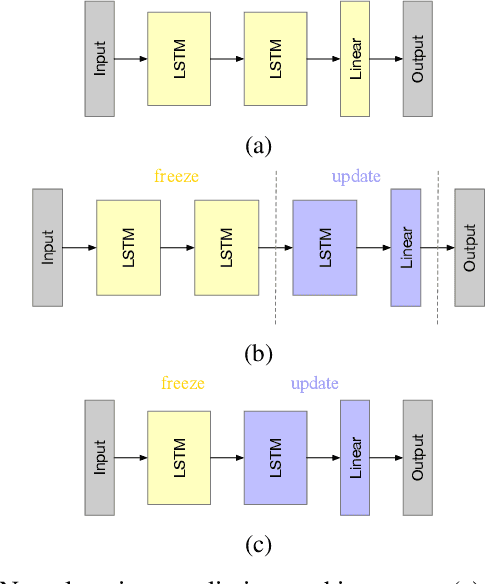
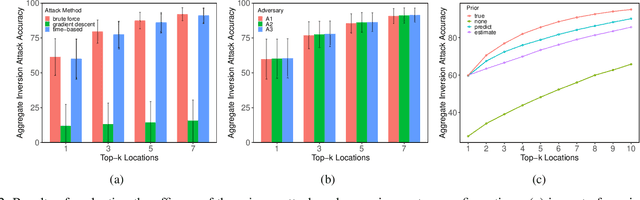
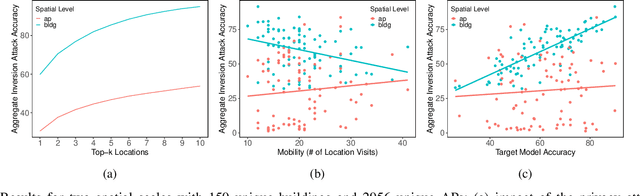
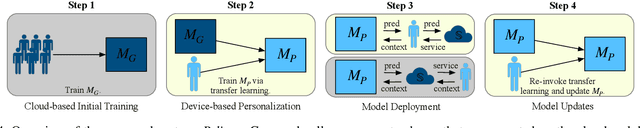
The ubiquity of mobile devices has led to the proliferation of mobile services that provide personalized and context-aware content to their users. Modern mobile services are distributed between end-devices, such as smartphones, and remote servers that reside in the cloud. Such services thrive on their ability to predict future contexts to pre-fetch content of make context-specific recommendations. An increasingly common method to predict future contexts, such as location, is via machine learning (ML) models. Recent work in context prediction has focused on ML model personalization where a personalized model is learned for each individual user in order to tailor predictions or recommendations to a user's mobile behavior. While the use of personalized models increases efficacy of the mobile service, we argue that it increases privacy risk since a personalized model encodes contextual behavior unique to each user. To demonstrate these privacy risks, we present several attribute inference-based privacy attacks and show that such attacks can leak privacy with up to 78% efficacy for top-3 predictions. We present Pelican, a privacy-preserving personalization system for context-aware mobile services that leverages both device and cloud resources to personalize ML models while minimizing the risk of privacy leakage for users. We evaluate Pelican using real world traces for location-aware mobile services and show that Pelican can substantially reduce privacy leakage by up to 75%.
Exploratory Not Explanatory: Counterfactual Analysis of Saliency Maps for Deep RL
Dec 09, 2019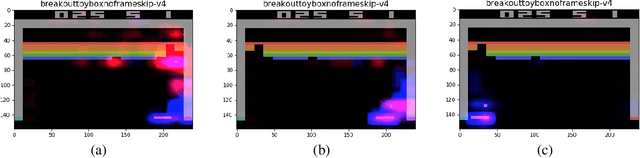
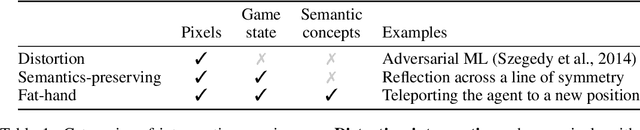
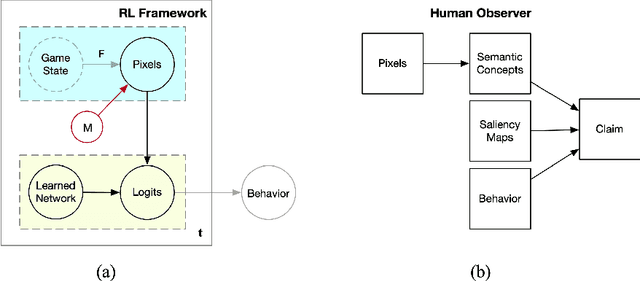
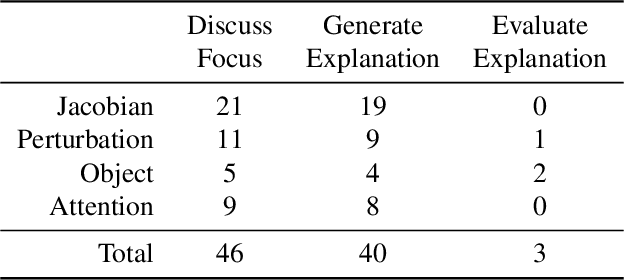
Saliency maps have been used to support explanations of deep reinforcement learning (RL) agent behavior over temporally extended sequences. However, their use in the community indicates that the explanations derived from saliency maps are often unfalsifiable and can be highly subjective. We introduce an empirical approach grounded in counterfactual reasoning to test the hypotheses generated from saliency maps and assess the degree to which saliency maps represent semantics of RL environments. We evaluate three types of saliency maps using Atari games, a common benchmark for deep RL. Our results show the extent to which existing claims about Atari games can be evaluated and suggest that saliency maps are an exploratory tool not an explanatory tool.
Measuring and Characterizing Generalization in Deep Reinforcement Learning
Dec 11, 2018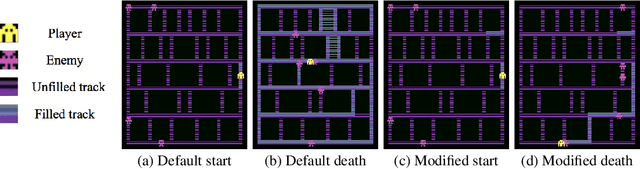
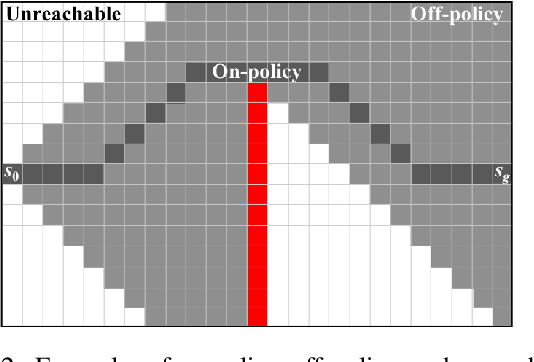
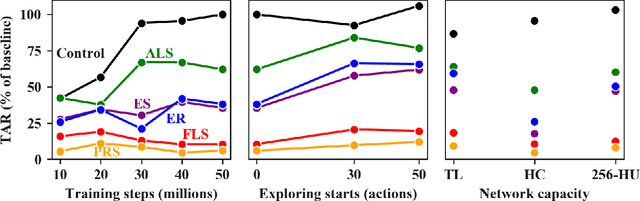
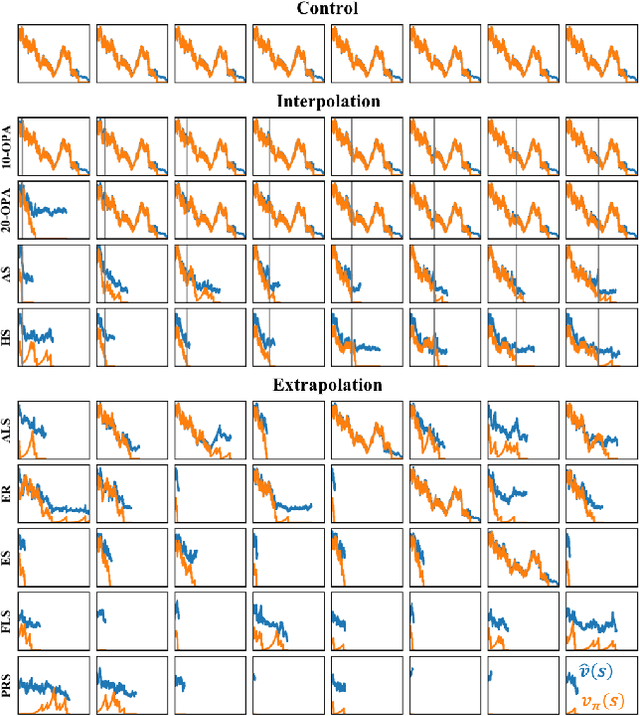
Deep reinforcement-learning methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. Taken together, these results call into question the extent to which deep Q-networks learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.