 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Learn Formal Logic? A Data-Driven Training and Evaluation Framework
Apr 28, 2025



This paper investigates the logical reasoning capabilities of large language models (LLMs). For a precisely defined yet tractable formulation, we choose the conceptually simple but technically complex task of constructing proofs in Boolean logic. A trained LLM receives as input a set of assumptions and a goal, and produces as output a proof that formally derives the goal from the assumptions. Incorrect proofs are caught by an automated proof checker. A critical obstacle for training is the scarcity of real-world proofs. We propose an efficient, randomized procedure for synthesizing valid proofs and introduce Template Transformation, a data augmentation technique that enhances the model's ability to handle complex logical expressions. The central evaluation question is whether an LLM has indeed learned to reason. We propose tests to measure the reasoning ability of a black-box LLM. By these measures, experiments demonstrate strong reasoning capabilities for assertions with short proofs, which decline with proof complexity. Notably, template transformation improves accuracy even for smaller models, suggesting its effectiveness across model scales.
Confidence-Guided Data Augmentation for Deep Semi-Supervised Training
Sep 16, 2022



We propose a new data augmentation technique for semi-supervised learning settings that emphasizes learning from the most challenging regions of the feature space. Starting with a fully supervised reference model, we first identify low confidence predictions. These samples are then used to train a Variational AutoEncoder (VAE) that can generate an infinite number of additional images with similar distribution. Finally, using the originally labeled data and the synthetically generated labeled and unlabeled data, we retrain a new model in a semi-supervised fashion. We perform experiments on two benchmark RGB datasets: CIFAR-100 and STL-10, and show that the proposed scheme improves classification performance in terms of accuracy and robustness, while yielding comparable or superior results with respect to existing fully supervised approaches
An Unsupervised Machine Learning Approach to Assess the ZIP Code Level Impact of COVID-19 in NYC
Jun 11, 2020


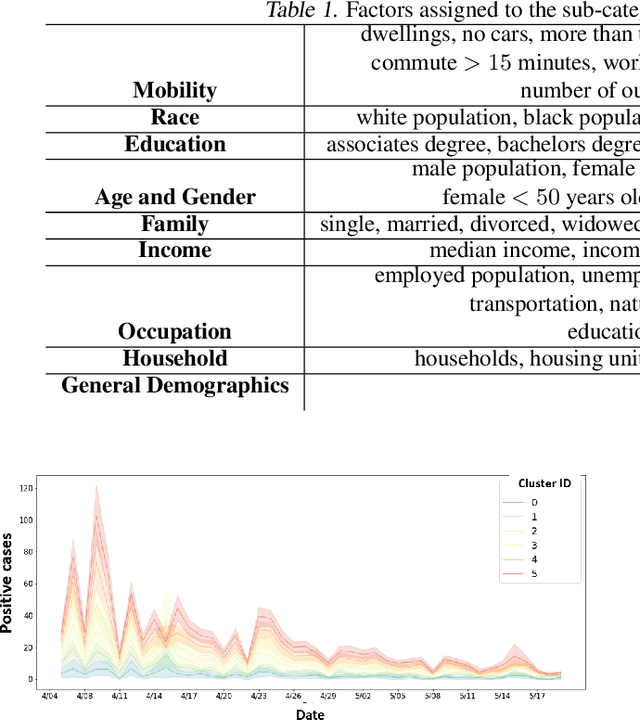
New York City has been recognized as the world's epicenter of the novel Coronavirus pandemic. To identify the key inherent factors that are highly correlated to the Increase Rate of COVID-19 new cases in NYC, we propose an unsupervised machine learning framework. Based on the assumption that ZIP code areas with similar demographic, socioeconomic, and mobility patterns are likely to experience similar outbreaks, we select the most relevant features to perform a clustering that can best reflect the spread, and map them down to 9 interpretable categories. We believe that our findings can guide policy makers to promptly anticipate and prevent the spread of the virus by taking the right measures.