 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairkit, Fairkit, on the Wall, Who's the Fairest of Them All? Supporting Data Scientists in Training Fair Models
Dec 17, 2020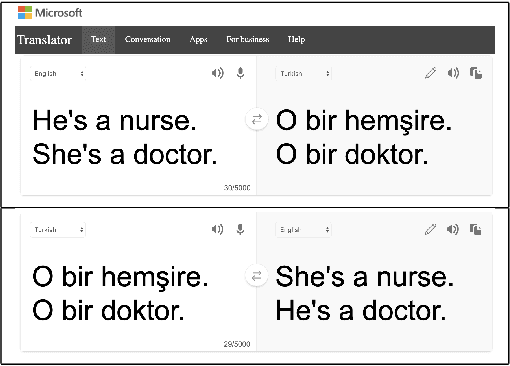
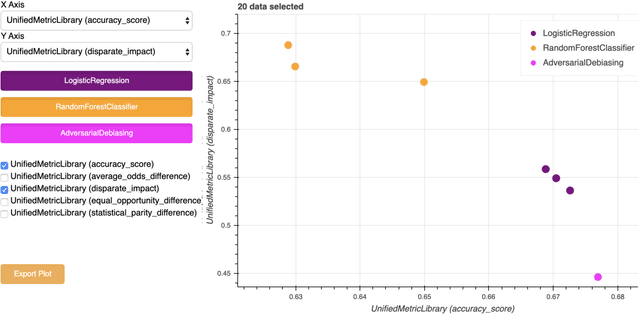
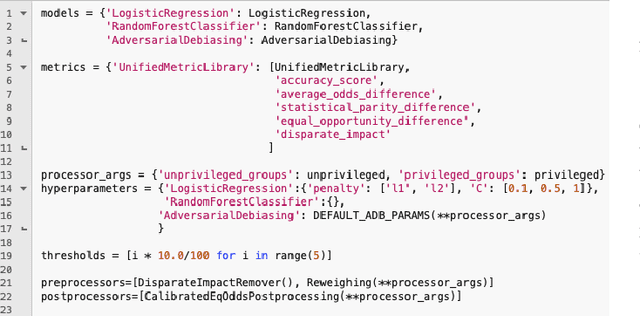

Modern software relies heavily on data and machine learning, and affects decisions that shape our world. Unfortunately, recent studies have shown that because of biases in data, software systems frequently inject bias into their decisions, from producing better closed caption transcriptions of men's voices than of women's voices to overcharging people of color for financial loans. To address bias in machine learning, data scientists need tools that help them understand the trade-offs between model quality and fairness in their specific data domains. Toward that end, we present fairkit-learn, a toolkit for helping data scientists reason about and understand fairness. Fairkit-learn works with state-of-the-art machine learning tools and uses the same interfaces to ease adoption. It can evaluate thousands of models produced by multiple machine learning algorithms, hyperparameters, and data permutations, and compute and visualize a small Pareto-optimal set of models that describe the optimal trade-offs between fairness and quality. We evaluate fairkit-learn via a user study with 54 students, showing that students using fairkit-learn produce models that provide a better balance between fairness and quality than students using scikit-learn and IBM AI Fairness 360 toolkits. With fairkit-learn, users can select models that are up to 67% more fair and 10% more accurate than the models they are likely to train with scikit-learn.