 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning from Policy-Dependent Human Feedback
Feb 12, 2019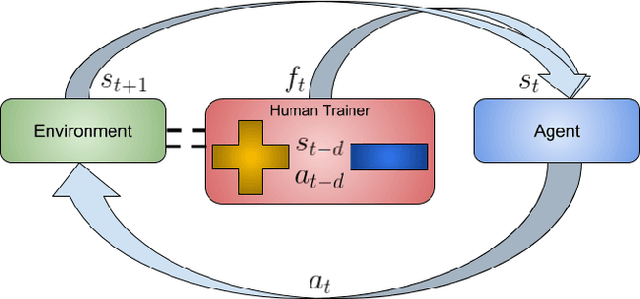
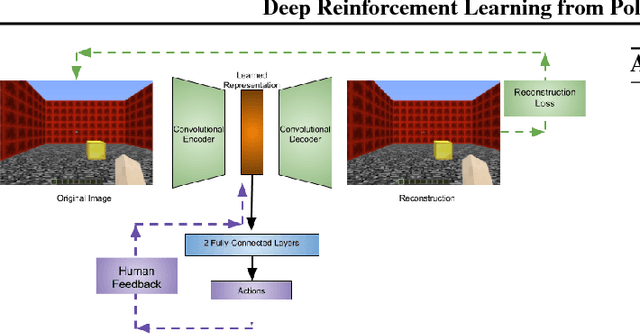

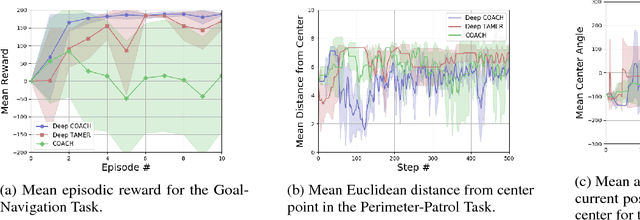
To widen their accessibility and increase their utility, intelligent agents must be able to learn complex behaviors as specified by (non-expert) human users. Moreover, they will need to learn these behaviors within a reasonable amount of time while efficiently leveraging the sparse feedback a human trainer is capable of providing. Recent work has shown that human feedback can be characterized as a critique of an agent's current behavior rather than as an alternative reward signal to be maximized, culminating in the COnvergent Actor-Critic by Humans (COACH) algorithm for making direct policy updates based on human feedback. Our work builds on COACH, moving to a setting where the agent's policy is represented by a deep neural network. We employ a series of modifications on top of the original COACH algorithm that are critical for successfully learning behaviors from high-dimensional observations, while also satisfying the constraint of obtaining reduced sample complexity. We demonstrate the effectiveness of our Deep COACH algorithm in the rich 3D world of Minecraft with an agent that learns to complete tasks by mapping from raw pixels to actions using only real-time human feedback in 10-15 minutes of interaction.