 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterplay: Training Independent Simulators for Reference-Free Conversational Recommendation
Mar 19, 2026Training conversational recommender systems (CRS) requires extensive dialogue data, which is challenging to collect at scale. To address this, researchers have used simulated user-recommender conversations. Traditional simulation approaches often utilize a single large language model (LLM) that generates entire conversations with prior knowledge of the target items, leading to scripted and artificial dialogues. We propose a reference-free simulation framework that trains two independent LLMs, one as the user and one as the conversational recommender. These models interact in real-time without access to predetermined target items, but preference summaries and target attributes, enabling the recommender to genuinely infer user preferences through dialogue. This approach produces more realistic and diverse conversations that closely mirror authentic human-AI interactions. Our reference-free simulators match or exceed existing methods in quality, while offering a scalable solution for generating high-quality conversational recommendation data without constraining conversations to pre-defined target items. We conduct both quantitative and human evaluations to confirm the effectiveness of our reference-free approach.
Preference Distillation for Personalized Generative Recommendation
Jul 06, 2024



Recently, researchers have investigated the capabilities of Large Language Models (LLMs) for generative recommender systems. Existing LLM-based recommender models are trained by adding user and item IDs to a discrete prompt template. However, the disconnect between IDs and natural language makes it difficult for the LLM to learn the relationship between users. To address this issue, we propose a PErsonAlized PrOmpt Distillation (PeaPOD) approach, to distill user preferences as personalized soft prompts. Considering the complexities of user preferences in the real world, we maintain a shared set of learnable prompts that are dynamically weighted based on the user's interests to construct the user-personalized prompt in a compositional manner. Experimental results on three real-world datasets demonstrate the effectiveness of our PeaPOD model on sequential recommendation, top-n recommendation, and explanation generation tasks.
Natural Language User Profiles for Transparent and Scrutable Recommendations
Feb 08, 2024Current state-of-the-art recommender systems predominantly rely on either implicit or explicit feedback from users to suggest new items. While effective in recommending novel options, these conventional systems often use uninterpretable embeddings. This lack of transparency not only limits user understanding of why certain items are suggested but also reduces the user's ability to easily scrutinize and edit their preferences. For example, if a user has a change in interests, they would need to make significant changes to their interaction history to adjust the model's recommendations. To address these limitations, we introduce a novel method that utilizes user reviews to craft personalized, natural language profiles describing users' preferences. Through these descriptive profiles, our system provides transparent recommendations in natural language. Our evaluations show that this novel approach maintains a performance level on par with established recommender systems, but with the added benefits of transparency and user control. By enabling users to scrutinize why certain items are recommended, they can more easily verify, adjust, and have greater autonomy over their recommendations.
When and What to Ask Through World States and Text Instructions: IGLU NLP Challenge Solution
May 09, 2023In collaborative tasks, effective communication is crucial for achieving joint goals. One such task is collaborative building where builders must communicate with each other to construct desired structures in a simulated environment such as Minecraft. We aim to develop an intelligent builder agent to build structures based on user input through dialogue. However, in collaborative building, builders may encounter situations that are difficult to interpret based on the available information and instructions, leading to ambiguity. In the NeurIPS 2022 Competition NLP Task, we address two key research questions, with the goal of filling this gap: when should the agent ask for clarification, and what clarification questions should it ask? We move towards this target with two sub-tasks, a classification task and a ranking task. For the classification task, the goal is to determine whether the agent should ask for clarification based on the current world state and dialogue history. For the ranking task, the goal is to rank the relevant clarification questions from a pool of candidates. In this report, we briefly introduce our methods for the classification and ranking task. For the classification task, our model achieves an F1 score of 0.757, which placed the 3rd on the leaderboard. For the ranking task, our model achieves about 0.38 for Mean Reciprocal Rank by extending the traditional ranking model. Lastly, we discuss various neural approaches for the ranking task and future direction.
Stackelberg Punishment and Bully-Proofing Autonomous Vehicles
Aug 23, 2019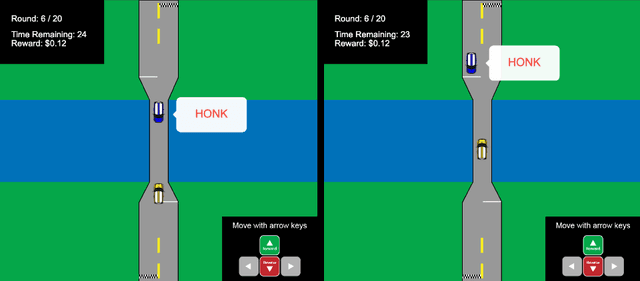
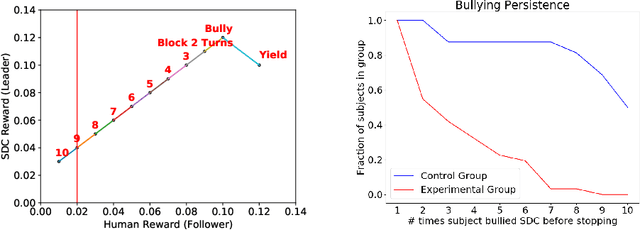
Mutually beneficial behavior in repeated games can be enforced via the threat of punishment, as enshrined in game theory's well-known "folk theorem." There is a cost, however, to a player for generating these disincentives. In this work, we seek to minimize this cost by computing a "Stackelberg punishment," in which the player selects a behavior that sufficiently punishes the other player while maximizing its own score under the assumption that the other player will adopt a best response. This idea generalizes the concept of a Stackelberg equilibrium. Known efficient algorithms for computing a Stackelberg equilibrium can be adapted to efficiently produce a Stackelberg punishment. We demonstrate an application of this idea in an experiment involving a virtual autonomous vehicle and human participants. We find that a self-driving car with a Stackelberg punishment policy discourages human drivers from bullying in a driving scenario requiring social negotiation.