 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Entrainment for Conversational Systems
Oct 14, 2023Conversational agents have become ubiquitous in assisting with daily tasks, and are expected to possess human-like features. One such feature is lexical entrainment (LE), a phenomenon in which speakers in human-human conversations tend to naturally and subconsciously align their lexical choices with those of their interlocutors, leading to more successful and engaging conversations. As an example, if a digital assistant replies 'Your appointment for Jinling Noodle Pub is at 7 pm' to the question 'When is my reservation for Jinling Noodle Bar today?', it may feel as though the assistant is trying to correct the speaker, whereas a response of 'Your reservation for Jinling Noodle Bar is at 7 pm' would likely be perceived as more positive. This highlights the importance of LE in establishing a shared terminology for maximum clarity and reducing ambiguity in conversations. However, we demonstrate in this work that current response generation models do not adequately address this crucial humanlike phenomenon. To address this, we propose a new dataset, named MULTIWOZ-ENTR, and a measure for LE for conversational systems. Additionally, we suggest a way to explicitly integrate LE into conversational systems with two new tasks, a LE extraction task and a LE generation task. We also present two baseline approaches for the LE extraction task, which aim to detect LE expressions from dialogue contexts.
DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning
Sep 11, 2023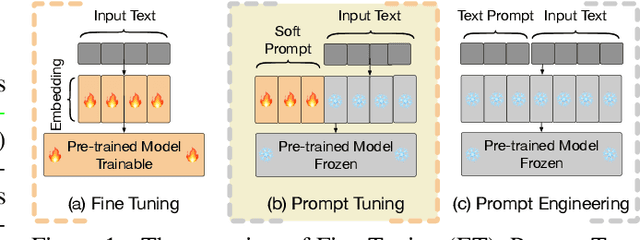
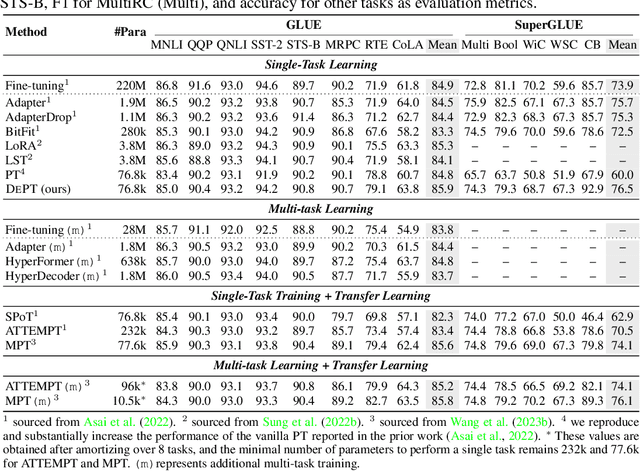
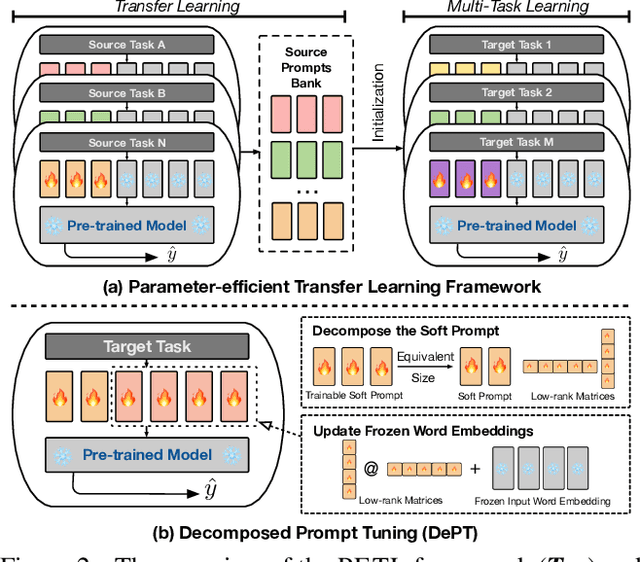
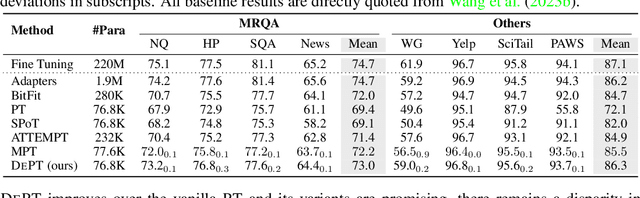
Prompt tuning (PT), where a small amount of trainable soft (continuous) prompt vectors is affixed to the input of language models (LM), has shown promising results across various tasks and models for parameter-efficient fine-tuning (PEFT). PT stands out from other PEFT approaches because it maintains competitive performance with fewer trainable parameters and does not drastically scale up its parameters as the model size expands. However, PT introduces additional soft prompt tokens, leading to longer input sequences, which significantly impacts training and inference time and memory usage due to the Transformer's quadratic complexity. Particularly concerning for Large Language Models (LLMs) that face heavy daily querying. To address this issue, we propose Decomposed Prompt Tuning (DePT), which decomposes the soft prompt into a shorter soft prompt and a pair of low-rank matrices that are then optimised with two different learning rates. This allows DePT to achieve better performance while saving over 20% memory and time costs compared to vanilla PT and its variants, without changing trainable parameter sizes. Through extensive experiments on 23 natural language processing (NLP) and vision-language (VL) tasks, we demonstrate that DePT outperforms state-of-the-art PEFT approaches, including the full fine-tuning baseline in some scenarios. Additionally, we empirically show that DEPT grows more efficient as the model size increases. Our further study reveals that DePT integrates seamlessly with parameter-efficient transfer learning in the few-shot learning setting and highlights its adaptability to various model architectures and sizes.
Rethink the Effectiveness of Text Data Augmentation: An Empirical Analysis
Jun 13, 2023



In recent years, language models (LMs) have made remarkable progress in advancing the field of natural language processing (NLP). However, the impact of data augmentation (DA) techniques on the fine-tuning (FT) performance of these LMs has been a topic of ongoing debate. In this study, we evaluate the effectiveness of three different FT methods in conjugation with back-translation across an array of 7 diverse NLP tasks, including classification and regression types, covering single-sentence and sentence-pair tasks. Contrary to prior assumptions that DA does not contribute to the enhancement of LMs' FT performance, our findings reveal that continued pre-training on augmented data can effectively improve the FT performance of the downstream tasks. In the most favourable case, continued pre-training improves the performance of FT by more than 10% in the few-shot learning setting. Our finding highlights the potential of DA as a powerful tool for bolstering LMs' performance.
Self Contrastive Learning for Session-based Recommendation
Jun 02, 2023



Session-based recommendation, which aims to predict the next item of users' interest as per an existing sequence interaction of items, has attracted growing applications of Contrastive Learning (CL) with improved user and item representations. However, these contrastive objectives: (1) serve a similar role as the cross-entropy loss while ignoring the item representation space optimisation; and (2) commonly require complicated modelling, including complex positive/negative sample constructions and extra data augmentation. In this work, we introduce Self-Contrastive Learning (SCL), which simplifies the application of CL and enhances the performance of state-of-the-art CL-based recommendation techniques. Specifically, SCL is formulated as an objective function that directly promotes a uniform distribution among item representations and efficiently replaces all the existing contrastive objective components of state-of-the-art models. Unlike previous works, SCL eliminates the need for any positive/negative sample construction or data augmentation, leading to enhanced interpretability of the item representation space and facilitating its extensibility to existing recommender systems. Through experiments on three benchmark datasets, we demonstrate that SCL consistently improves the performance of state-of-the-art models with statistical significance. Notably, our experiments show that SCL improves the performance of two best-performing models by 8.2% and 9.5% in P@10 (Precision) and 9.9% and 11.2% in MRR@10 (Mean Reciprocal Rank) on average across different benchmarks. Additionally, our analysis elucidates the improvement in terms of alignment and uniformity of representations, as well as the effectiveness of SCL with a low computational cost.
Rethinking Semi-supervised Learning with Language Models
May 22, 2023



Semi-supervised learning (SSL) is a popular setting aiming to effectively utilize unlabelled data to improve model performance in downstream natural language processing (NLP) tasks. Currently, there are two popular approaches to make use of unlabelled data: Self-training (ST) and Task-adaptive pre-training (TAPT). ST uses a teacher model to assign pseudo-labels to the unlabelled data, while TAPT continues pre-training on the unlabelled data before fine-tuning. To the best of our knowledge, the effectiveness of TAPT in SSL tasks has not been systematically studied, and no previous work has directly compared TAPT and ST in terms of their ability to utilize the pool of unlabelled data. In this paper, we provide an extensive empirical study comparing five state-of-the-art ST approaches and TAPT across various NLP tasks and data sizes, including in- and out-of-domain settings. Surprisingly, we find that TAPT is a strong and more robust SSL learner, even when using just a few hundred unlabelled samples or in the presence of domain shifts, compared to more sophisticated ST approaches, and tends to bring greater improvements in SSL than in fully-supervised settings. Our further analysis demonstrates the risks of using ST approaches when the size of labelled or unlabelled data is small or when domain shifts exist. We offer a fresh perspective for future SSL research, suggesting the use of unsupervised pre-training objectives over dependency on pseudo labels.
When and What to Ask Through World States and Text Instructions: IGLU NLP Challenge Solution
May 09, 2023In collaborative tasks, effective communication is crucial for achieving joint goals. One such task is collaborative building where builders must communicate with each other to construct desired structures in a simulated environment such as Minecraft. We aim to develop an intelligent builder agent to build structures based on user input through dialogue. However, in collaborative building, builders may encounter situations that are difficult to interpret based on the available information and instructions, leading to ambiguity. In the NeurIPS 2022 Competition NLP Task, we address two key research questions, with the goal of filling this gap: when should the agent ask for clarification, and what clarification questions should it ask? We move towards this target with two sub-tasks, a classification task and a ranking task. For the classification task, the goal is to determine whether the agent should ask for clarification based on the current world state and dialogue history. For the ranking task, the goal is to rank the relevant clarification questions from a pool of candidates. In this report, we briefly introduce our methods for the classification and ranking task. For the classification task, our model achieves an F1 score of 0.757, which placed the 3rd on the leaderboard. For the ranking task, our model achieves about 0.38 for Mean Reciprocal Rank by extending the traditional ranking model. Lastly, we discuss various neural approaches for the ranking task and future direction.
Don't Stop Pretraining? Make Prompt-based Fine-tuning Powerful Learner
May 02, 2023Language models (LMs) trained on vast quantities of unlabelled data have greatly advanced the field of natural language processing (NLP). In this study, we re-visit the widely accepted notion in NLP that continued pre-training LMs on task-related texts improves the performance of fine-tuning (FT) in downstream tasks. Through experiments on eight single-sentence tasks and eight sentence-pair tasks in both semi-supervised and fully-supervised settings, we find that conventional continued pre-training does not consistently provide benefits and can even be detrimental for sentence-pair tasks or when prompt-based FT is used. To tackle these issues, we propose Prompt-based Continued Pre-training (PCP), which combines the idea of instruction tuning with conventional continued pre-training. Our approach aims to improve the performance of prompt-based FT by presenting both task-related texts and prompt templates to LMs through unsupervised pre-training objectives before fine-tuning for the target task. Our empirical evaluations on 21 benchmarks demonstrate that the PCP consistently improves the performance of state-of-the-art prompt-based FT approaches (up to 20.1% absolute) in both semi-supervised and fully-supervised settings, even with only hundreds of unlabelled examples. Additionally, prompt-based FT with the PCP outperforms state-of-the-art semi-supervised approaches with greater simplicity, eliminating the need for an iterative process and extra data augmentation. Our further analysis explores the performance lower bound of the PCP and reveals that the advantages of PCP persist across different sizes of models and datasets.
Attention-based Ingredient Phrase Parser
Oct 05, 2022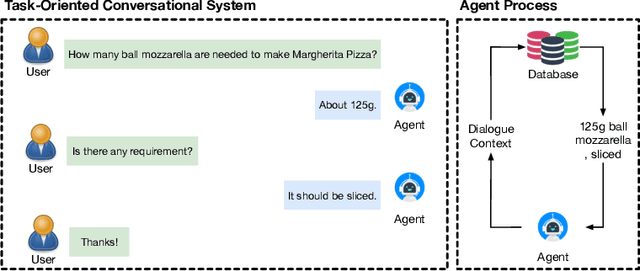
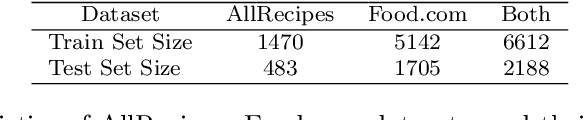
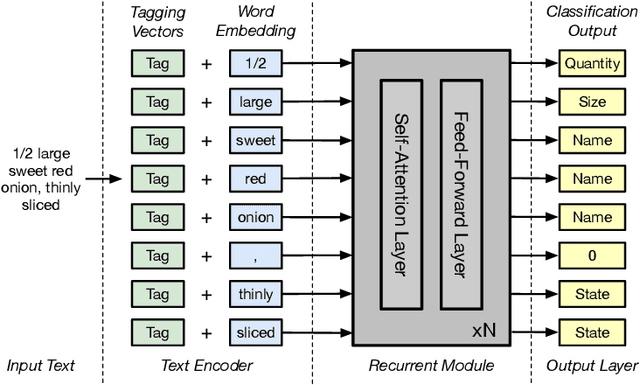
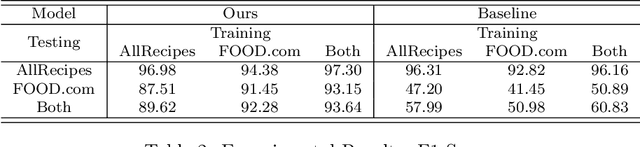
As virtual personal assistants have now penetrated the consumer market, with products such as Siri and Alexa, the research community has produced several works on task-oriented dialogue tasks such as hotel booking, restaurant booking, and movie recommendation. Assisting users to cook is one of these tasks that are expected to be solved by intelligent assistants, where ingredients and their corresponding attributes, such as name, unit, and quantity, should be provided to users precisely and promptly. However, existing ingredient information scraped from the cooking website is in the unstructured form with huge variation in the lexical structure, for example, '1 garlic clove, crushed', and '1 (8 ounce) package cream cheese, softened', making it difficult to extract information exactly. To provide an engaged and successful conversational service to users for cooking tasks, we propose a new ingredient parsing model that can parse an ingredient phrase of recipes into the structure form with its corresponding attributes with over 0.93 F1-score. Experimental results show that our model achieves state-of-the-art performance on AllRecipes and Food.com datasets.
Learning to Execute Actions or Ask Clarification Questions
Apr 20, 2022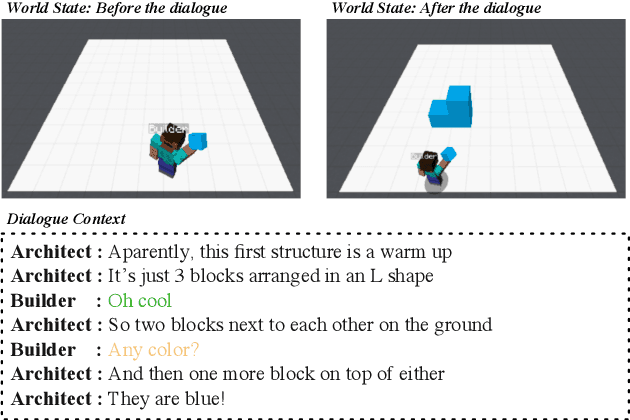


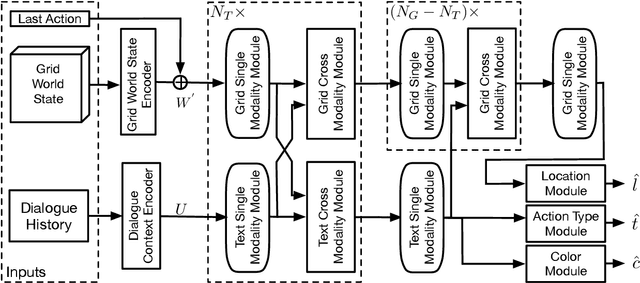
Collaborative tasks are ubiquitous activities where a form of communication is required in order to reach a joint goal. Collaborative building is one of such tasks. We wish to develop an intelligent builder agent in a simulated building environment (Minecraft) that can build whatever users wish to build by just talking to the agent. In order to achieve this goal, such agents need to be able to take the initiative by asking clarification questions when further information is needed. Existing works on Minecraft Corpus Dataset only learn to execute instructions neglecting the importance of asking for clarifications. In this paper, we extend the Minecraft Corpus Dataset by annotating all builder utterances into eight types, including clarification questions, and propose a new builder agent model capable of determining when to ask or execute instructions. Experimental results show that our model achieves state-of-the-art performance on the collaborative building task with a substantial improvement. We also define two new tasks, the learning to ask task and the joint learning task. The latter consists of solving both collaborating building and learning to ask tasks jointly.
StepGame: A New Benchmark for Robust Multi-Hop Spatial Reasoning in Texts
Apr 18, 2022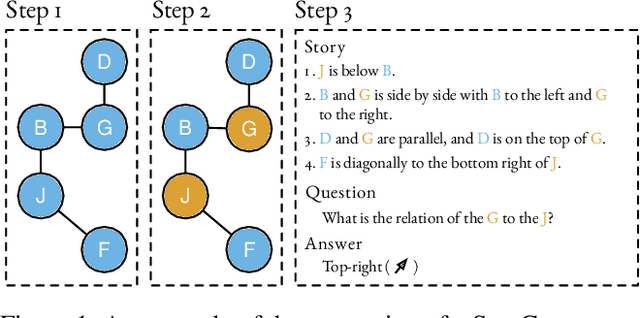
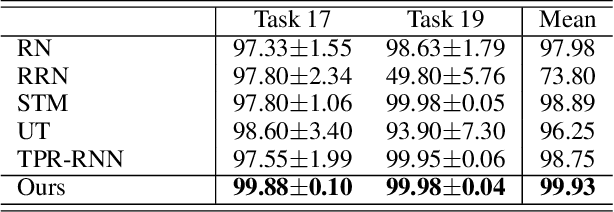

Inferring spatial relations in natural language is a crucial ability an intelligent system should possess. The bAbI dataset tries to capture tasks relevant to this domain (task 17 and 19). However, these tasks have several limitations. Most importantly, they are limited to fixed expressions, they are limited in the number of reasoning steps required to solve them, and they fail to test the robustness of models to input that contains irrelevant or redundant information. In this paper, we present a new Question-Answering dataset called StepGame for robust multi-hop spatial reasoning in texts. Our experiments demonstrate that state-of-the-art models on the bAbI dataset struggle on the StepGame dataset. Moreover, we propose a Tensor-Product based Memory-Augmented Neural Network (TP-MANN) specialized for spatial reasoning tasks. Experimental results on both datasets show that our model outperforms all the baselines with superior generalization and robustness performance.