 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema-Guided User Satisfaction Modeling for Task-Oriented Dialogues
May 26, 2023



User Satisfaction Modeling (USM) is one of the popular choices for task-oriented dialogue systems evaluation, where user satisfaction typically depends on whether the user's task goals were fulfilled by the system. Task-oriented dialogue systems use task schema, which is a set of task attributes, to encode the user's task goals. Existing studies on USM neglect explicitly modeling the user's task goals fulfillment using the task schema. In this paper, we propose SG-USM, a novel schema-guided user satisfaction modeling framework. It explicitly models the degree to which the user's preferences regarding the task attributes are fulfilled by the system for predicting the user's satisfaction level. SG-USM employs a pre-trained language model for encoding dialogue context and task attributes. Further, it employs a fulfillment representation layer for learning how many task attributes have been fulfilled in the dialogue, an importance predictor component for calculating the importance of task attributes. Finally, it predicts the user satisfaction based on task attribute fulfillment and task attribute importance. Experimental results on benchmark datasets (i.e. MWOZ, SGD, ReDial, and JDDC) show that SG-USM consistently outperforms competitive existing methods. Our extensive analysis demonstrates that SG-USM can improve the interpretability of user satisfaction modeling, has good scalability as it can effectively deal with unseen tasks and can also effectively work in low-resource settings by leveraging unlabeled data.
Rethinking Semi-supervised Learning with Language Models
May 22, 2023



Semi-supervised learning (SSL) is a popular setting aiming to effectively utilize unlabelled data to improve model performance in downstream natural language processing (NLP) tasks. Currently, there are two popular approaches to make use of unlabelled data: Self-training (ST) and Task-adaptive pre-training (TAPT). ST uses a teacher model to assign pseudo-labels to the unlabelled data, while TAPT continues pre-training on the unlabelled data before fine-tuning. To the best of our knowledge, the effectiveness of TAPT in SSL tasks has not been systematically studied, and no previous work has directly compared TAPT and ST in terms of their ability to utilize the pool of unlabelled data. In this paper, we provide an extensive empirical study comparing five state-of-the-art ST approaches and TAPT across various NLP tasks and data sizes, including in- and out-of-domain settings. Surprisingly, we find that TAPT is a strong and more robust SSL learner, even when using just a few hundred unlabelled samples or in the presence of domain shifts, compared to more sophisticated ST approaches, and tends to bring greater improvements in SSL than in fully-supervised settings. Our further analysis demonstrates the risks of using ST approaches when the size of labelled or unlabelled data is small or when domain shifts exist. We offer a fresh perspective for future SSL research, suggesting the use of unsupervised pre-training objectives over dependency on pseudo labels.
PARS: Pseudo-Label Aware Robust Sample Selection for Learning with Noisy Labels
Jan 26, 2022



Acquiring accurate labels on large-scale datasets is both time consuming and expensive. To reduce the dependency of deep learning models on learning from clean labeled data, several recent research efforts are focused on learning with noisy labels. These methods typically fall into three design categories to learn a noise robust model: sample selection approaches, noise robust loss functions, or label correction methods. In this paper, we propose PARS: Pseudo-Label Aware Robust Sample Selection, a hybrid approach that combines the best from all three worlds in a joint-training framework to achieve robustness to noisy labels. Specifically, PARS exploits all training samples using both the raw/noisy labels and estimated/refurbished pseudo-labels via self-training, divides samples into an ambiguous and a noisy subset via loss analysis, and designs label-dependent noise-aware loss functions for both sets of filtered labels. Results show that PARS significantly outperforms the state of the art on extensive studies on the noisy CIFAR-10 and CIFAR-100 datasets, particularly on challenging high-noise and low-resource settings. In particular, PARS achieved an absolute 12% improvement in test accuracy on the CIFAR-100 dataset with 90% symmetric label noise, and an absolute 27% improvement in test accuracy when only 1/5 of the noisy labels are available during training as an additional restriction. On a real-world noisy dataset, Clothing1M, PARS achieves competitive results to the state of the art.
Trans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations
Sep 28, 2021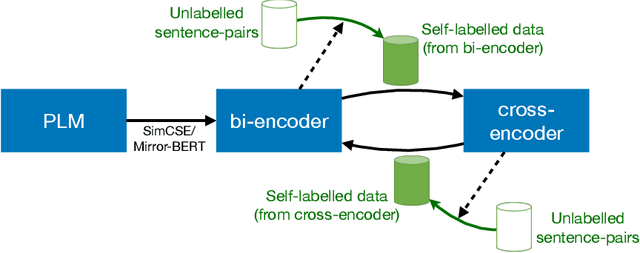
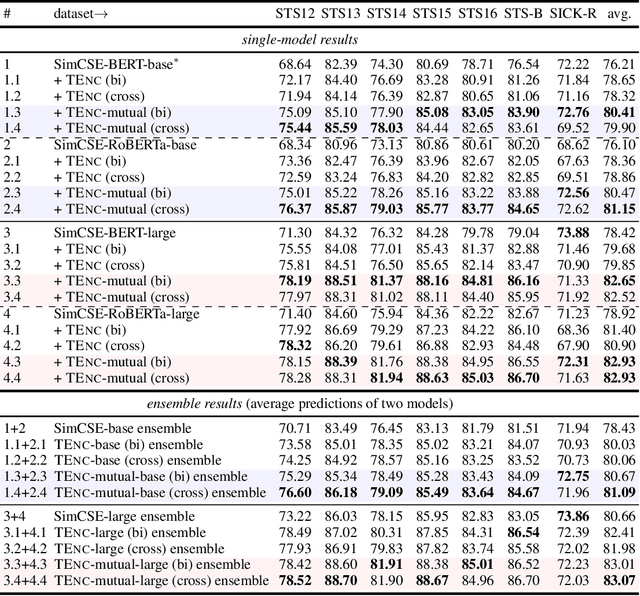
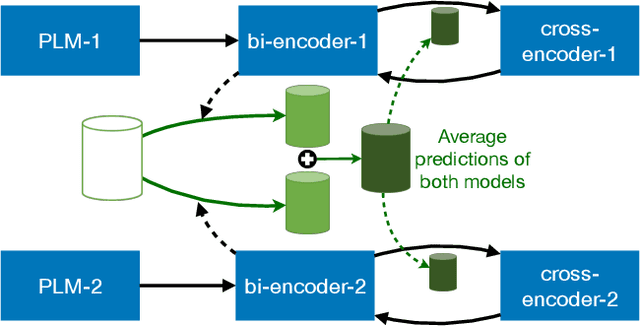
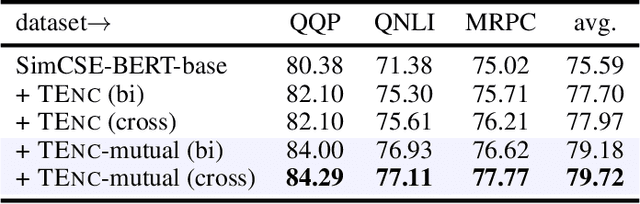
In NLP, a large volume of tasks involve pairwise comparison between two sequences (e.g. sentence similarity and paraphrase identification). Predominantly, two formulations are used for sentence-pair tasks: bi-encoders and cross-encoders. Bi-encoders produce fixed-dimensional sentence representations and are computationally efficient, however, they usually underperform cross-encoders. Cross-encoders can leverage their attention heads to exploit inter-sentence interactions for better performance but they require task fine-tuning and are computationally more expensive. In this paper, we present a completely unsupervised sentence representation model termed as Trans-Encoder that combines the two learning paradigms into an iterative joint framework to simultaneously learn enhanced bi- and cross-encoders. Specifically, on top of a pre-trained Language Model (PLM), we start with converting it to an unsupervised bi-encoder, and then alternate between the bi- and cross-encoder task formulations. In each alternation, one task formulation will produce pseudo-labels which are used as learning signals for the other task formulation. We then propose an extension to conduct such self-distillation approach on multiple PLMs in parallel and use the average of their pseudo-labels for mutual-distillation. Trans-Encoder creates, to the best of our knowledge, the first completely unsupervised cross-encoder and also a state-of-the-art unsupervised bi-encoder for sentence similarity. Both the bi-encoder and cross-encoder formulations of Trans-Encoder outperform recently proposed state-of-the-art unsupervised sentence encoders such as Mirror-BERT and SimCSE by up to 5% on the sentence similarity benchmarks.
Improving the expressiveness of neural vocoding with non-affine Normalizing Flows
Jun 16, 2021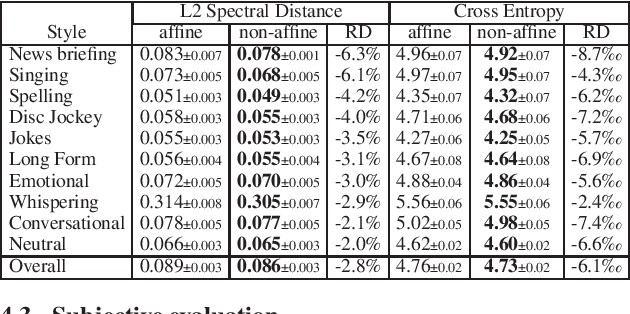

This paper proposes a general enhancement to the Normalizing Flows (NF) used in neural vocoding. As a case study, we improve expressive speech vocoding with a revamped Parallel Wavenet (PW). Specifically, we propose to extend the affine transformation of PW to the more expressive invertible non-affine function. The greater expressiveness of the improved PW leads to better-perceived signal quality and naturalness in the waveform reconstruction and text-to-speech (TTS) tasks. We evaluate the model across different speaking styles on a multi-speaker, multi-lingual dataset. In the waveform reconstruction task, the proposed model closes the naturalness and signal quality gap from the original PW to recordings by $10\%$, and from other state-of-the-art neural vocoding systems by more than $60\%$. We also demonstrate improvements in objective metrics on the evaluation test set with L2 Spectral Distance and Cross-Entropy reduced by $3\%$ and $6\unicode{x2030}$ comparing to the affine PW. Furthermore, we extend the probability density distillation procedure proposed by the original PW paper, so that it works with any non-affine invertible and differentiable function.
Universal Neural Vocoding with Parallel WaveNet
Feb 15, 2021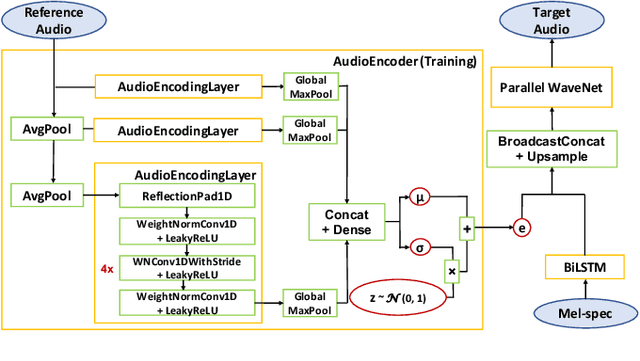

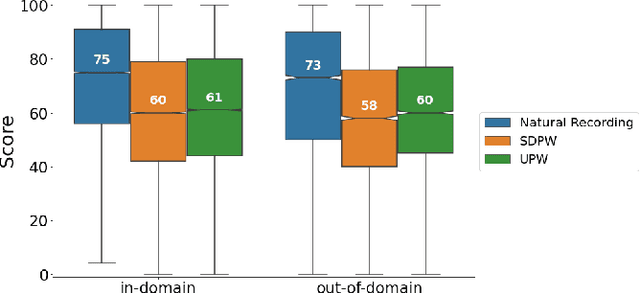
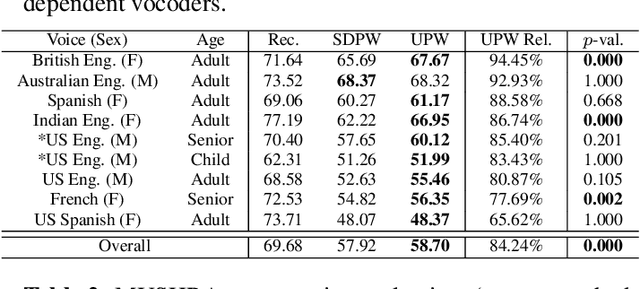
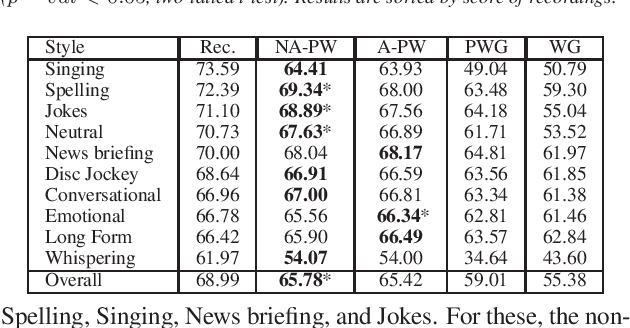
We present a universal neural vocoder based on Parallel WaveNet, with an additional conditioning network called Audio Encoder. Our universal vocoder offers real-time high-quality speech synthesis on a wide range of use cases. We tested it on 43 internal speakers of diverse age and gender, speaking 20 languages in 17 unique styles, of which 7 voices and 5 styles were not exposed during training. We show that the proposed universal vocoder significantly outperforms speaker-dependent vocoders overall. We also show that the proposed vocoder outperforms several existing neural vocoder architectures in terms of naturalness and universality. These findings are consistent when we further test on more than 300 open-source voices.
The Weighted Kendall and High-order Kernels for Permutations
Jun 12, 2018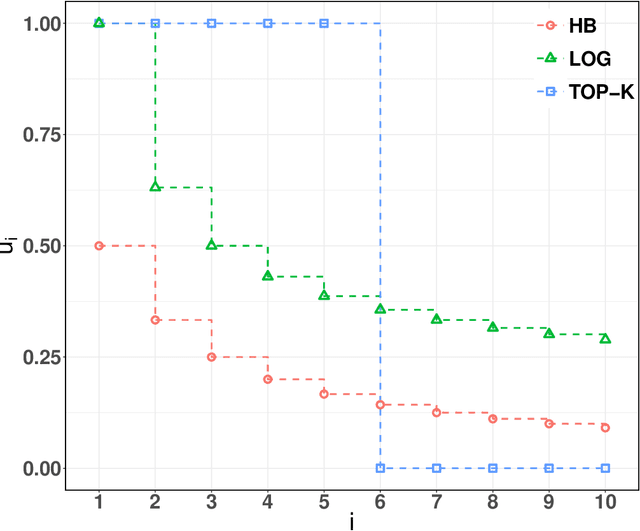

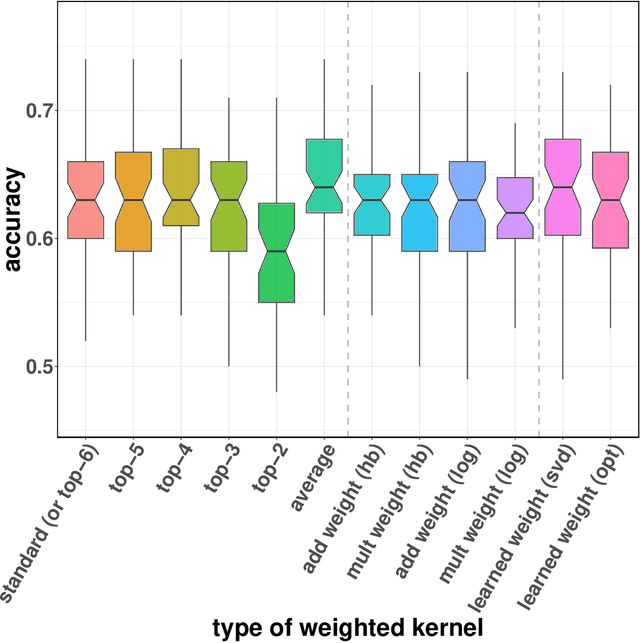
We propose new positive definite kernels for permutations. First we introduce a weighted version of the Kendall kernel, which allows to weight unequally the contributions of different item pairs in the permutations depending on their ranks. Like the Kendall kernel, we show that the weighted version is invariant to relabeling of items and can be computed efficiently in $O(n \ln(n))$ operations, where $n$ is the number of items in the permutation. Second, we propose a supervised approach to learn the weights by jointly optimizing them with the function estimated by a kernel machine. Third, while the Kendall kernel considers pairwise comparison between items, we extend it by considering higher-order comparisons among tuples of items and show that the supervised approach of learning the weights can be systematically generalized to higher-order permutation kernels.