 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikeBench: Evaluating Subjective Likability in LLMs for Personalization
Dec 15, 2025A personalized LLM should remember user facts, apply them correctly, and adapt over time to provide responses that the user prefers. Existing LLM personalization benchmarks are largely centered on two axes: accurately recalling user information and accurately applying remembered information in downstream tasks. We argue that a third axis, likability, is both subjective and central to user experience, yet under-measured by current benchmarks. To measure likability holistically, we introduce LikeBench, a multi-session, dynamic evaluation framework that measures likability across multiple dimensions by how much an LLM can adapt over time to a user's preferences to provide more likable responses. In LikeBench, the LLMs engage in conversation with a simulated user and learn preferences only from the ongoing dialogue. As the interaction unfolds, models try to adapt to responses, and after each turn, they are evaluated for likability across seven dimensions by the same simulated user. To the best of our knowledge, we are the first to decompose likability into multiple diagnostic metrics: emotional adaptation, formality matching, knowledge adaptation, reference understanding, conversation length fit, humor fit, and callback, which makes it easier to pinpoint where a model falls short. To make the simulated user more realistic and discriminative, LikeBench uses fine-grained, psychologically grounded descriptive personas rather than the coarse high/low trait rating based personas used in prior work. Our benchmark shows that strong memory performance does not guarantee high likability: DeepSeek R1, with lower memory accuracy (86%, 17 facts/profile), outperformed Qwen3 by 28% on likability score despite Qwen3's higher memory accuracy (93%, 43 facts/profile). Even SOTA models like GPT-5 adapt well in short exchanges but show only limited robustness in longer, noisier interactions.
Del Visual al Auditivo: Sonorización de Escenas Guiada por Imagen
Feb 02, 2024Recent advances in image, video, text and audio generative techniques, and their use by the general public, are leading to new forms of content generation. Usually, each modality was approached separately, which poses limitations. The automatic sound recording of visual sequences is one of the greatest challenges for the automatic generation of multimodal content. We present a processing flow that, starting from images extracted from videos, is able to sound them. We work with pre-trained models that employ complex encoders, contrastive learning, and multiple modalities, allowing complex representations of the sequences for their sonorization. The proposed scheme proposes different possibilities for audio mapping and text guidance. We evaluated the scheme on a dataset of frames extracted from a commercial video game and sounds extracted from the Freesound platform. Subjective tests have evidenced that the proposed scheme is able to generate and assign audios automatically and conveniently to images. Moreover, it adapts well to user preferences, and the proposed objective metrics show a high correlation with the subjective ratings.
Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
Jul 29, 2022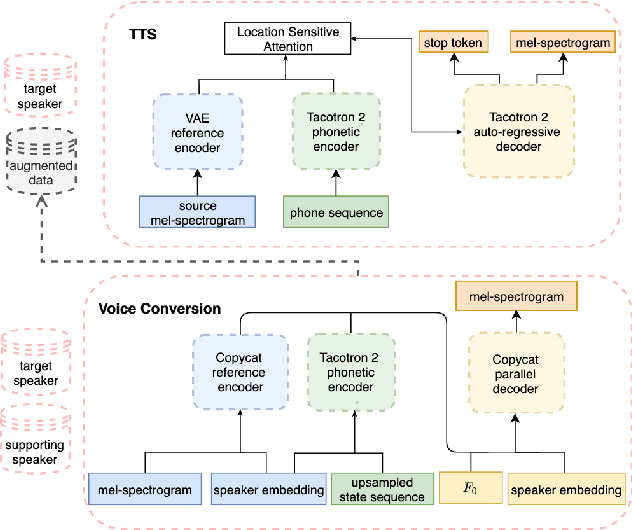

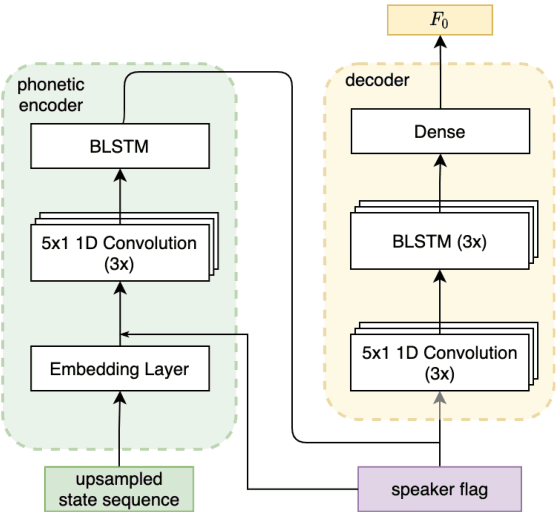
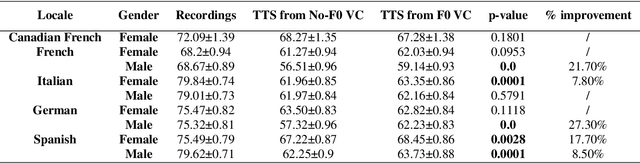
The availability of data in expressive styles across languages is limited, and recording sessions are costly and time consuming. To overcome these issues, we demonstrate how to build low-resource, neural text-to-speech (TTS) voices with only 1 hour of conversational speech, when no other conversational data are available in the same language. Assuming the availability of non-expressive speech data in that language, we propose a 3-step technology: 1) we train an F0-conditioned voice conversion (VC) model as data augmentation technique; 2) we train an F0 predictor to control the conversational flavour of the voice-converted synthetic data; 3) we train a TTS system that consumes the augmented data. We prove that our technology enables F0 controllability, is scalable across speakers and languages and is competitive in terms of naturalness over a state-of-the-art baseline model, another augmented method which does not make use of F0 information.
Cross-speaker style transfer for text-to-speech using data augmentation
Feb 10, 2022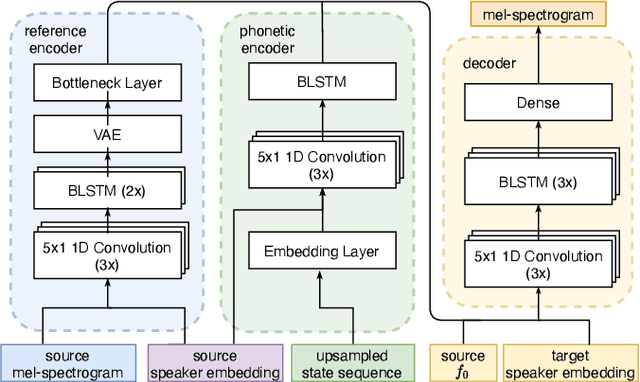
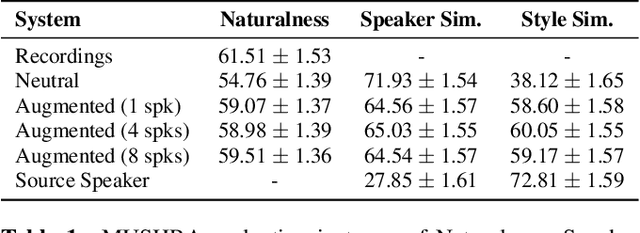
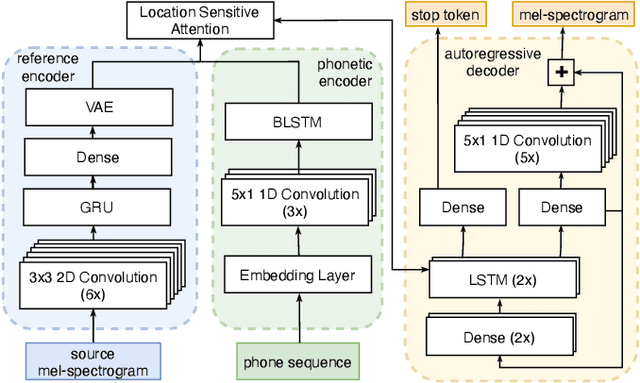
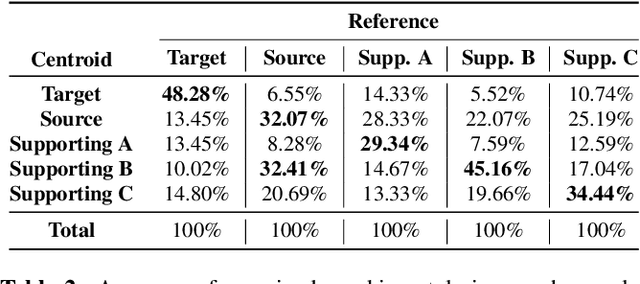
We address the problem of cross-speaker style transfer for text-to-speech (TTS) using data augmentation via voice conversion. We assume to have a corpus of neutral non-expressive data from a target speaker and supporting conversational expressive data from different speakers. Our goal is to build a TTS system that is expressive, while retaining the target speaker's identity. The proposed approach relies on voice conversion to first generate high-quality data from the set of supporting expressive speakers. The voice converted data is then pooled with natural data from the target speaker and used to train a single-speaker multi-style TTS system. We provide evidence that this approach is efficient, flexible, and scalable. The method is evaluated using one or more supporting speakers, as well as a variable amount of supporting data. We further provide evidence that this approach allows some controllability of speaking style, when using multiple supporting speakers. We conclude by scaling our proposed technology to a set of 14 speakers across 7 languages. Results indicate that our technology consistently improves synthetic samples in terms of style similarity, while retaining the target speaker's identity.
Enhancing audio quality for expressive Neural Text-to-Speech
Aug 13, 2021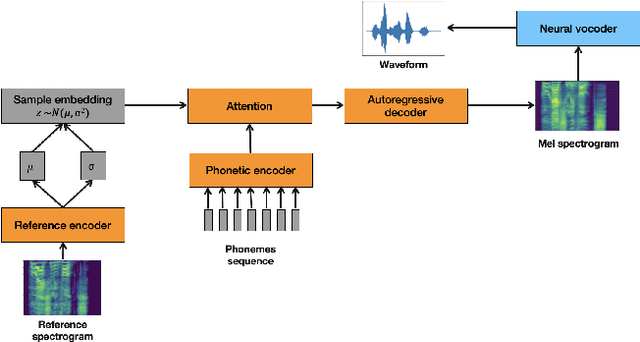
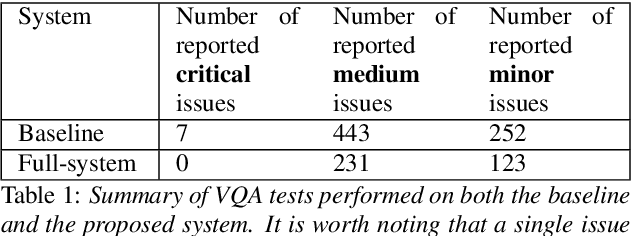
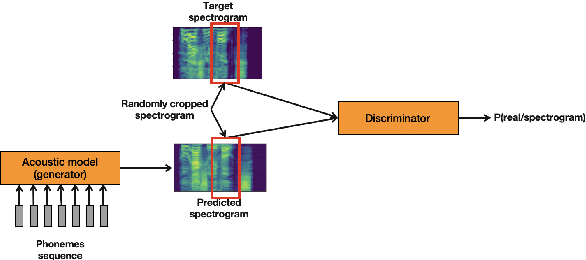
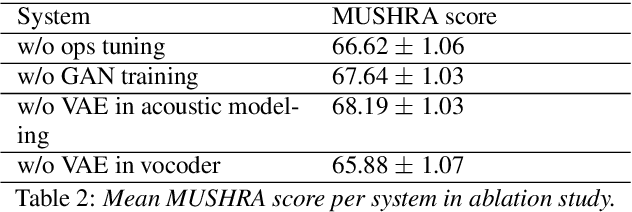
Artificial speech synthesis has made a great leap in terms of naturalness as recent Text-to-Speech (TTS) systems are capable of producing speech with similar quality to human recordings. However, not all speaking styles are easy to model: highly expressive voices are still challenging even to recent TTS architectures since there seems to be a trade-off between expressiveness in a generated audio and its signal quality. In this paper, we present a set of techniques that can be leveraged to enhance the signal quality of a highly-expressive voice without the use of additional data. The proposed techniques include: tuning the autoregressive loop's granularity during training; using Generative Adversarial Networks in acoustic modelling; and the use of Variational Auto-Encoders in both the acoustic model and the neural vocoder. We show that, when combined, these techniques greatly closed the gap in perceived naturalness between the baseline system and recordings by 39% in terms of MUSHRA scores for an expressive celebrity voice.
Universal Neural Vocoding with Parallel WaveNet
Feb 15, 2021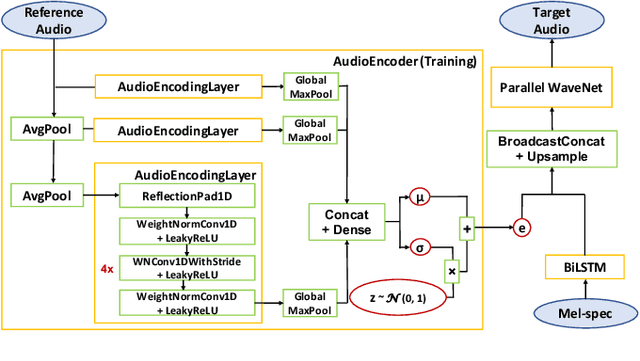

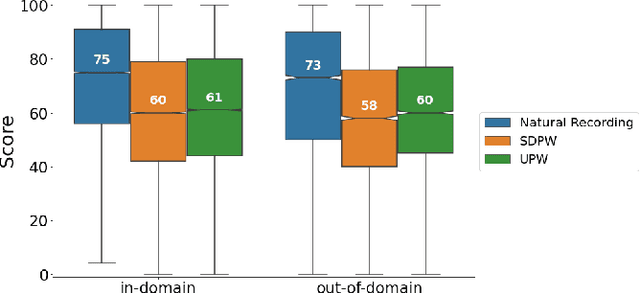
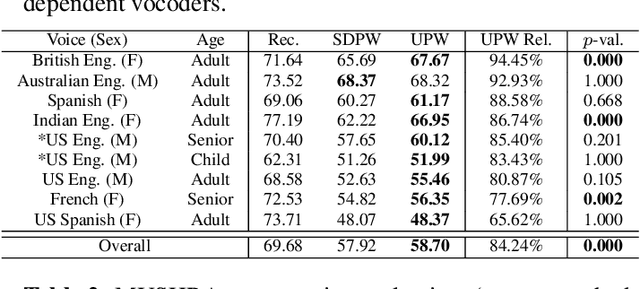
We present a universal neural vocoder based on Parallel WaveNet, with an additional conditioning network called Audio Encoder. Our universal vocoder offers real-time high-quality speech synthesis on a wide range of use cases. We tested it on 43 internal speakers of diverse age and gender, speaking 20 languages in 17 unique styles, of which 7 voices and 5 styles were not exposed during training. We show that the proposed universal vocoder significantly outperforms speaker-dependent vocoders overall. We also show that the proposed vocoder outperforms several existing neural vocoder architectures in terms of naturalness and universality. These findings are consistent when we further test on more than 300 open-source voices.