 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDel Visual al Auditivo: Sonorización de Escenas Guiada por Imagen
Feb 02, 2024Recent advances in image, video, text and audio generative techniques, and their use by the general public, are leading to new forms of content generation. Usually, each modality was approached separately, which poses limitations. The automatic sound recording of visual sequences is one of the greatest challenges for the automatic generation of multimodal content. We present a processing flow that, starting from images extracted from videos, is able to sound them. We work with pre-trained models that employ complex encoders, contrastive learning, and multiple modalities, allowing complex representations of the sequences for their sonorization. The proposed scheme proposes different possibilities for audio mapping and text guidance. We evaluated the scheme on a dataset of frames extracted from a commercial video game and sounds extracted from the Freesound platform. Subjective tests have evidenced that the proposed scheme is able to generate and assign audios automatically and conveniently to images. Moreover, it adapts well to user preferences, and the proposed objective metrics show a high correlation with the subjective ratings.
Multilingual context-based pronunciation learning for Text-to-Speech
Jul 31, 2023Phonetic information and linguistic knowledge are an essential component of a Text-to-speech (TTS) front-end. Given a language, a lexicon can be collected offline and Grapheme-to-Phoneme (G2P) relationships are usually modeled in order to predict the pronunciation for out-of-vocabulary (OOV) words. Additionally, post-lexical phonology, often defined in the form of rule-based systems, is used to correct pronunciation within or between words. In this work we showcase a multilingual unified front-end system that addresses any pronunciation related task, typically handled by separate modules. We evaluate the proposed model on G2P conversion and other language-specific challenges, such as homograph and polyphones disambiguation, post-lexical rules and implicit diacritization. We find that the multilingual model is competitive across languages and tasks, however, some trade-offs exists when compared to equivalent monolingual solutions.
Improving grapheme-to-phoneme conversion by learning pronunciations from speech recordings
Jul 31, 2023The Grapheme-to-Phoneme (G2P) task aims to convert orthographic input into a discrete phonetic representation. G2P conversion is beneficial to various speech processing applications, such as text-to-speech and speech recognition. However, these tend to rely on manually-annotated pronunciation dictionaries, which are often time-consuming and costly to acquire. In this paper, we propose a method to improve the G2P conversion task by learning pronunciation examples from audio recordings. Our approach bootstraps a G2P with a small set of annotated examples. The G2P model is used to train a multilingual phone recognition system, which then decodes speech recordings with a phonetic representation. Given hypothesized phoneme labels, we learn pronunciation dictionaries for out-of-vocabulary words, and we use those to re-train the G2P system. Results indicate that our approach consistently improves the phone error rate of G2P systems across languages and amount of available data.
Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
Jul 29, 2022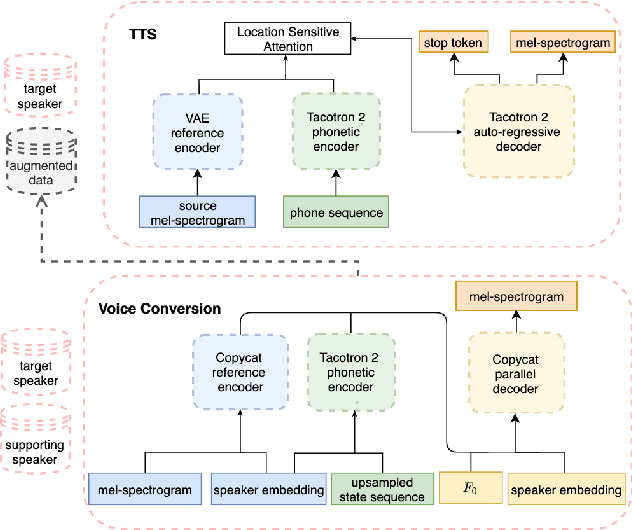

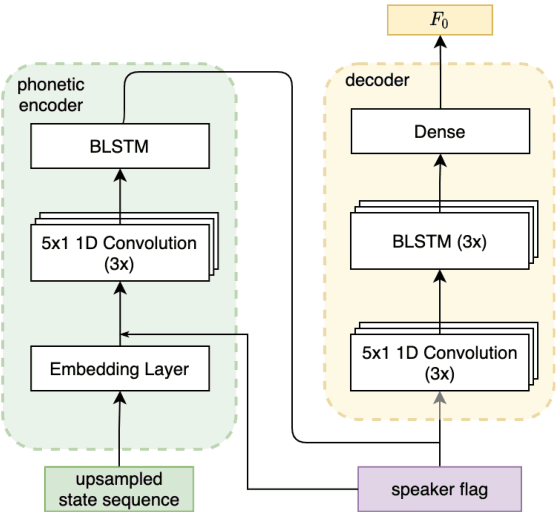
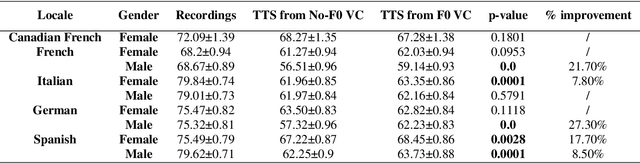
The availability of data in expressive styles across languages is limited, and recording sessions are costly and time consuming. To overcome these issues, we demonstrate how to build low-resource, neural text-to-speech (TTS) voices with only 1 hour of conversational speech, when no other conversational data are available in the same language. Assuming the availability of non-expressive speech data in that language, we propose a 3-step technology: 1) we train an F0-conditioned voice conversion (VC) model as data augmentation technique; 2) we train an F0 predictor to control the conversational flavour of the voice-converted synthetic data; 3) we train a TTS system that consumes the augmented data. We prove that our technology enables F0 controllability, is scalable across speakers and languages and is competitive in terms of naturalness over a state-of-the-art baseline model, another augmented method which does not make use of F0 information.
Voice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Feb 16, 2022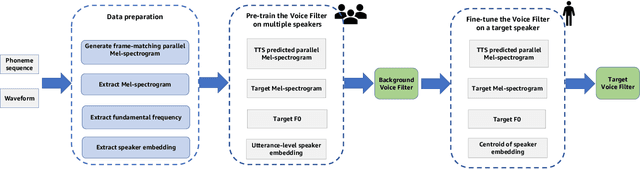

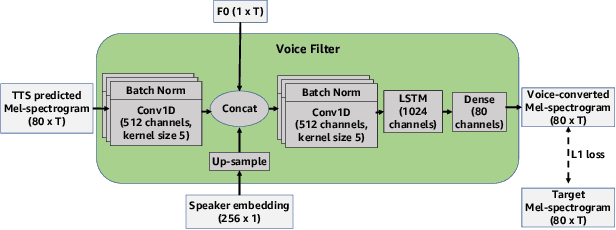

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.
Cross-speaker style transfer for text-to-speech using data augmentation
Feb 10, 2022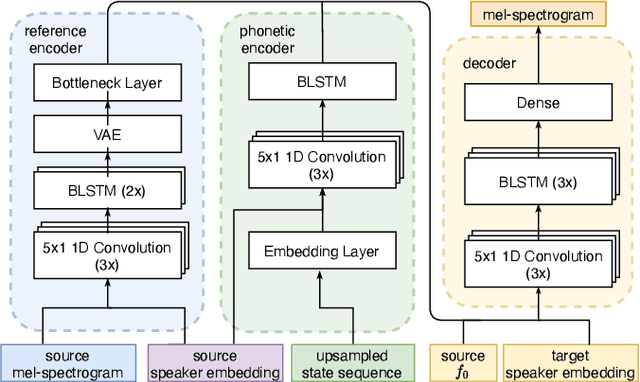
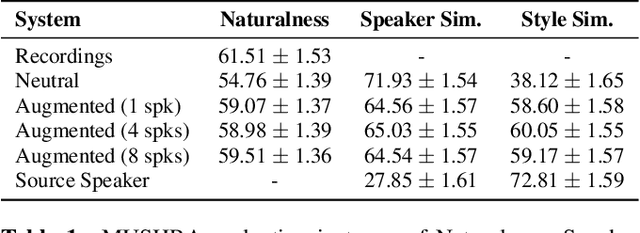
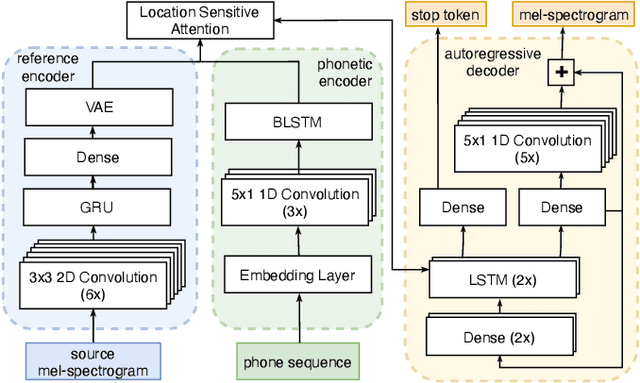
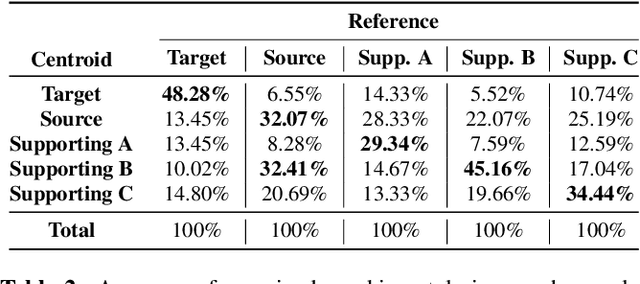
We address the problem of cross-speaker style transfer for text-to-speech (TTS) using data augmentation via voice conversion. We assume to have a corpus of neutral non-expressive data from a target speaker and supporting conversational expressive data from different speakers. Our goal is to build a TTS system that is expressive, while retaining the target speaker's identity. The proposed approach relies on voice conversion to first generate high-quality data from the set of supporting expressive speakers. The voice converted data is then pooled with natural data from the target speaker and used to train a single-speaker multi-style TTS system. We provide evidence that this approach is efficient, flexible, and scalable. The method is evaluated using one or more supporting speakers, as well as a variable amount of supporting data. We further provide evidence that this approach allows some controllability of speaking style, when using multiple supporting speakers. We conclude by scaling our proposed technology to a set of 14 speakers across 7 languages. Results indicate that our technology consistently improves synthetic samples in terms of style similarity, while retaining the target speaker's identity.