 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Knowledge Distillation via Flow-based Voice Conversion for Robust Polyglot Text-To-Speech
Sep 15, 2023In this work, we introduce a framework for cross-lingual speech synthesis, which involves an upstream Voice Conversion (VC) model and a downstream Text-To-Speech (TTS) model. The proposed framework consists of 4 stages. In the first two stages, we use a VC model to convert utterances in the target locale to the voice of the target speaker. In the third stage, the converted data is combined with the linguistic features and durations from recordings in the target language, which are then used to train a single-speaker acoustic model. Finally, the last stage entails the training of a locale-independent vocoder. Our evaluations show that the proposed paradigm outperforms state-of-the-art approaches which are based on training a large multilingual TTS model. In addition, our experiments demonstrate the robustness of our approach with different model architectures, languages, speakers and amounts of data. Moreover, our solution is especially beneficial in low-resource settings.
InstaLoc: One-shot Global Lidar Localisation in Indoor Environments through Instance Learning
May 16, 2023



Localization for autonomous robots in prior maps is crucial for their functionality. This paper offers a solution to this problem for indoor environments called InstaLoc, which operates on an individual lidar scan to localize it within a prior map. We draw on inspiration from how humans navigate and position themselves by recognizing the layout of distinctive objects and structures. Mimicking the human approach, InstaLoc identifies and matches object instances in the scene with those from a prior map. As far as we know, this is the first method to use panoptic segmentation directly inferring on 3D lidar scans for indoor localization. InstaLoc operates through two networks based on spatially sparse tensors to directly infer dense 3D lidar point clouds. The first network is a panoptic segmentation network that produces object instances and their semantic classes. The second smaller network produces a descriptor for each object instance. A consensus based matching algorithm then matches the instances to the prior map and estimates a six degrees of freedom (DoF) pose for the input cloud in the prior map. The significance of InstaLoc is that it has two efficient networks. It requires only one to two hours of training on a mobile GPU and runs in real-time at 1 Hz. Our method achieves between two and four times more detections when localizing, as compared to baseline methods, and achieves higher precision on these detections.
Real-time LIDAR localization in natural and urban environments
Jan 31, 2023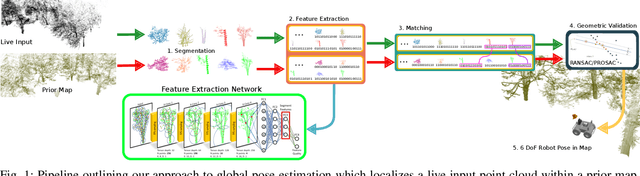
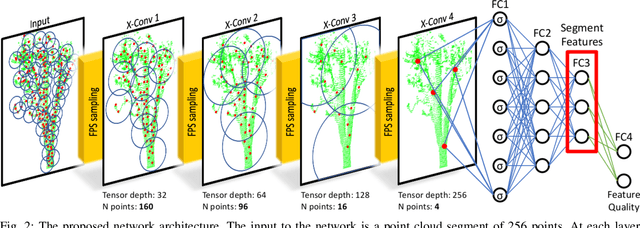
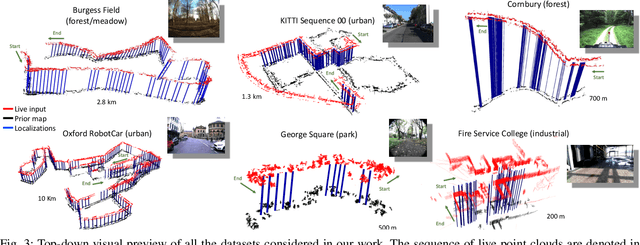

Localization is a key challenge in many robotics applications. In this work we explore LIDAR-based global localization in both urban and natural environments and develop a method suitable for online application. Our approach leverages efficient deep learning architecture capable of learning compact point cloud descriptors directly from 3D data. The method uses an efficient feature space representation of a set of segmented point clouds to match between the current scene and the prior map. We show that down-sampling in the inner layers of the network can significantly reduce computation time without sacrificing performance. We present substantial evaluation of LIDAR-based global localization methods on nine scenarios from six datasets varying between urban, park, forest, and industrial environments. Part of which includes post-processed data from 30 sequences of the Oxford RobotCar dataset, which we make publicly available. Our experiments demonstrate a factor of three reduction of computation, 70% lower memory consumption with marginal loss in localization frequency. The proposed method allows the full pipeline to run on robots with limited computation payload such as drones, quadrupeds, and UGVs as it does not require a GPU at run time.
Modelling low-resource accents without accent-specific TTS frontend
Jan 11, 2023



This work focuses on modelling a speaker's accent that does not have a dedicated text-to-speech (TTS) frontend, including a grapheme-to-phoneme (G2P) module. Prior work on modelling accents assumes a phonetic transcription is available for the target accent, which might not be the case for low-resource, regional accents. In our work, we propose an approach whereby we first augment the target accent data to sound like the donor voice via voice conversion, then train a multi-speaker multi-accent TTS model on the combination of recordings and synthetic data, to generate the donor's voice speaking in the target accent. Throughout the procedure, we use a TTS frontend developed for the same language but a different accent. We show qualitative and quantitative analysis where the proposed strategy achieves state-of-the-art results compared to other generative models. Our work demonstrates that low resource accents can be modelled with relatively little data and without developing an accent-specific TTS frontend. Audio samples of our model converting to multiple accents are available on our web page.
Universal Neural Vocoding with Parallel WaveNet
Feb 15, 2021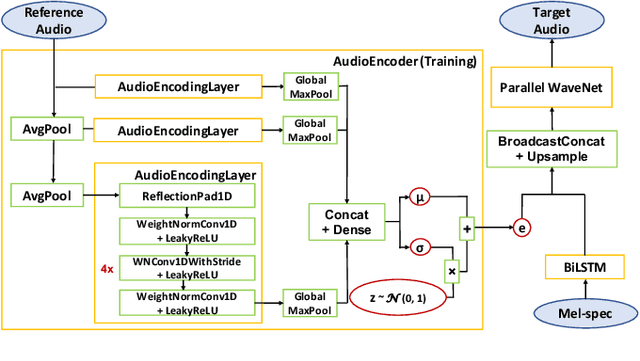

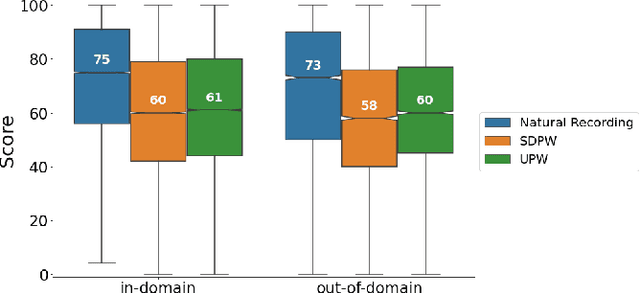
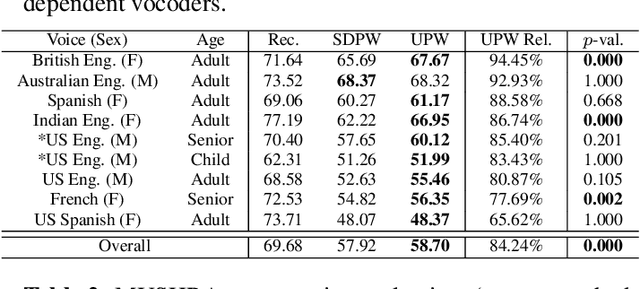
We present a universal neural vocoder based on Parallel WaveNet, with an additional conditioning network called Audio Encoder. Our universal vocoder offers real-time high-quality speech synthesis on a wide range of use cases. We tested it on 43 internal speakers of diverse age and gender, speaking 20 languages in 17 unique styles, of which 7 voices and 5 styles were not exposed during training. We show that the proposed universal vocoder significantly outperforms speaker-dependent vocoders overall. We also show that the proposed vocoder outperforms several existing neural vocoder architectures in terms of naturalness and universality. These findings are consistent when we further test on more than 300 open-source voices.
$\mathbb{X}$Resolution Correspondence Networks
Dec 17, 2020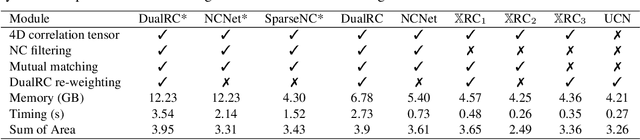
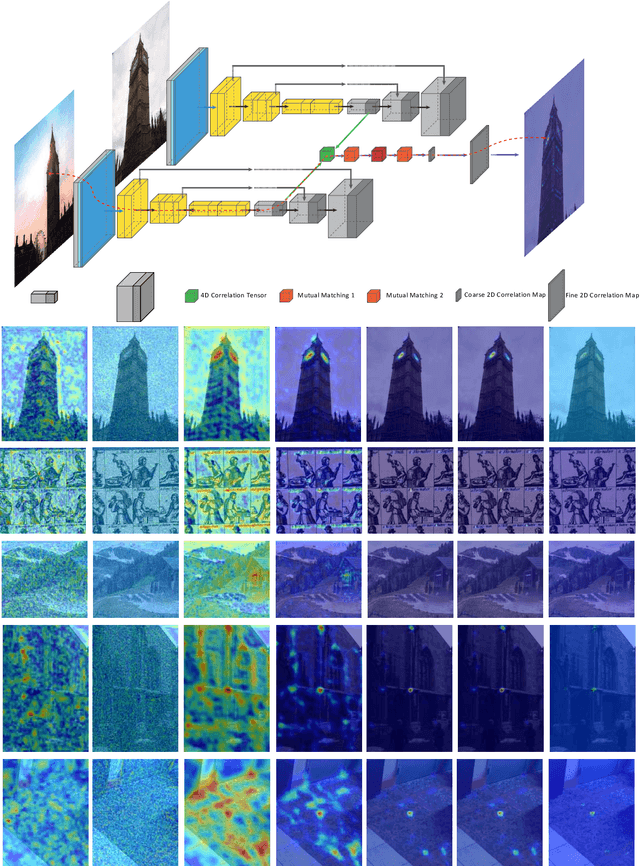
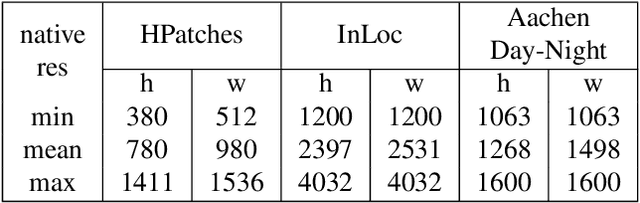
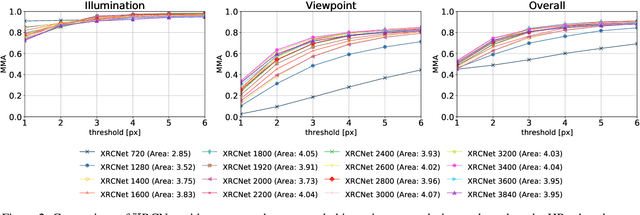
In this paper, we aim at establishing accurate dense correspondences between a pair of images with overlapping field of view under challenging illumination variation, viewpoint changes, and style differences. Through an extensive ablation study of the state-of-the-art correspondence networks, we surprisingly discovered that the widely adopted 4D correlation tensor and its related learning and processing modules could be de-parameterised and removed from training with merely a minor impact over the final matching accuracy. Disabling some of the most memory consuming and computational expensive modules dramatically speeds up the training procedure and allows to use 4x bigger batch size, which in turn compensates for the accuracy drop. Together with a multi-GPU inference stage, our method facilitates the systematic investigation of the relationship between matching accuracy and up-sampling resolution of the native testing images from 720p to 4K. This leads to finding an optimal resolution $\mathbb X$ that produces accurate matching performance surpassing the state-of-the-art methods particularly over the lower error band for the proposed network and evaluation datasets.
Online LiDAR-SLAM for Legged Robots with Robust Registration and Deep-Learned Loop Closure
Jan 28, 2020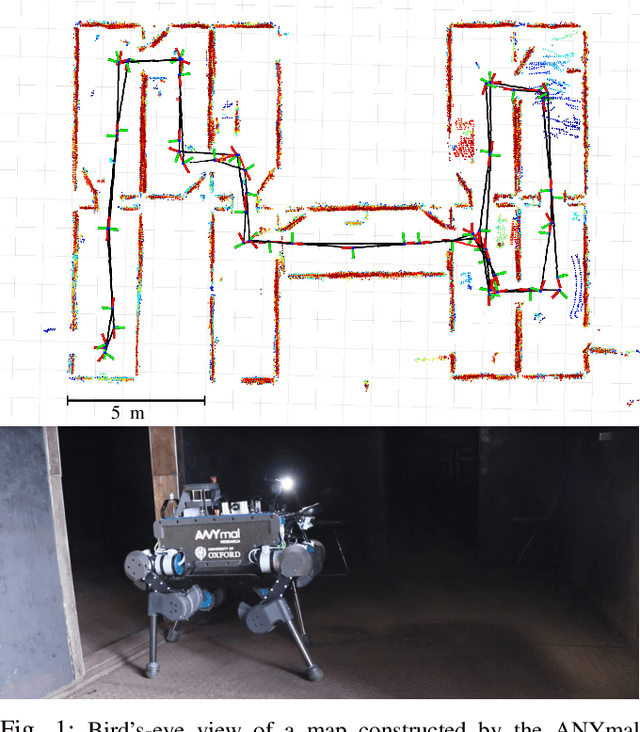

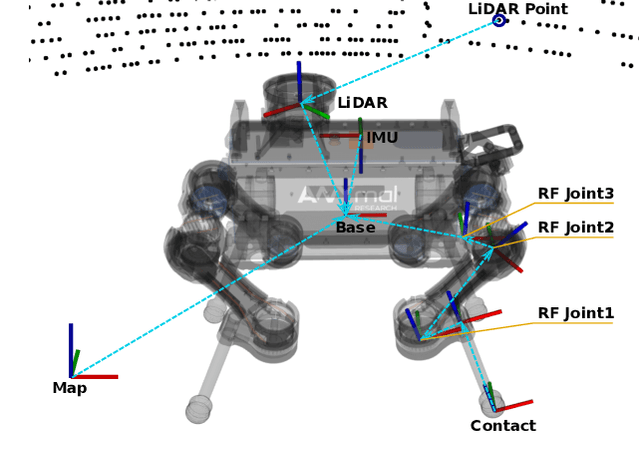

In this paper, we present a factor-graph LiDAR-SLAM system which incorporates a state-of-the-art deeply learned feature-based loop closure detector to enable a legged robot to localize and map in industrial environments. These facilities can be badly lit and comprised of indistinct metallic structures, thus our system uses only LiDAR sensing and was developed to run on the quadruped robot's navigation PC. Point clouds are accumulated using an inertial-kinematic state estimator before being aligned using ICP registration. To close loops we use a loop proposal mechanism which matches individual segments between clouds. We trained a descriptor offline to match these segments. The efficiency of our method comes from carefully designing the network architecture to minimize the number of parameters such that this deep learning method can be deployed in real-time using only the CPU of a legged robot, a major contribution of this work. The set of odometry and loop closure factors are updated using pose graph optimization. Finally we present an efficient risk alignment prediction method which verifies the reliability of the registrations. Experimental results at an industrial facility demonstrated the robustness and flexibility of our system, including autonomous following paths derived from the SLAM map.
SKD: Unsupervised Keypoint Detecting for Point Clouds using Embedded Saliency Estimation
Dec 10, 2019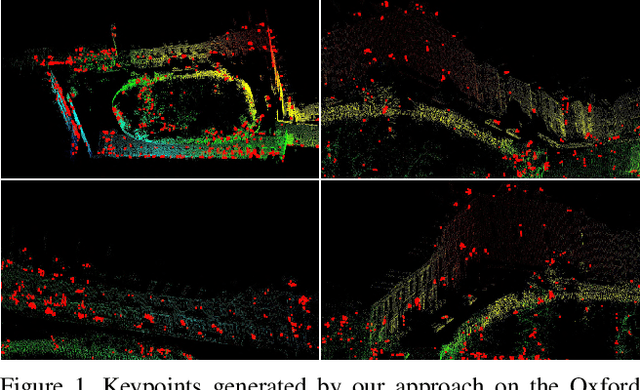
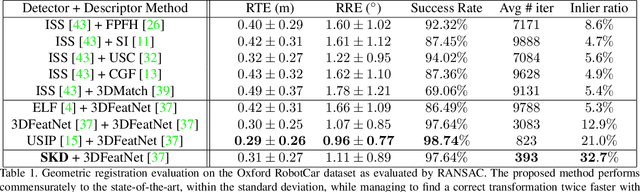
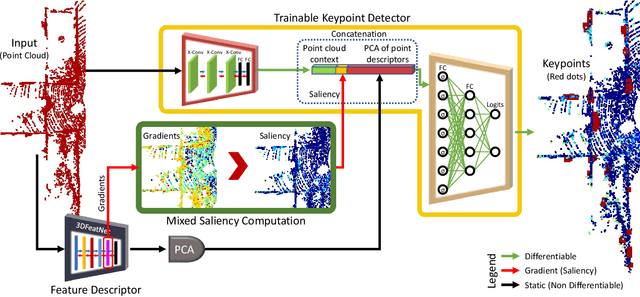

In this work we present a novel keypoint detector that uses saliency to determine the best candidates from point clouds. The approach can be applied to any differentiable deep learning descriptor by using the gradients of that descriptor with respect to the input to estimate an initial set of candidate keypoints. By using a neural network over the set of candidates we further learn to refine the point selection until the actual keypoints are obtained. The key intuition behind this approach is that keypoints need to be determined based on how the descriptor behaves and not just on the geometry that surrounds a point. To improve the performance of the learned keypoint descriptor we combine the saliency, the feature signal and geometric information from the point cloud to allow the network to select good keypoint candidates. The approach was evaluated on the two largest LIDAR datasets - the Oxford RobotCar dataset and the KITTI dataset, where we obtain up to 50% improvement over the state-of-the-art in both matchability score and repeatability.
Learning to See the Wood for the Trees: Deep Laser Localization in Urban and Natural Environments on a CPU
Feb 26, 2019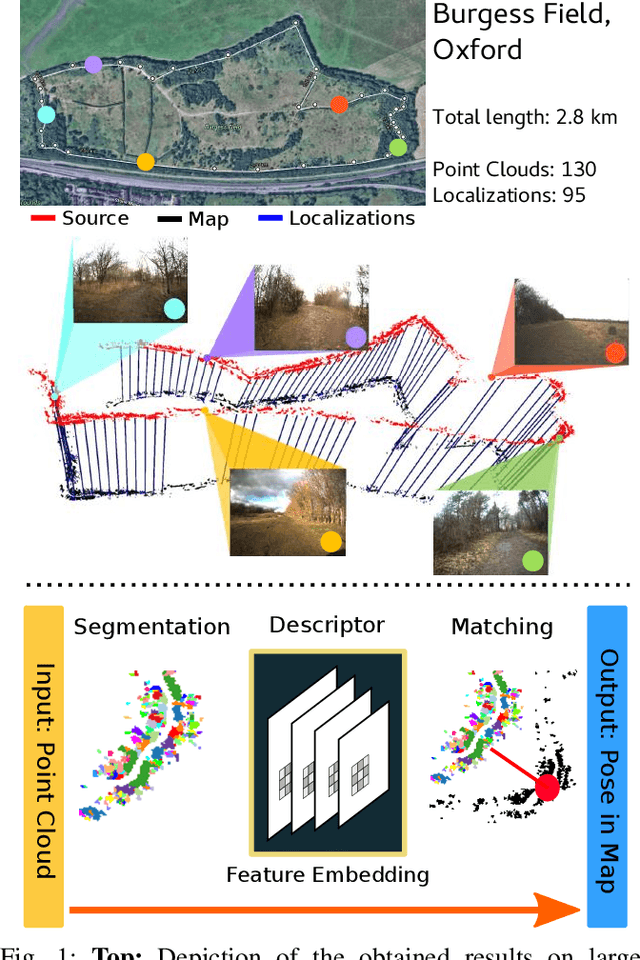
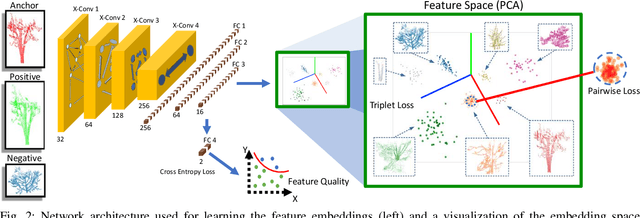
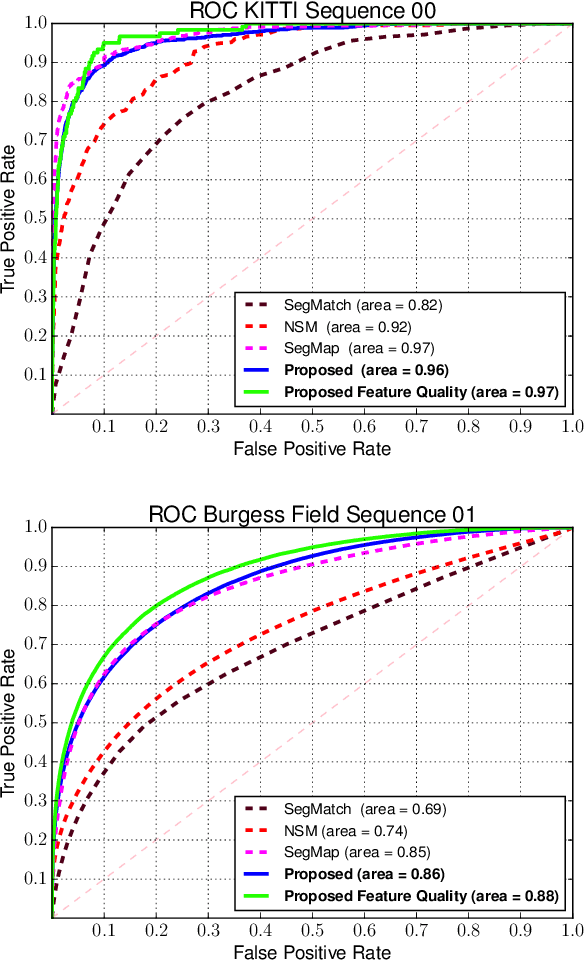
Localization in challenging, natural environments such as forests or woodlands is an important capability for many applications from guiding a robot navigating along a forest trail to monitoring vegetation growth with handheld sensors. In this work we explore laser-based localization in both urban and natural environments, which is suitable for online applications. We propose a deep learning approach capable of learning meaningful descriptors directly from 3D point clouds by comparing triplets (anchor, positive and negative examples). The approach learns a feature space representation for a set of segmented point clouds that are matched between a current and previous observations. Our learning method is tailored towards loop closure detection resulting in a small model which can be deployed using only a CPU. The proposed learning method would allow the full pipeline to run on robots with limited computational payload such as drones, quadrupeds or UGVs.
Seeing the Wood for the Trees: Reliable Localization in Urban and Natural Environments
Sep 14, 2018
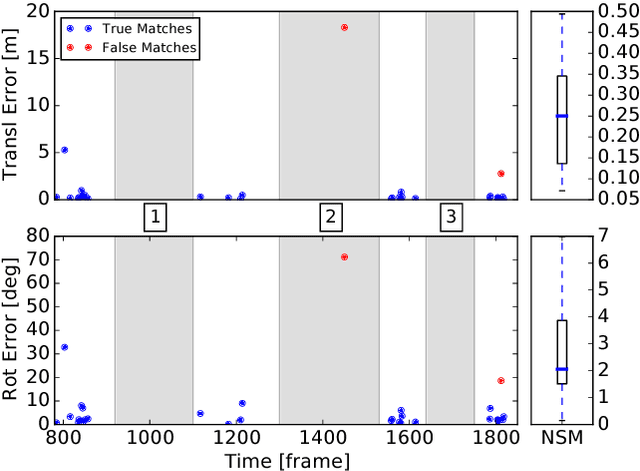


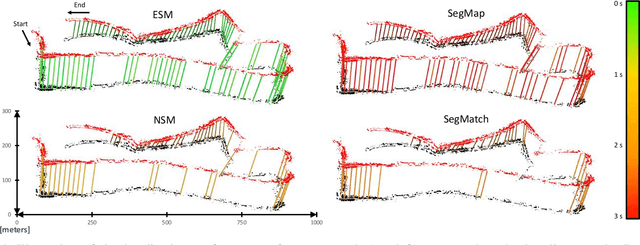
In this work we introduce Natural Segmentation and Matching (NSM), an algorithm for reliable localization, using laser, in both urban and natural environments. Current state-of-the-art global approaches do not generalize well to structure-poor vegetated areas such as forests or orchards. In these environments clutter and perceptual aliasing prevents repeatable extraction of distinctive landmarks between different test runs. In natural forests, tree trunks are not distinctive, foliage intertwines and there is a complete lack of planar structure. In this paper we propose a method for place recognition which uses a more involved feature extraction process which is better suited to this type of environment. First, a feature extraction module segments stable and reliable object-sized segments from a point cloud despite the presence of heavy clutter or tree foliage. Second, repeatable oriented key poses are extracted and matched with a reliable shape descriptor using a Random Forest to estimate the current sensor's position within the target map. We present qualitative and quantitative evaluation on three datasets from different environments - the KITTI benchmark, a parkland scene and a foliage-heavy forest. The experiments show how our approach can achieve place recognition in woodlands while also outperforming current state-of-the-art approaches in urban scenarios without specific tuning.