 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApET: Approximation-Error Guided Token Compression for Efficient VLMs
Feb 23, 2026Recent Vision-Language Models (VLMs) have demonstrated remarkable multimodal understanding capabilities, yet the redundant visual tokens incur prohibitive computational overhead and degrade inference efficiency. Prior studies typically relies on [CLS] attention or text-vision cross-attention to identify and discard redundant visual tokens. Despite promising results, such solutions are prone to introduce positional bias and, more critically, are incompatible with efficient attention kernels such as FlashAttention, limiting their practical deployment for VLM acceleration. In this paper, we step away from attention dependencies and revisit visual token compression from an information-theoretic perspective, aiming to maximally preserve visual information without any attention involvement. We present ApET, an Approximation-Error guided Token compression framework. ApET first reconstructs the original visual tokens with a small set of basis tokens via linear approximation, then leverages the approximation error to identify and drop the least informative tokens. Extensive experiments across multiple VLMs and benchmarks demonstrate that ApET retains 95.2% of the original performance on image-understanding tasks and even attains 100.4% on video-understanding tasks, while compressing the token budgets by 88.9% and 87.5%, respectively. Thanks to its attention-free design, ApET seamlessly integrates with FlashAttention, enabling further inference acceleration and making VLM deployment more practical. Code is available at https://github.com/MaQianKun0/ApET.
Multimodal Priors-Augmented Text-Driven 3D Human-Object Interaction Generation
Feb 11, 2026We address the challenging task of text-driven 3D human-object interaction (HOI) motion generation. Existing methods primarily rely on a direct text-to-HOI mapping, which suffers from three key limitations due to the significant cross-modality gap: (Q1) sub-optimal human motion, (Q2) unnatural object motion, and (Q3) weak interaction between humans and objects. To address these challenges, we propose MP-HOI, a novel framework grounded in four core insights: (1) Multimodal Data Priors: We leverage multimodal data (text, image, pose/object) from large multimodal models as priors to guide HOI generation, which tackles Q1 and Q2 in data modeling. (2) Enhanced Object Representation: We improve existing object representations by incorporating geometric keypoints, contact features, and dynamic properties, enabling expressive object representations, which tackles Q2 in data representation. (3) Multimodal-Aware Mixture-of-Experts (MoE) Model: We propose a modality-aware MoE model for effective multimodal feature fusion paradigm, which tackles Q1 and Q2 in feature fusion. (4) Cascaded Diffusion with Interaction Supervision: We design a cascaded diffusion framework that progressively refines human-object interaction features under dedicated supervision, which tackles Q3 in interaction refinement. Comprehensive experiments demonstrate that MP-HOI outperforms existing approaches in generating high-fidelity and fine-grained HOI motions.
Unseen Speaker and Language Adaptation for Lightweight Text-To-Speech with Adapters
Aug 25, 2025In this paper we investigate cross-lingual Text-To-Speech (TTS) synthesis through the lens of adapters, in the context of lightweight TTS systems. In particular, we compare the tasks of unseen speaker and language adaptation with the goal of synthesising a target voice in a target language, in which the target voice has no recordings therein. Results from objective evaluations demonstrate the effectiveness of adapters in learning language-specific and speaker-specific information, allowing pre-trained models to learn unseen speaker identities or languages, while avoiding catastrophic forgetting of the original model's speaker or language information. Additionally, to measure how native the generated voices are in terms of accent, we propose and validate an objective metric inspired by mispronunciation detection techniques in second-language (L2) learners. The paper also provides insights into the impact of adapter placement, configuration and the number of speakers used.
Fg-T2M++: LLMs-Augmented Fine-Grained Text Driven Human Motion Generation
Feb 08, 2025We address the challenging problem of fine-grained text-driven human motion generation. Existing works generate imprecise motions that fail to accurately capture relationships specified in text due to: (1) lack of effective text parsing for detailed semantic cues regarding body parts, (2) not fully modeling linguistic structures between words to comprehend text comprehensively. To tackle these limitations, we propose a novel fine-grained framework Fg-T2M++ that consists of: (1) an LLMs semantic parsing module to extract body part descriptions and semantics from text, (2) a hyperbolic text representation module to encode relational information between text units by embedding the syntactic dependency graph into hyperbolic space, and (3) a multi-modal fusion module to hierarchically fuse text and motion features. Extensive experiments on HumanML3D and KIT-ML datasets demonstrate that Fg-T2M++ outperforms SOTA methods, validating its ability to accurately generate motions adhering to comprehensive text semantics.
LLM Hallucinations in Practical Code Generation: Phenomena, Mechanism, and Mitigation
Sep 30, 2024

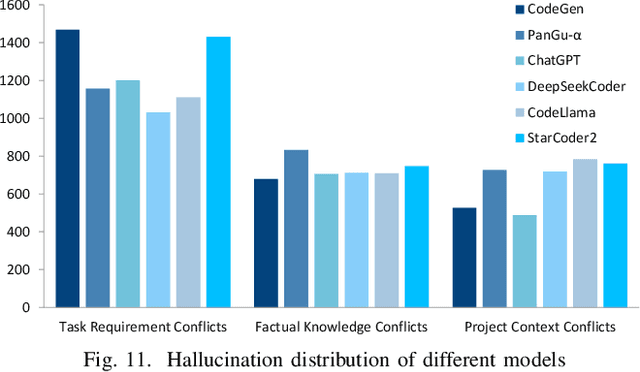
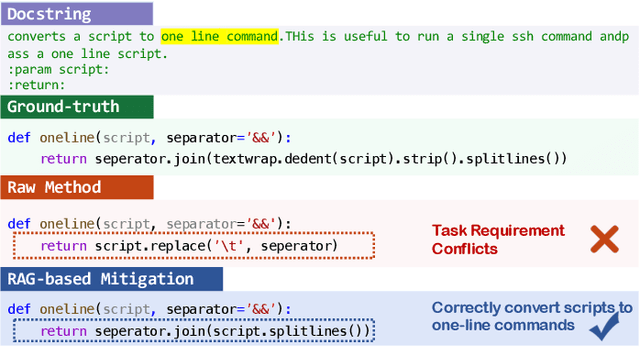
Code generation aims to automatically generate code from input requirements, significantly enhancing development efficiency. Recent large language models (LLMs) based approaches have shown promising results and revolutionized code generation task. Despite the promising performance, LLMs often generate contents with hallucinations, especially for the code generation scenario requiring the handling of complex contextual dependencies in practical development process. Although previous study has analyzed hallucinations in LLM-powered code generation, the study is limited to standalone function generation. In this paper, we conduct an empirical study to study the phenomena, mechanism, and mitigation of LLM hallucinations within more practical and complex development contexts in repository-level generation scenario. First, we manually examine the code generation results from six mainstream LLMs to establish a hallucination taxonomy of LLM-generated code. Next, we elaborate on the phenomenon of hallucinations, analyze their distribution across different models. We then analyze causes of hallucinations and identify four potential factors contributing to hallucinations. Finally, we propose an RAG-based mitigation method, which demonstrates consistent effectiveness in all studied LLMs. The replication package including code, data, and experimental results is available at https://github.com/DeepSoftwareAnalytics/LLMCodingHallucination
Cross-lingual Knowledge Distillation via Flow-based Voice Conversion for Robust Polyglot Text-To-Speech
Sep 15, 2023In this work, we introduce a framework for cross-lingual speech synthesis, which involves an upstream Voice Conversion (VC) model and a downstream Text-To-Speech (TTS) model. The proposed framework consists of 4 stages. In the first two stages, we use a VC model to convert utterances in the target locale to the voice of the target speaker. In the third stage, the converted data is combined with the linguistic features and durations from recordings in the target language, which are then used to train a single-speaker acoustic model. Finally, the last stage entails the training of a locale-independent vocoder. Our evaluations show that the proposed paradigm outperforms state-of-the-art approaches which are based on training a large multilingual TTS model. In addition, our experiments demonstrate the robustness of our approach with different model architectures, languages, speakers and amounts of data. Moreover, our solution is especially beneficial in low-resource settings.
First Glance Diagnosis: Brain Disease Classification with Single fMRI Volume
Aug 10, 2022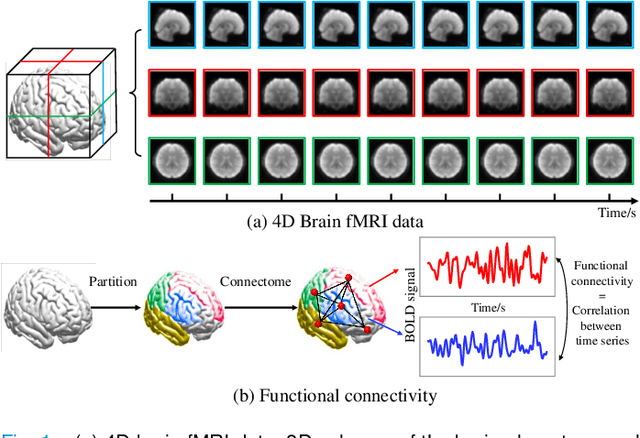
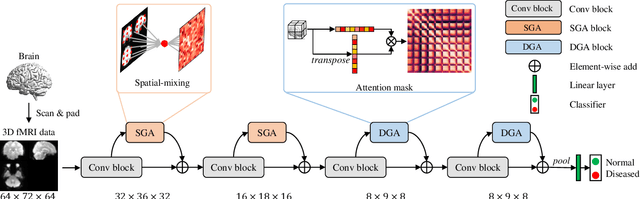

In neuroimaging analysis, functional magnetic resonance imaging (fMRI) can well assess brain function changes for brain diseases with no obvious structural lesions. So far, most deep-learning-based fMRI studies take functional connectivity as the basic feature in disease classification. However, functional connectivity is often calculated based on time series of predefined regions of interest and neglects detailed information contained in each voxel, which may accordingly deteriorate the performance of diagnostic models. Another methodological drawback is the limited sample size for the training of deep models. In this study, we propose BrainFormer, a general hybrid Transformer architecture for brain disease classification with single fMRI volume to fully exploit the voxel-wise details with sufficient data dimensions and sizes. BrainFormer is constructed by modeling the local cues within each voxel with 3D convolutions and capturing the global relations among distant regions with two global attention blocks. The local and global cues are aggregated in BrainFormer by a single-stream model. To handle multisite data, we propose a normalization layer to normalize the data into identical distribution. Finally, a Gradient-based Localization-map Visualization method is utilized for locating the possible disease-related biomarker. We evaluate BrainFormer on five independently acquired datasets including ABIDE, ADNI, MPILMBB, ADHD-200 and ECHO, with diseases of autism, Alzheimer's disease, depression, attention deficit hyperactivity disorder, and headache disorders. The results demonstrate the effectiveness and generalizability of BrainFormer for multiple brain diseases diagnosis. BrainFormer may promote neuroimaging-based precision diagnosis in clinical practice and motivate future study in fMRI analysis. Code is available at: https://github.com/ZiyaoZhangforPCL/BrainFormer.
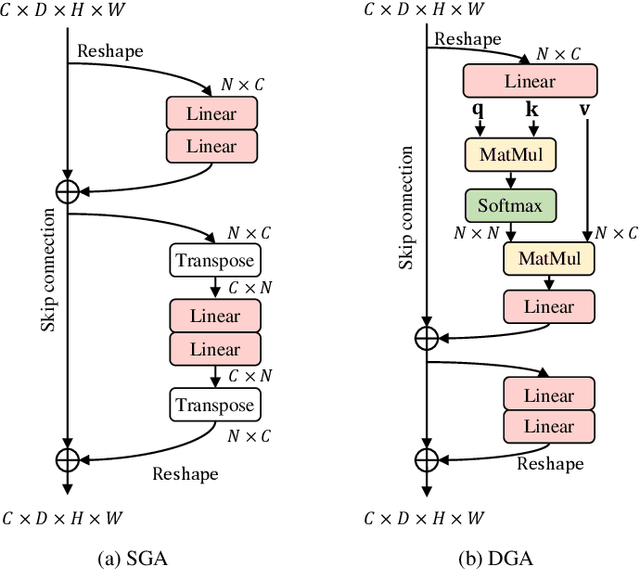
Unify and Conquer: How Phonetic Feature Representation Affects Polyglot Text-To-Speech (TTS)
Jul 04, 2022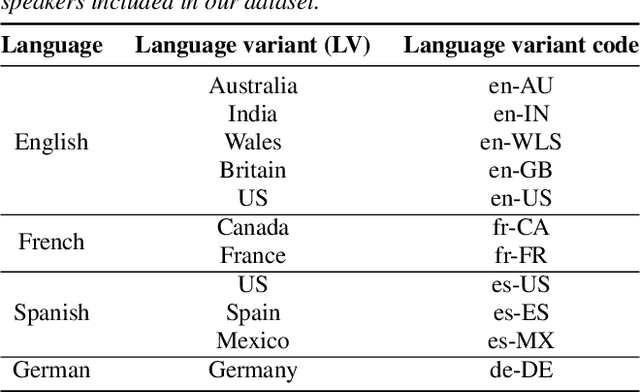
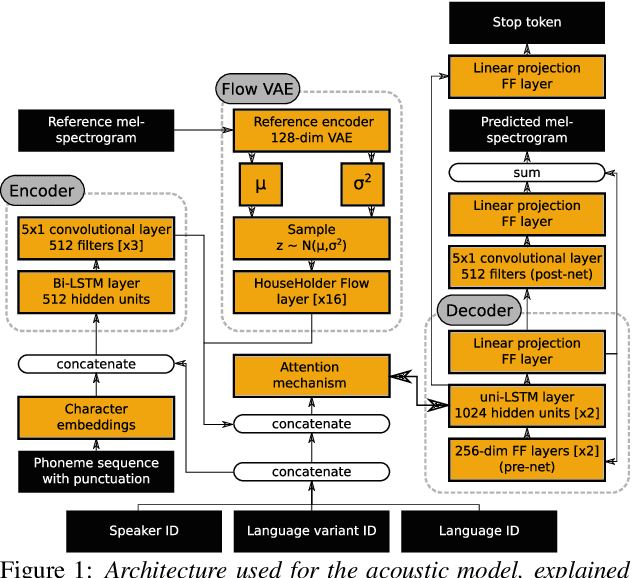
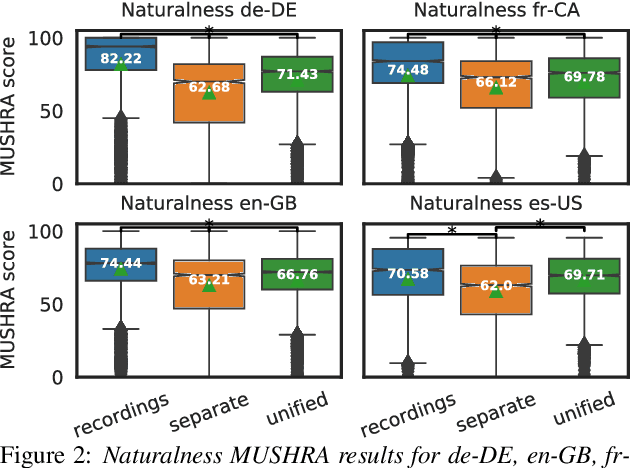
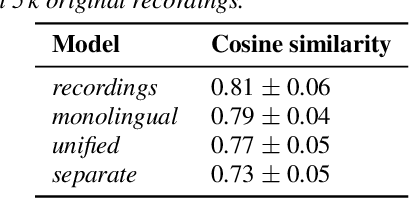
An essential design decision for multilingual Neural Text-To-Speech (NTTS) systems is how to represent input linguistic features within the model. Looking at the wide variety of approaches in the literature, two main paradigms emerge, unified and separate representations. The former uses a shared set of phonetic tokens across languages, whereas the latter uses unique phonetic tokens for each language. In this paper, we conduct a comprehensive study comparing multilingual NTTS systems models trained with both representations. Our results reveal that the unified approach consistently achieves better cross-lingual synthesis with respect to both naturalness and accent. Separate representations tend to have an order of magnitude more tokens than unified ones, which may affect model capacity. For this reason, we carry out an ablation study to understand the interaction of the representation type with the size of the token embedding. We find that the difference between the two paradigms only emerges above a certain threshold embedding size. This study provides strong evidence that unified representations should be the preferred paradigm when building multilingual NTTS systems.
Mix and Match: An Empirical Study on Training Corpus Composition for Polyglot Text-To-Speech
Jul 04, 2022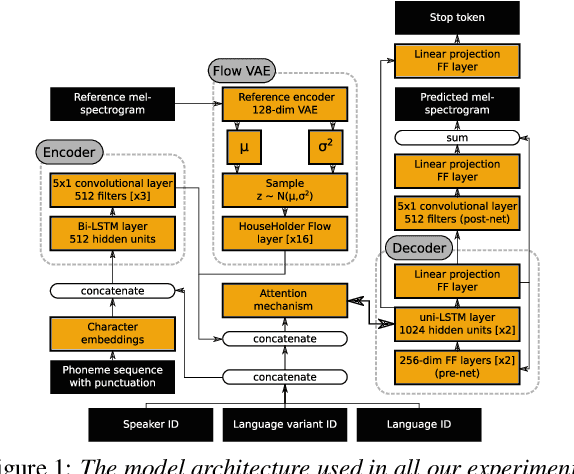
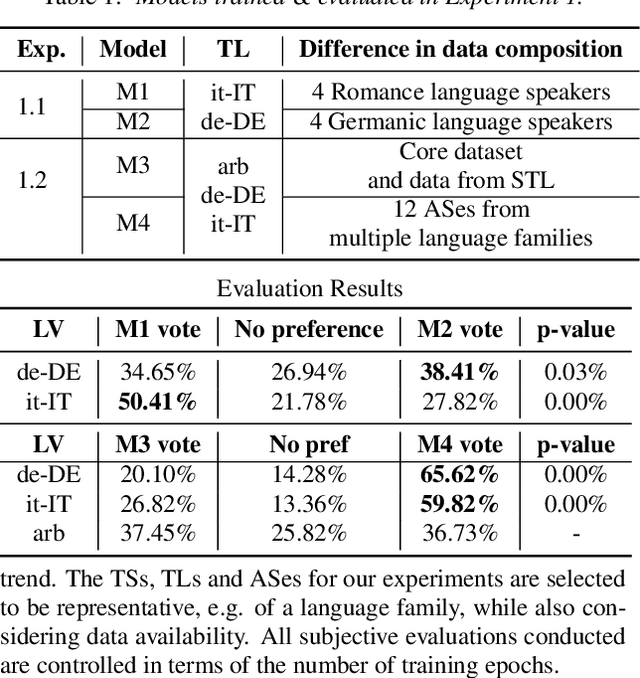
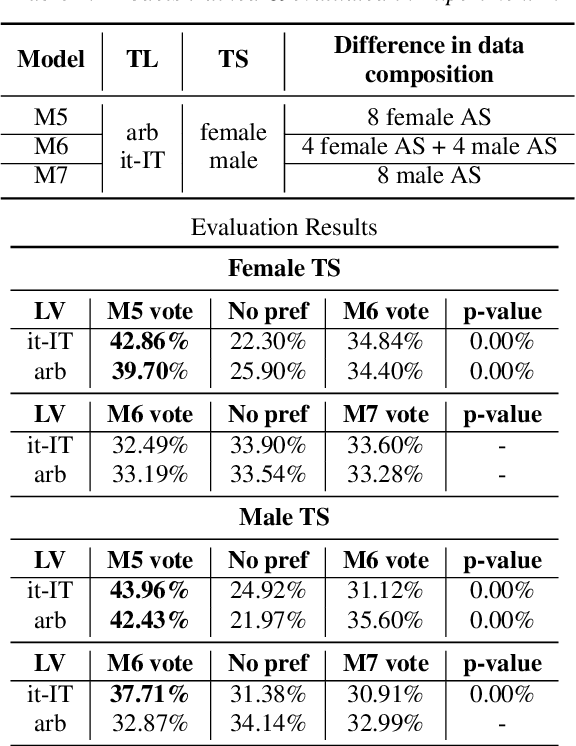
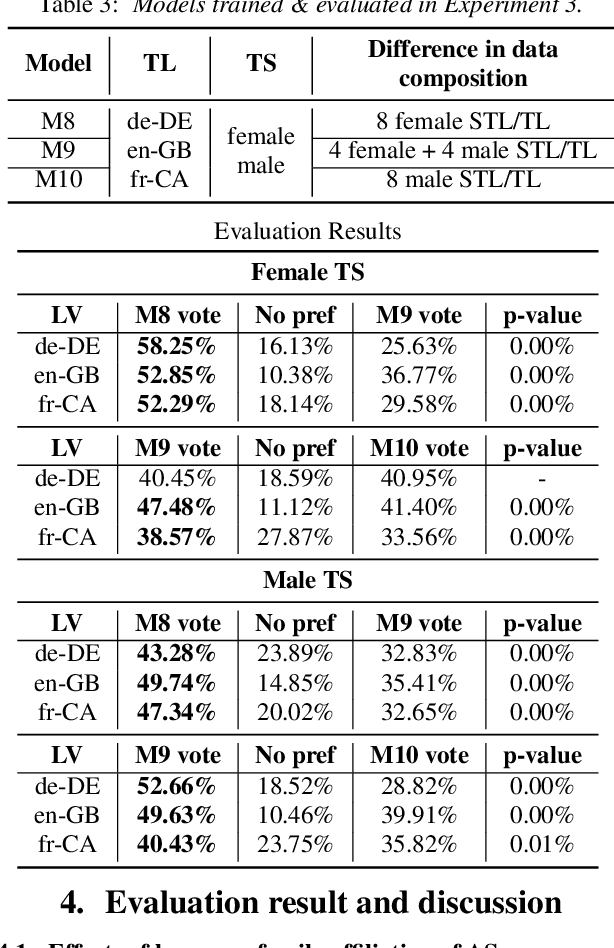
Training multilingual Neural Text-To-Speech (NTTS) models using only monolingual corpora has emerged as a popular way for building voice cloning based Polyglot NTTS systems. In order to train these models, it is essential to understand how the composition of the training corpora affects the quality of multilingual speech synthesis. In this context, it is common to hear questions such as "Would including more Spanish data help my Italian synthesis, given the closeness of both languages?". Unfortunately, we found existing literature on the topic lacking in completeness in this regard. In the present work, we conduct an extensive ablation study aimed at understanding how various factors of the training corpora, such as language family affiliation, gender composition, and the number of speakers, contribute to the quality of Polyglot synthesis. Our findings include the observation that female speaker data are preferred in most scenarios, and that it is not always beneficial to have more speakers from the target language variant in the training corpus. The findings herein are informative for the process of data procurement and corpora building.
State Action Separable Reinforcement Learning
Jun 05, 2020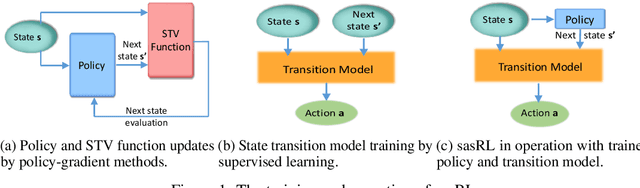
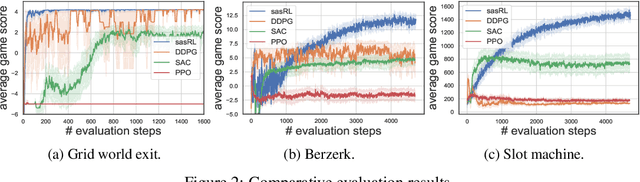
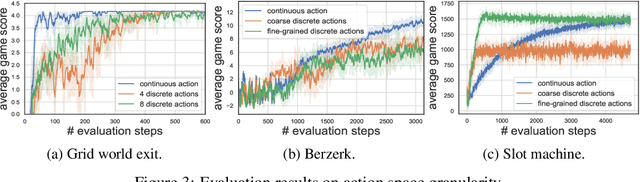
Reinforcement Learning (RL) based methods have seen their paramount successes in solving serial decision-making and control problems in recent years. For conventional RL formulations, Markov Decision Process (MDP) and state-action-value function are the basis for the problem modeling and policy evaluation. However, several challenging issues still remain. Among most cited issues, the enormity of state/action space is an important factor that causes inefficiency in accurately approximating the state-action-value function. We observe that although actions directly define the agents' behaviors, for many problems the next state after a state transition matters more than the action taken, in determining the return of such a state transition. In this regard, we propose a new learning paradigm, State Action Separable Reinforcement Learning (sasRL), wherein the action space is decoupled from the value function learning process for higher efficiency. Then, a light-weight transition model is learned to assist the agent to determine the action that triggers the associated state transition. In addition, our convergence analysis reveals that under certain conditions, the convergence time of sasRL is $O(T^{1/k})$, where $T$ is the convergence time for updating the value function in the MDP-based formulation and $k$ is a weighting factor. Experiments on several gaming scenarios show that sasRL outperforms state-of-the-art MDP-based RL algorithms by up to $75\%$.