 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnify and Conquer: How Phonetic Feature Representation Affects Polyglot Text-To-Speech (TTS)
Jul 04, 2022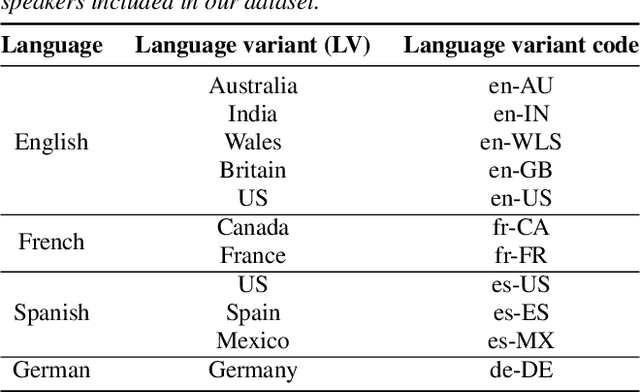
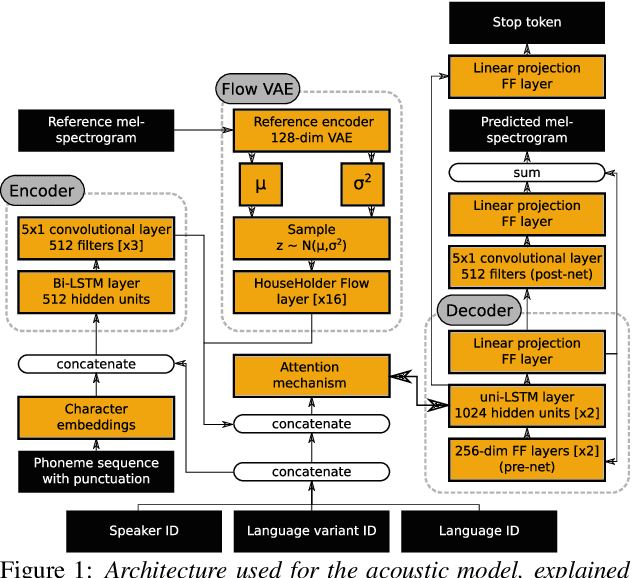
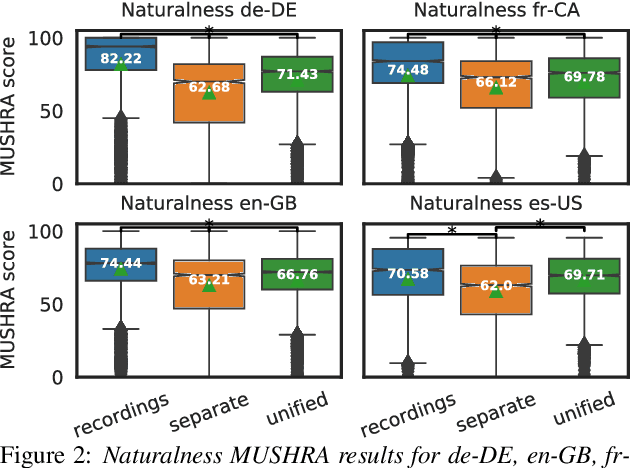
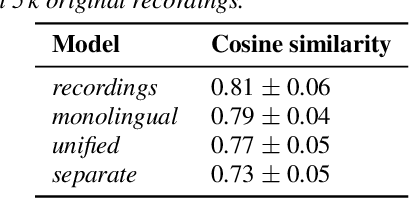
An essential design decision for multilingual Neural Text-To-Speech (NTTS) systems is how to represent input linguistic features within the model. Looking at the wide variety of approaches in the literature, two main paradigms emerge, unified and separate representations. The former uses a shared set of phonetic tokens across languages, whereas the latter uses unique phonetic tokens for each language. In this paper, we conduct a comprehensive study comparing multilingual NTTS systems models trained with both representations. Our results reveal that the unified approach consistently achieves better cross-lingual synthesis with respect to both naturalness and accent. Separate representations tend to have an order of magnitude more tokens than unified ones, which may affect model capacity. For this reason, we carry out an ablation study to understand the interaction of the representation type with the size of the token embedding. We find that the difference between the two paradigms only emerges above a certain threshold embedding size. This study provides strong evidence that unified representations should be the preferred paradigm when building multilingual NTTS systems.
Mix and Match: An Empirical Study on Training Corpus Composition for Polyglot Text-To-Speech
Jul 04, 2022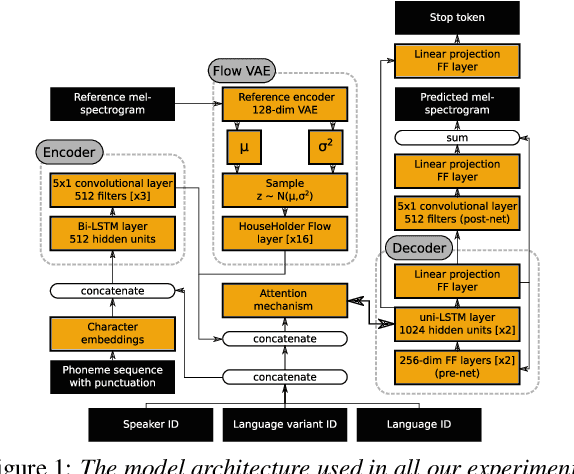
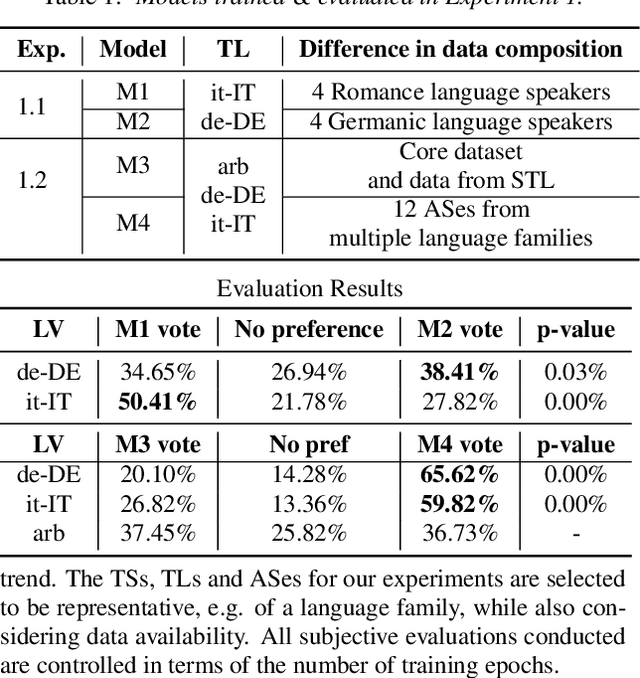
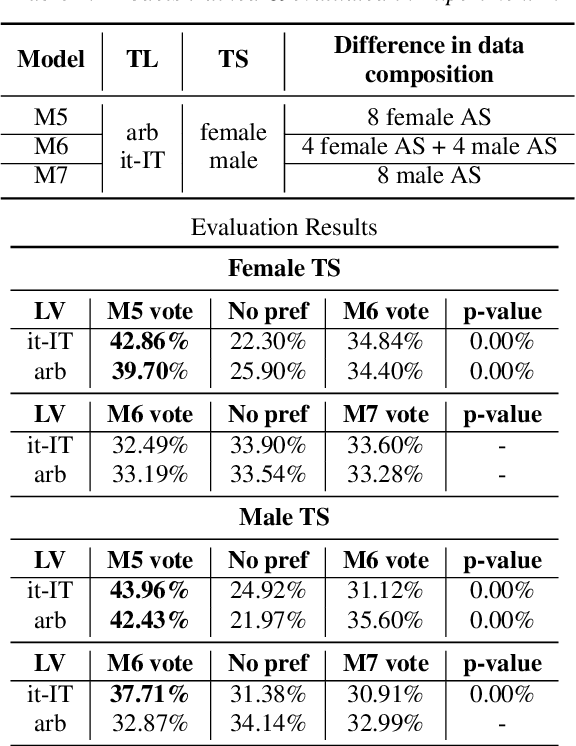
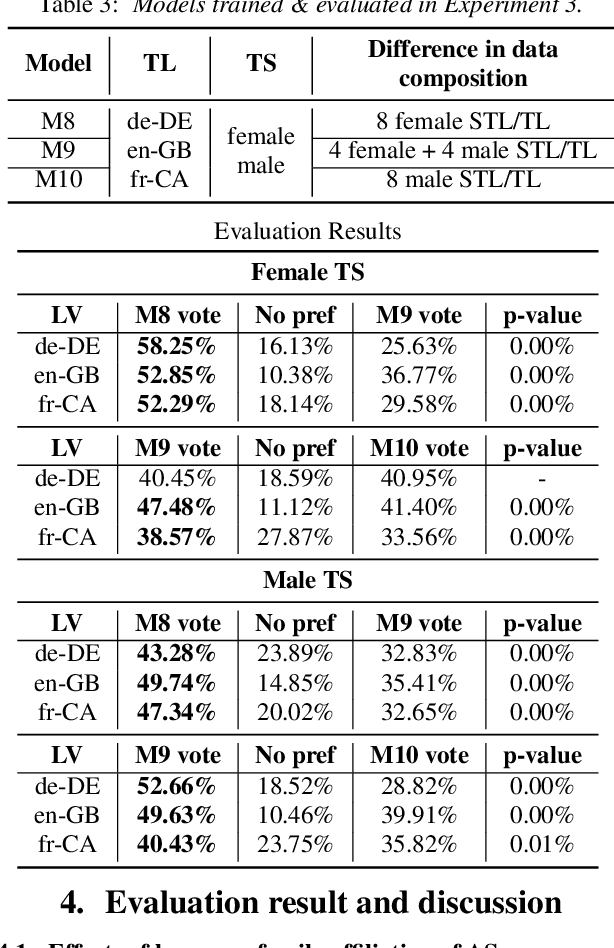
Training multilingual Neural Text-To-Speech (NTTS) models using only monolingual corpora has emerged as a popular way for building voice cloning based Polyglot NTTS systems. In order to train these models, it is essential to understand how the composition of the training corpora affects the quality of multilingual speech synthesis. In this context, it is common to hear questions such as "Would including more Spanish data help my Italian synthesis, given the closeness of both languages?". Unfortunately, we found existing literature on the topic lacking in completeness in this regard. In the present work, we conduct an extensive ablation study aimed at understanding how various factors of the training corpora, such as language family affiliation, gender composition, and the number of speakers, contribute to the quality of Polyglot synthesis. Our findings include the observation that female speaker data are preferred in most scenarios, and that it is not always beneficial to have more speakers from the target language variant in the training corpus. The findings herein are informative for the process of data procurement and corpora building.
Singing Synthesis: with a little help from my attention
Dec 12, 2019


We present a novel system for singing synthesis, based on attention. Starting from a musical score with notes and lyrics, we build a phoneme-level multi stream note embedding. The embedding contains the information encoded in the score regarding pitch, duration and the phonemes to be pronounced on each note. This note representation is used to condition an attention-based sequence-to-sequence architecture, in order to generate mel-spectrograms. Our model demonstrates attention can be successfully applied to the singing synthesis field. The system requires considerably less explicit modelling of voice features such as F0 patterns, vibratos, and note and phoneme durations, than most models in the literature. However, we observe that completely dispensing with any duration modelling introduces occasional instabilities in the generated spectrograms. We train an autoregressive WaveNet to be used as a neural vocoder to synthesise the mel-spectrograms produced by the sequence-to-sequence architecture, using a combination of speech and singing data.