 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Priors-Augmented Text-Driven 3D Human-Object Interaction Generation
Feb 11, 2026We address the challenging task of text-driven 3D human-object interaction (HOI) motion generation. Existing methods primarily rely on a direct text-to-HOI mapping, which suffers from three key limitations due to the significant cross-modality gap: (Q1) sub-optimal human motion, (Q2) unnatural object motion, and (Q3) weak interaction between humans and objects. To address these challenges, we propose MP-HOI, a novel framework grounded in four core insights: (1) Multimodal Data Priors: We leverage multimodal data (text, image, pose/object) from large multimodal models as priors to guide HOI generation, which tackles Q1 and Q2 in data modeling. (2) Enhanced Object Representation: We improve existing object representations by incorporating geometric keypoints, contact features, and dynamic properties, enabling expressive object representations, which tackles Q2 in data representation. (3) Multimodal-Aware Mixture-of-Experts (MoE) Model: We propose a modality-aware MoE model for effective multimodal feature fusion paradigm, which tackles Q1 and Q2 in feature fusion. (4) Cascaded Diffusion with Interaction Supervision: We design a cascaded diffusion framework that progressively refines human-object interaction features under dedicated supervision, which tackles Q3 in interaction refinement. Comprehensive experiments demonstrate that MP-HOI outperforms existing approaches in generating high-fidelity and fine-grained HOI motions.
Dynamic Worlds, Dynamic Humans: Generating Virtual Human-Scene Interaction Motion in Dynamic Scenes
Jan 27, 2026Scenes are continuously undergoing dynamic changes in the real world. However, existing human-scene interaction generation methods typically treat the scene as static, which deviates from reality. Inspired by world models, we introduce Dyn-HSI, the first cognitive architecture for dynamic human-scene interaction, which endows virtual humans with three humanoid components. (1)Vision (human eyes): we equip the virtual human with a Dynamic Scene-Aware Navigation, which continuously perceives changes in the surrounding environment and adaptively predicts the next waypoint. (2)Memory (human brain): we equip the virtual human with a Hierarchical Experience Memory, which stores and updates experiential data accumulated during training. This allows the model to leverage prior knowledge during inference for context-aware motion priming, thereby enhancing both motion quality and generalization. (3) Control (human body): we equip the virtual human with Human-Scene Interaction Diffusion Model, which generates high-fidelity interaction motions conditioned on multimodal inputs. To evaluate performance in dynamic scenes, we extend the existing static human-scene interaction datasets to construct a dynamic benchmark, Dyn-Scenes. We conduct extensive qualitative and quantitative experiments to validate Dyn-HSI, showing that our method consistently outperforms existing approaches and generates high-quality human-scene interaction motions in both static and dynamic settings.
MOST: Motion Diffusion Model for Rare Text via Temporal Clip Banzhaf Interaction
Jul 09, 2025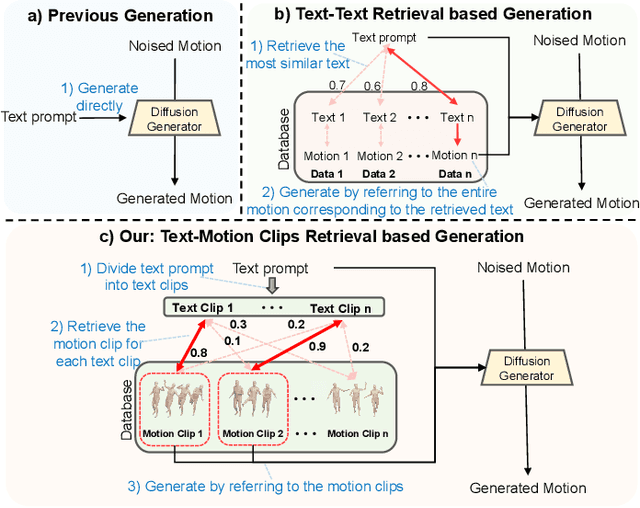
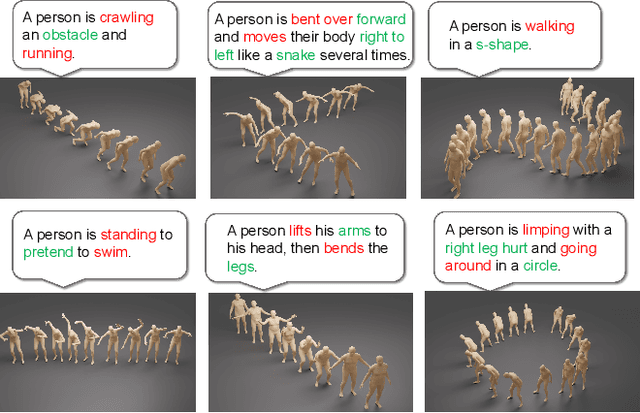

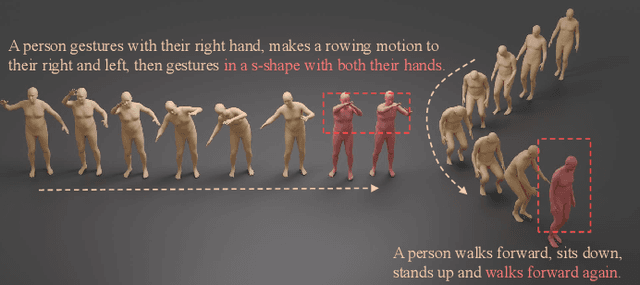
We introduce MOST, a novel motion diffusion model via temporal clip Banzhaf interaction, aimed at addressing the persistent challenge of generating human motion from rare language prompts. While previous approaches struggle with coarse-grained matching and overlook important semantic cues due to motion redundancy, our key insight lies in leveraging fine-grained clip relationships to mitigate these issues. MOST's retrieval stage presents the first formulation of its kind - temporal clip Banzhaf interaction - which precisely quantifies textual-motion coherence at the clip level. This facilitates direct, fine-grained text-to-motion clip matching and eliminates prevalent redundancy. In the generation stage, a motion prompt module effectively utilizes retrieved motion clips to produce semantically consistent movements. Extensive evaluations confirm that MOST achieves state-of-the-art text-to-motion retrieval and generation performance by comprehensively addressing previous challenges, as demonstrated through quantitative and qualitative results highlighting its effectiveness, especially for rare prompts.
Fg-T2M++: LLMs-Augmented Fine-Grained Text Driven Human Motion Generation
Feb 08, 2025We address the challenging problem of fine-grained text-driven human motion generation. Existing works generate imprecise motions that fail to accurately capture relationships specified in text due to: (1) lack of effective text parsing for detailed semantic cues regarding body parts, (2) not fully modeling linguistic structures between words to comprehend text comprehensively. To tackle these limitations, we propose a novel fine-grained framework Fg-T2M++ that consists of: (1) an LLMs semantic parsing module to extract body part descriptions and semantics from text, (2) a hyperbolic text representation module to encode relational information between text units by embedding the syntactic dependency graph into hyperbolic space, and (3) a multi-modal fusion module to hierarchically fuse text and motion features. Extensive experiments on HumanML3D and KIT-ML datasets demonstrate that Fg-T2M++ outperforms SOTA methods, validating its ability to accurately generate motions adhering to comprehensive text semantics.
HyperSDFusion: Bridging Hierarchical Structures in Language and Geometry for Enhanced 3D Text2Shape Generation
Mar 01, 20243D shape generation from text is a fundamental task in 3D representation learning. The text-shape pairs exhibit a hierarchical structure, where a general text like "chair" covers all 3D shapes of the chair, while more detailed prompts refer to more specific shapes. Furthermore, both text and 3D shapes are inherently hierarchical structures. However, existing Text2Shape methods, such as SDFusion, do not exploit that. In this work, we propose HyperSDFusion, a dual-branch diffusion model that generates 3D shapes from a given text. Since hyperbolic space is suitable for handling hierarchical data, we propose to learn the hierarchical representations of text and 3D shapes in hyperbolic space. First, we introduce a hyperbolic text-image encoder to learn the sequential and multi-modal hierarchical features of text in hyperbolic space. In addition, we design a hyperbolic text-graph convolution module to learn the hierarchical features of text in hyperbolic space. In order to fully utilize these text features, we introduce a dual-branch structure to embed text features in 3D feature space. At last, to endow the generated 3D shapes with a hierarchical structure, we devise a hyperbolic hierarchical loss. Our method is the first to explore the hyperbolic hierarchical representation for text-to-shape generation. Experimental results on the existing text-to-shape paired dataset, Text2Shape, achieved state-of-the-art results.
HACD: Hand-Aware Conditional Diffusion for Monocular Hand-Held Object Reconstruction
Nov 23, 2023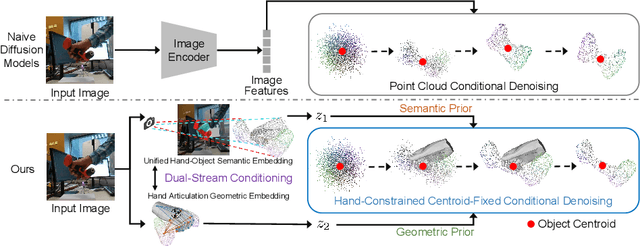
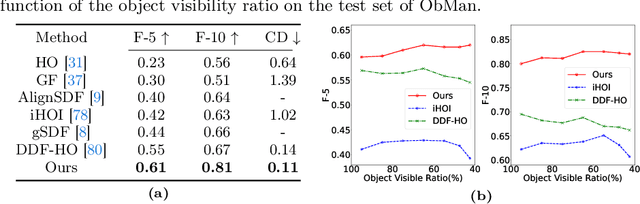
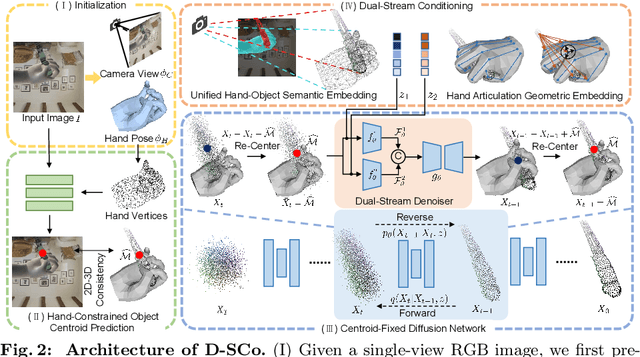
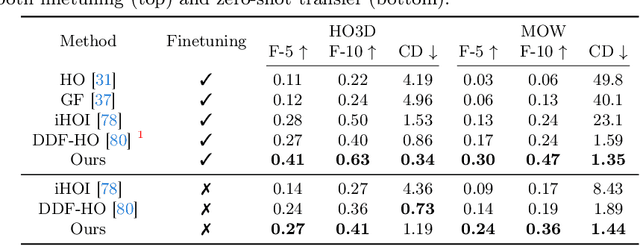
Reconstructing hand-held objects from a single RGB image without known 3D object templates, category prior, or depth information is a vital yet challenging problem in computer vision. In contrast to prior works that utilize deterministic modeling paradigms, which make it hard to account for the uncertainties introduced by hand- and self-occlusion, we employ a probabilistic point cloud denoising diffusion model to tackle the above challenge. In this work, we present Hand-Aware Conditional Diffusion for monocular hand-held object reconstruction (HACD), modeling the hand-object interaction in two aspects. First, we introduce hand-aware conditioning to model hand-object interaction from both semantic and geometric perspectives. Specifically, a unified hand-object semantic embedding compensates for the 2D local feature deficiency induced by hand occlusion, and a hand articulation embedding further encodes the relationship between object vertices and hand joints. Second, we propose a hand-constrained centroid fixing scheme, which utilizes hand vertices priors to restrict the centroid deviation of partially denoised point cloud during diffusion and reverse process. Removing the centroid bias interference allows the diffusion models to focus on the reconstruction of shape, thus enhancing the stability and precision of local feature projection. Experiments on the synthetic ObMan dataset and two real-world datasets, HO3D and MOW, demonstrate our approach surpasses all existing methods by a large margin.
Fg-T2M: Fine-Grained Text-Driven Human Motion Generation via Diffusion Model
Sep 12, 2023



Text-driven human motion generation in computer vision is both significant and challenging. However, current methods are limited to producing either deterministic or imprecise motion sequences, failing to effectively control the temporal and spatial relationships required to conform to a given text description. In this work, we propose a fine-grained method for generating high-quality, conditional human motion sequences supporting precise text description. Our approach consists of two key components: 1) a linguistics-structure assisted module that constructs accurate and complete language feature to fully utilize text information; and 2) a context-aware progressive reasoning module that learns neighborhood and overall semantic linguistics features from shallow and deep graph neural networks to achieve a multi-step inference. Experiments show that our approach outperforms text-driven motion generation methods on HumanML3D and KIT test sets and generates better visually confirmed motion to the text conditions.
Dynamic Hyperbolic Attention Network for Fine Hand-object Reconstruction
Sep 06, 2023Reconstructing both objects and hands in 3D from a single RGB image is complex. Existing methods rely on manually defined hand-object constraints in Euclidean space, leading to suboptimal feature learning. Compared with Euclidean space, hyperbolic space better preserves the geometric properties of meshes thanks to its exponentially-growing space distance, which amplifies the differences between the features based on similarity. In this work, we propose the first precise hand-object reconstruction method in hyperbolic space, namely Dynamic Hyperbolic Attention Network (DHANet), which leverages intrinsic properties of hyperbolic space to learn representative features. Our method that projects mesh and image features into a unified hyperbolic space includes two modules, ie. dynamic hyperbolic graph convolution and image-attention hyperbolic graph convolution. With these two modules, our method learns mesh features with rich geometry-image multi-modal information and models better hand-object interaction. Our method provides a promising alternative for fine hand-object reconstruction in hyperbolic space. Extensive experiments on three public datasets demonstrate that our method outperforms most state-of-the-art methods.