 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Resource-efficient Machine Learning Aided Viewport Prediction in Virtual Reality
Dec 20, 2022



360-degree panoramic videos have gained considerable attention in recent years due to the rapid development of head-mounted displays (HMDs) and panoramic cameras. One major problem in streaming panoramic videos is that panoramic videos are much larger in size compared to traditional ones. Moreover, the user devices are often in a wireless environment, with limited battery, computation power, and bandwidth. To reduce resource consumption, researchers have proposed ways to predict the users' viewports so that only part of the entire video needs to be transmitted from the server. However, the robustness of such prediction approaches has been overlooked in the literature: it is usually assumed that only a few models, pre-trained on past users' experiences, are applied for prediction to all users. We observe that those pre-trained models can perform poorly for some users because they might have drastically different behaviors from the majority, and the pre-trained models cannot capture the features in unseen videos. In this work, we propose a novel meta learning based viewport prediction paradigm to alleviate the worst prediction performance and ensure the robustness of viewport prediction. This paradigm uses two machine learning models, where the first model predicts the viewing direction, and the second model predicts the minimum video prefetch size that can include the actual viewport. We first train two meta models so that they are sensitive to new training data, and then quickly adapt them to users while they are watching the videos. Evaluation results reveal that the meta models can adapt quickly to each user, and can significantly increase the prediction accuracy, especially for the worst-performing predictions.
State Action Separable Reinforcement Learning
Jun 05, 2020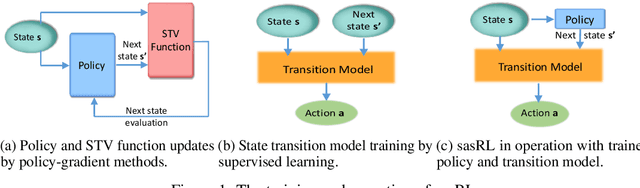
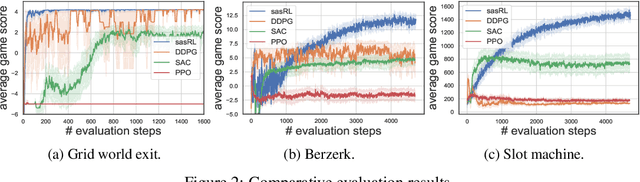
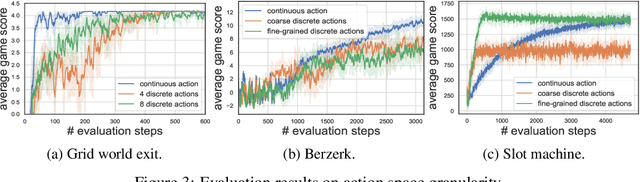
Reinforcement Learning (RL) based methods have seen their paramount successes in solving serial decision-making and control problems in recent years. For conventional RL formulations, Markov Decision Process (MDP) and state-action-value function are the basis for the problem modeling and policy evaluation. However, several challenging issues still remain. Among most cited issues, the enormity of state/action space is an important factor that causes inefficiency in accurately approximating the state-action-value function. We observe that although actions directly define the agents' behaviors, for many problems the next state after a state transition matters more than the action taken, in determining the return of such a state transition. In this regard, we propose a new learning paradigm, State Action Separable Reinforcement Learning (sasRL), wherein the action space is decoupled from the value function learning process for higher efficiency. Then, a light-weight transition model is learned to assist the agent to determine the action that triggers the associated state transition. In addition, our convergence analysis reveals that under certain conditions, the convergence time of sasRL is $O(T^{1/k})$, where $T$ is the convergence time for updating the value function in the MDP-based formulation and $k$ is a weighting factor. Experiments on several gaming scenarios show that sasRL outperforms state-of-the-art MDP-based RL algorithms by up to $75\%$.
MACS: Deep Reinforcement Learning based SDN Controller Synchronization Policy Design
Sep 19, 2019
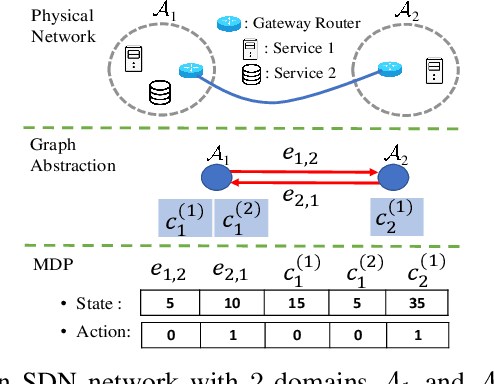
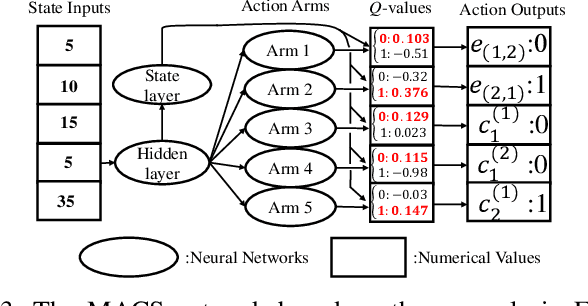

In distributed software-defined networks (SDN), multiple physical SDN controllers, each managing a network domain, are implemented to balance centralised control, scalability, and reliability requirements. In such networking paradigms, controllers synchronize with each other, in attempts to maintain a logically centralised network view. Despite the presence of various design proposals for distributed SDN controller architectures, most existing works only aim at eliminating anomalies arising from the inconsistencies in different controllers' network views. However, the performance aspect of controller synchronization designs with respect to given SDN applications are generally missing. To fill this gap, we formulate the controller synchronization problem as a Markov decision process (MDP) and apply reinforcement learning techniques combined with deep neural networks (DNNs) to train a smart, scalable, and fine-grained controller synchronization policy, called the Multi-Armed Cooperative Synchronization (MACS), whose goal is to maximise the performance enhancements brought by controller synchronizations. Evaluation results confirm the DNN's exceptional ability in abstracting latent patterns in the distributed SDN environment, rendering significant superiority to MACS-based synchronization policy, which are 56% and 30% performance improvements over ONOS and greedy SDN controller synchronization heuristics.