 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations
Sep 28, 2021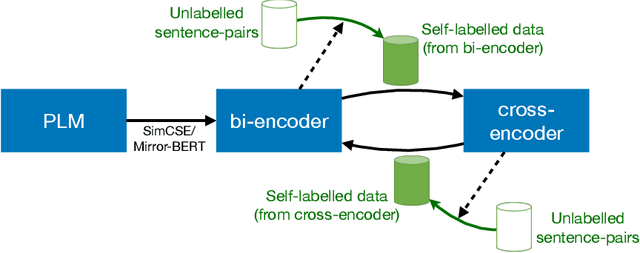
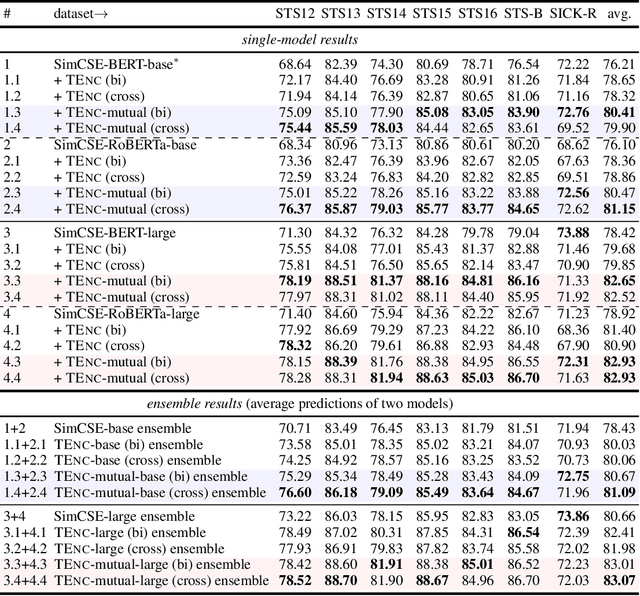
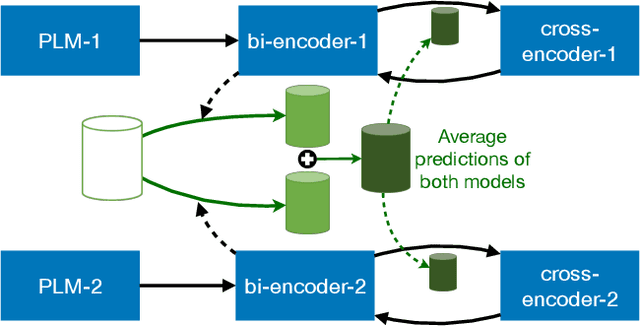
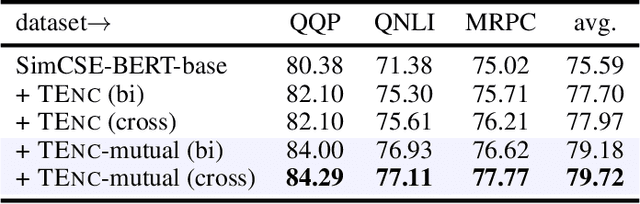
In NLP, a large volume of tasks involve pairwise comparison between two sequences (e.g. sentence similarity and paraphrase identification). Predominantly, two formulations are used for sentence-pair tasks: bi-encoders and cross-encoders. Bi-encoders produce fixed-dimensional sentence representations and are computationally efficient, however, they usually underperform cross-encoders. Cross-encoders can leverage their attention heads to exploit inter-sentence interactions for better performance but they require task fine-tuning and are computationally more expensive. In this paper, we present a completely unsupervised sentence representation model termed as Trans-Encoder that combines the two learning paradigms into an iterative joint framework to simultaneously learn enhanced bi- and cross-encoders. Specifically, on top of a pre-trained Language Model (PLM), we start with converting it to an unsupervised bi-encoder, and then alternate between the bi- and cross-encoder task formulations. In each alternation, one task formulation will produce pseudo-labels which are used as learning signals for the other task formulation. We then propose an extension to conduct such self-distillation approach on multiple PLMs in parallel and use the average of their pseudo-labels for mutual-distillation. Trans-Encoder creates, to the best of our knowledge, the first completely unsupervised cross-encoder and also a state-of-the-art unsupervised bi-encoder for sentence similarity. Both the bi-encoder and cross-encoder formulations of Trans-Encoder outperform recently proposed state-of-the-art unsupervised sentence encoders such as Mirror-BERT and SimCSE by up to 5% on the sentence similarity benchmarks.
Preventing Posterior Collapse with Levenshtein Variational Autoencoder
Apr 30, 2020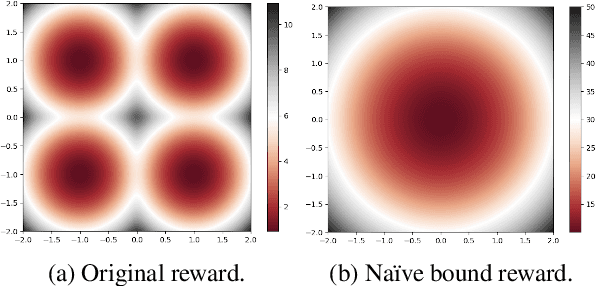
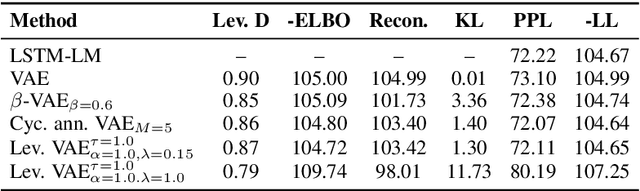
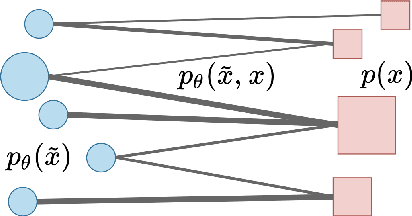

Variational autoencoders (VAEs) are a standard framework for inducing latent variable models that have been shown effective in learning text representations as well as in text generation. The key challenge with using VAEs is the {\it posterior collapse} problem: learning tends to converge to trivial solutions where the generators ignore latent variables. In our Levenstein VAE, we propose to replace the evidence lower bound (ELBO) with a new objective which is simple to optimize and prevents posterior collapse. Intuitively, it corresponds to generating a sequence from the autoencoder and encouraging the model to predict an optimal continuation according to the Levenshtein distance (LD) with the reference sentence at each time step in the generated sequence. We motivate the method from the probabilistic perspective by showing that it is closely related to optimizing a bound on the intractable Kullback-Leibler divergence of an LD-based kernel density estimator from the model distribution. With this objective, any generator disregarding latent variables will incur large penalties and hence posterior collapse does not happen. We relate our approach to policy distillation \cite{RossGB11} and dynamic oracles \cite{GoldbergN12}. By considering Yelp and SNLI benchmarks, we show that Levenstein VAE produces more informative latent representations than alternative approaches to preventing posterior collapse.
The Emergence of Compositional Languages for Numeric Concepts Through Iterated Learning in Neural Agents
Oct 11, 2019


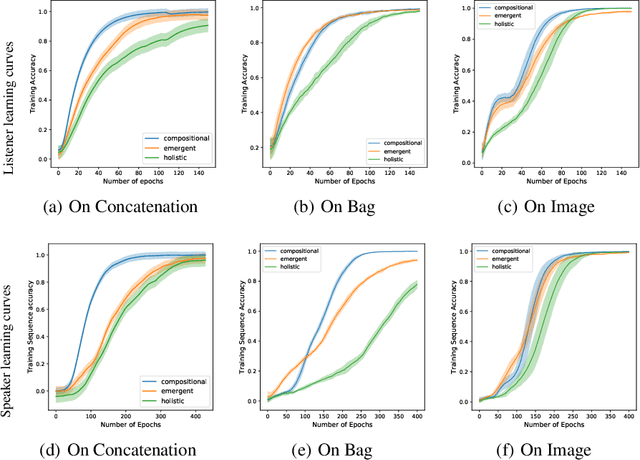
Since first introduced, computer simulation has been an increasingly important tool in evolutionary linguistics. Recently, with the development of deep learning techniques, research in grounded language learning has also started to focus on facilitating the emergence of compositional languages without pre-defined elementary linguistic knowledge. In this work, we explore the emergence of compositional languages for numeric concepts in multi-agent communication systems. We demonstrate that compositional language for encoding numeric concepts can emerge through iterated learning in populations of deep neural network agents. However, language properties greatly depend on the input representations given to agents. We found that compositional languages only emerge if they require less iterations to be fully learnt than other non-degenerate languages for agents on a given input representation.
Obfuscation for Privacy-preserving Syntactic Parsing
Apr 21, 2019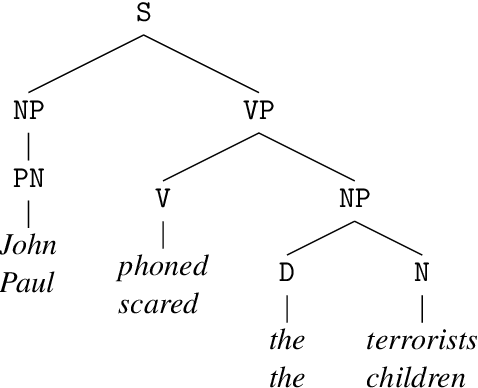
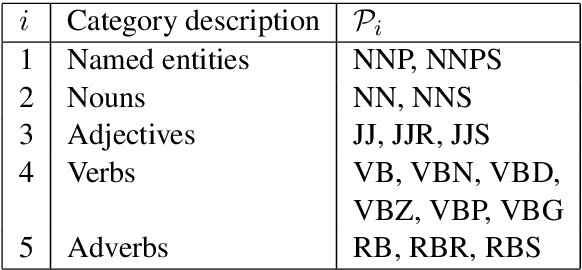
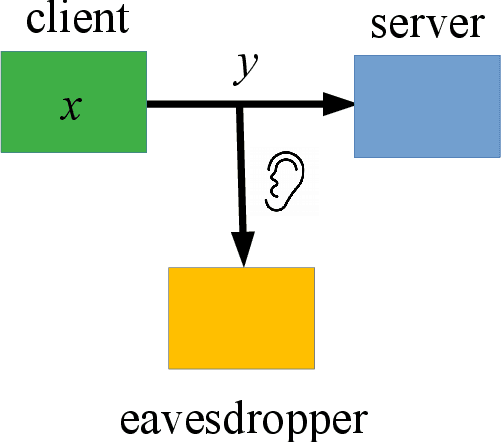
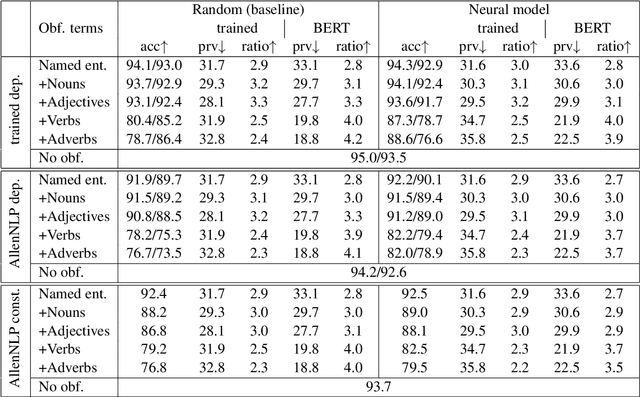
The goal of homomorphic encryption is to encrypt data such that another party can operate on it without being explicitly exposed to the content of the original data. We introduce an idea for a privacy-preserving transformation on natural language data, inspired by homomorphic encryption. Our primary tool is {\em obfuscation}, relying on the properties of natural language. Specifically, a given text is obfuscated using a neural model that aims to preserve the syntactic relationships of the original sentence so that the obfuscated sentence can be parsed instead of the original one. The model works at the word level, and learns to obfuscate each word separately by changing it into a new word that has a similar syntactic role. The text encrypted by our model leads to better performance on three syntactic parsers (two dependency and one constituency parsers) in comparison to a strong random baseline. The substituted words have similar syntactic properties, but different semantic content, compared to the original words.
Cooperative Learning of Disjoint Syntax and Semantics
Feb 25, 2019



There has been considerable attention devoted to models that learn to jointly infer an expression's syntactic structure and its semantics. Yet, \citet{NangiaB18} has recently shown that the current best systems fail to learn the correct parsing strategy on mathematical expressions generated from a simple context-free grammar. In this work, we present a recursive model inspired by \newcite{ChoiYL18} that reaches near perfect accuracy on this task. Our model is composed of two separated modules for syntax and semantics. They are cooperatively trained with standard continuous and discrete optimization schemes. Our model does not require any linguistic structure for supervision and its recursive nature allows for out-of-domain generalization with little loss in performance. Additionally, our approach performs competitively on several natural language tasks, such as Natural Language Inference or Sentiment Analysis.
Embedding Words as Distributions with a Bayesian Skip-gram Model
Jun 10, 2018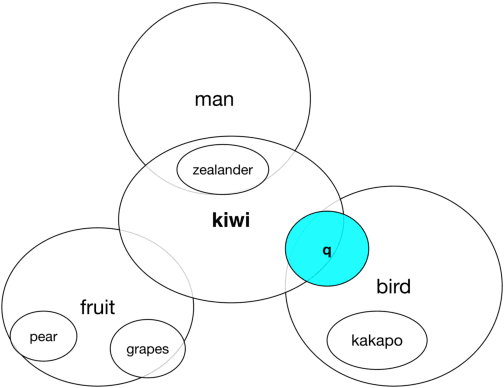
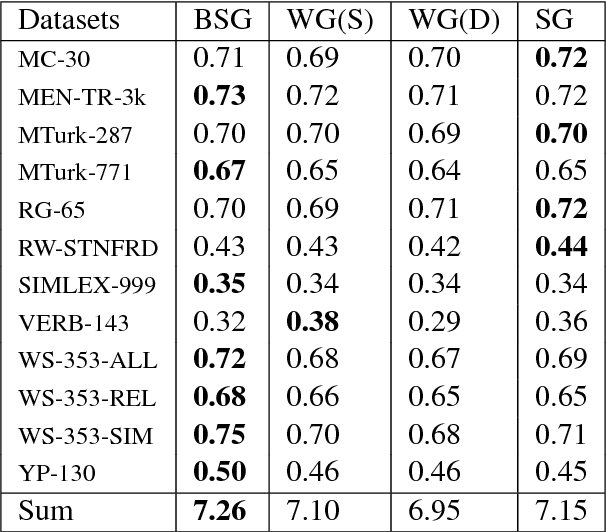
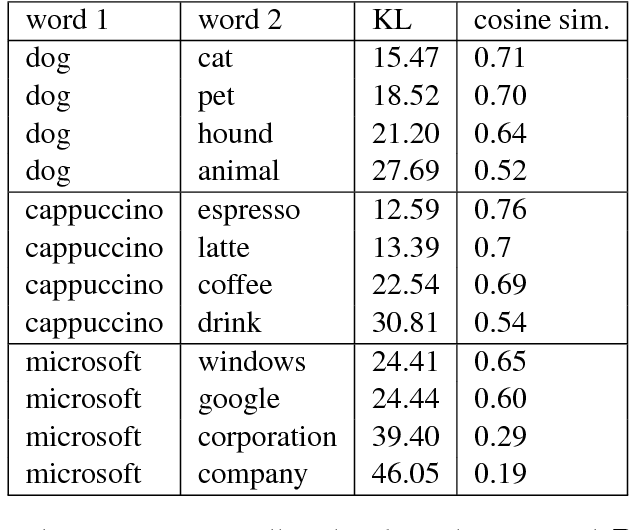
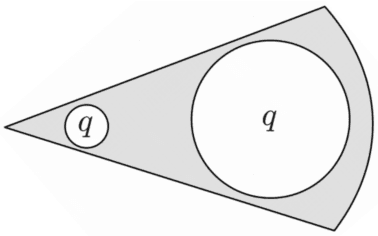
We introduce a method for embedding words as probability densities in a low-dimensional space. Rather than assuming that a word embedding is fixed across the entire text collection, as in standard word embedding methods, in our Bayesian model we generate it from a word-specific prior density for each occurrence of a given word. Intuitively, for each word, the prior density encodes the distribution of its potential 'meanings'. These prior densities are conceptually similar to Gaussian embeddings. Interestingly, unlike the Gaussian embeddings, we can also obtain context-specific densities: they encode uncertainty about the sense of a word given its context and correspond to posterior distributions within our model. The context-dependent densities have many potential applications: for example, we show that they can be directly used in the lexical substitution task. We describe an effective estimation method based on the variational autoencoding framework. We also demonstrate that our embeddings achieve competitive results on standard benchmarks.
Emergence of Language with Multi-agent Games: Learning to Communicate with Sequences of Symbols
Nov 04, 2017



Learning to communicate through interaction, rather than relying on explicit supervision, is often considered a prerequisite for developing a general AI. We study a setting where two agents engage in playing a referential game and, from scratch, develop a communication protocol necessary to succeed in this game. Unlike previous work, we require that messages they exchange, both at train and test time, are in the form of a language (i.e. sequences of discrete symbols). We compare a reinforcement learning approach and one using a differentiable relaxation (straight-through Gumbel-softmax estimator) and observe that the latter is much faster to converge and it results in more effective protocols. Interestingly, we also observe that the protocol we induce by optimizing the communication success exhibits a degree of compositionality and variability (i.e. the same information can be phrased in different ways), both properties characteristic of natural languages. As the ultimate goal is to ensure that communication is accomplished in natural language, we also perform experiments where we inject prior information about natural language into our model and study properties of the resulting protocol.