 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Posterior Collapse with Levenshtein Variational Autoencoder
Paper and Code
Apr 30, 2020
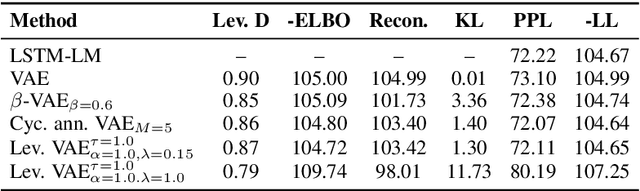
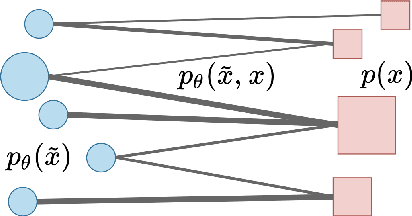

Variational autoencoders (VAEs) are a standard framework for inducing latent variable models that have been shown effective in learning text representations as well as in text generation. The key challenge with using VAEs is the {\it posterior collapse} problem: learning tends to converge to trivial solutions where the generators ignore latent variables. In our Levenstein VAE, we propose to replace the evidence lower bound (ELBO) with a new objective which is simple to optimize and prevents posterior collapse. Intuitively, it corresponds to generating a sequence from the autoencoder and encouraging the model to predict an optimal continuation according to the Levenshtein distance (LD) with the reference sentence at each time step in the generated sequence. We motivate the method from the probabilistic perspective by showing that it is closely related to optimizing a bound on the intractable Kullback-Leibler divergence of an LD-based kernel density estimator from the model distribution. With this objective, any generator disregarding latent variables will incur large penalties and hence posterior collapse does not happen. We relate our approach to policy distillation \cite{RossGB11} and dynamic oracles \cite{GoldbergN12}. By considering Yelp and SNLI benchmarks, we show that Levenstein VAE produces more informative latent representations than alternative approaches to preventing posterior collapse.