 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHASOR: Phase-Anchored Universal Action Representations for Humanoid Embodiments
Jun 01, 2026Learning a good action embedding space is fundamental to scalable robot policy learning, yet existing methods treat action latents as task-specific intermediates rather than first-class representations. The resulting latents are unstructured, embodiment-specific, and weakly tied to motion semantics, limiting interpretability, controllability, and transferability across robots. We position the action embedding space itself as a first-class design target, with downstream policy quality emerging from representation quality. Exploiting motion's intrinsic periodicity, we factorize it into a phase manifold that captures cyclic structure via FFT-parametric coefficients, together with a pose branch that conditions the manifold on non-periodic configuration detail. Combined with motion-semantic distillation, this factorized structure yields a cross-embodiment motion manifold that is interpretable and embodiment-agnostic by design. Anchoring multiple humanoid robots to a shared human-pretrained manifold then produces a unified action embedding space across diverse platforms, achieving strong cross-embodiment retrieval and consistent gains on downstream robot tasks.
EgoExo-Con: Exploring View-Invariant Video Temporal Understanding
Oct 30, 2025Can Video-LLMs achieve consistent temporal understanding when videos capture the same event from different viewpoints? To study this, we introduce EgoExo-Con (Consistency), a benchmark of comprehensively synchronized egocentric and exocentric video pairs with human-refined queries in natural language. EgoExo-Con emphasizes two temporal understanding tasks: Temporal Verification and Temporal Grounding. It evaluates not only correctness but consistency across viewpoints. Our analysis reveals two critical limitations of existing Video-LLMs: (1) models often fail to maintain consistency, with results far worse than their single-view performances. (2) When naively finetuned with synchronized videos of both viewpoints, the models show improved consistency but often underperform those trained on a single view. For improvements, we propose View-GRPO, a novel reinforcement learning framework that effectively strengthens view-specific temporal reasoning while encouraging consistent comprehension across viewpoints. Our method demonstrates its superiority over naive SFT and GRPO, especially for improving cross-view consistency. All resources will be made publicly available.
CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision
Nov 01, 2024

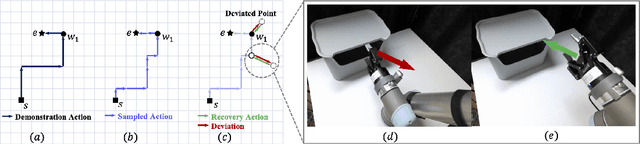
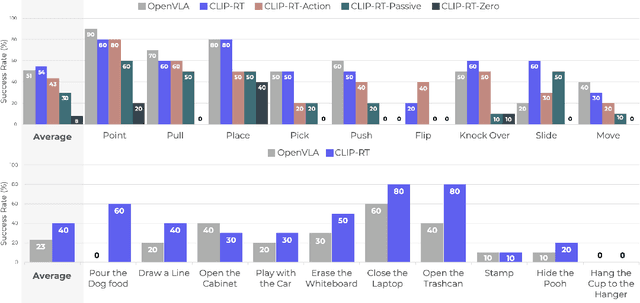
This paper explores how non-experts can teach robots desired skills in their environments. We argue that natural language is an intuitive and accessible interface for robot learning. To this end, we investigate two key aspects: (1) how non-experts collect robotic data using natural language supervision and (2) how pre-trained vision-language models learn end-to-end policies directly from this supervision. We propose a data collection framework that collects robot demonstrations based on natural language supervision (e.g., "move forward") and further augments these demonstrations. Next, we introduce a model that learns language-conditioned policies from natural language supervision called CLIP-RT. Our model employs pre-trained CLIP models and learns to predict actions represented in language via contrastive imitation learning. We first train CLIP-RT on large-scale robotic data and then enable it to learn desired skills using data collected from our framework. CLIP-RT shows strong capabilities in acquiring novel manipulation skills, outperforming the state-of-the-art model, OpenVLA (7B parameters), by 17% in average success rates, while using 7x fewer parameters (1B).
Socratic Planner: Inquiry-Based Zero-Shot Planning for Embodied Instruction Following
Apr 21, 2024



Embodied Instruction Following (EIF) is the task of executing natural language instructions by navigating and interacting with objects in 3D environments. One of the primary challenges in EIF is compositional task planning, which is often addressed with supervised or in-context learning with labeled data. To this end, we introduce the Socratic Planner, the first zero-shot planning method that infers without the need for any training data. Socratic Planner first decomposes the instructions into substructural information of the task through self-questioning and answering, translating it into a high-level plan, i.e., a sequence of subgoals. Subgoals are executed sequentially, with our visually grounded re-planning mechanism adjusting plans dynamically through a dense visual feedback. We also introduce an evaluation metric of high-level plans, RelaxedHLP, for a more comprehensive evaluation. Experiments demonstrate the effectiveness of the Socratic Planner, achieving competitive performance on both zero-shot and few-shot task planning in the ALFRED benchmark, particularly excelling in tasks requiring higher-dimensional inference. Additionally, a precise adjustments in the plan were achieved by incorporating environmental visual information.
PGA: Personalizing Grasping Agents with Single Human-Robot Interaction
Oct 19, 2023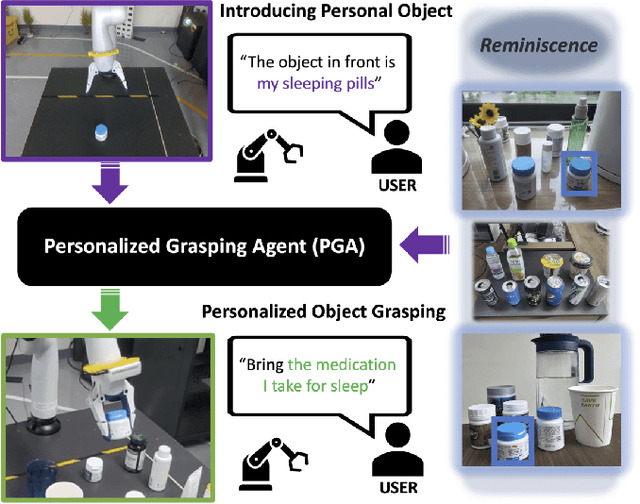
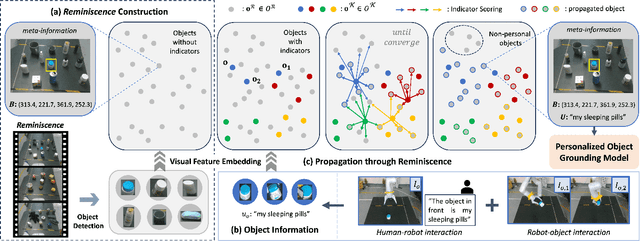
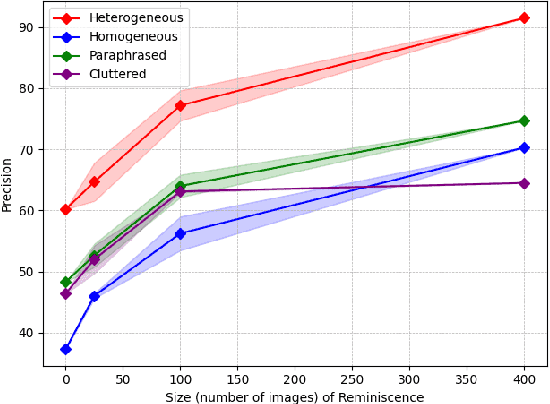
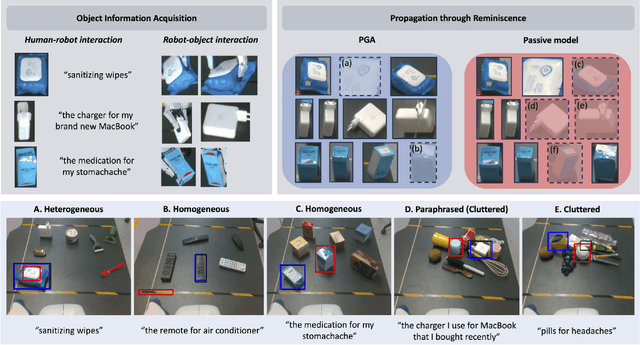
Language-Conditioned Robotic Grasping (LCRG) aims to develop robots that ground and grasp objects based on natural language instructions. While robots capable of recognizing personal objects like "my wallet" can interact more naturally with non-expert users, current LCRG systems primarily limit robots to understanding only generic expressions. To this end, we introduce a task scenario GraspMine with a novel dataset that aims to locate and grasp personal objects given personal indicators via learning from a single human-robot interaction. To address GraspMine, we propose Personalized Grasping Agent (PGA), that learns personal objects by propagating user-given information through a Reminiscence-a collection of raw images from the user's environment. Specifically, PGA acquires personal object information by a user presenting a personal object with its associated indicator, followed by PGA inspecting the object by rotating it. Based on the acquired information, PGA pseudo-labels objects in the Reminiscence by our proposed label propagation algorithm. Harnessing the information acquired from the interactions and the pseudo-labeled objects in the Reminiscence, PGA adapts the object grounding model to grasp personal objects. Experiments on GraspMine show that PGA significantly outperforms baseline methods both in offline and online settings, signifying its effectiveness and personalization applicability on real-world scenarios. Finally, qualitative analysis shows the effectiveness of PGA through a detailed investigation of results in each phase.
PROGrasp: Pragmatic Human-Robot Communication for Object Grasping
Sep 14, 2023



Interactive Object Grasping (IOG) is the task of identifying and grasping the desired object via human-robot natural language interaction. Current IOG systems assume that a human user initially specifies the target object's category (e.g., bottle). Inspired by pragmatics, where humans often convey their intentions by relying on context to achieve goals, we introduce a new IOG task, Pragmatic-IOG, and the corresponding dataset, Intention-oriented Multi-modal Dialogue (IM-Dial). In our proposed task scenario, an intention-oriented utterance (e.g., "I am thirsty") is initially given to the robot. The robot should then identify the target object by interacting with a human user. Based on the task setup, we propose a new robotic system that can interpret the user's intention and pick up the target object, Pragmatic Object Grasping (PROGrasp). PROGrasp performs Pragmatic-IOG by incorporating modules for visual grounding, question asking, object grasping, and most importantly, answer interpretation for pragmatic inference. Experimental results show that PROGrasp is effective in offline (i.e., target object discovery) and online (i.e., IOG with a physical robot arm) settings.
GVCCI: Lifelong Learning of Visual Grounding for Language-Guided Robotic Manipulation
Jul 12, 2023



Language-Guided Robotic Manipulation (LGRM) is a challenging task as it requires a robot to understand human instructions to manipulate everyday objects. Recent approaches in LGRM rely on pre-trained Visual Grounding (VG) models to detect objects without adapting to manipulation environments. This results in a performance drop due to a substantial domain gap between the pre-training and real-world data. A straightforward solution is to collect additional training data, but the cost of human-annotation is extortionate. In this paper, we propose Grounding Vision to Ceaselessly Created Instructions (GVCCI), a lifelong learning framework for LGRM, which continuously learns VG without human supervision. GVCCI iteratively generates synthetic instruction via object detection and trains the VG model with the generated data. We validate our framework in offline and online settings across diverse environments on different VG models. Experimental results show that accumulating synthetic data from GVCCI leads to a steady improvement in VG by up to 56.7% and improves resultant LGRM by up to 29.4%. Furthermore, the qualitative analysis shows that the unadapted VG model often fails to find correct objects due to a strong bias learned from the pre-training data. Finally, we introduce a novel VG dataset for LGRM, consisting of nearly 252k triplets of image-object-instruction from diverse manipulation environments.
Structured World Belief for Reinforcement Learning in POMDP
Jul 19, 2021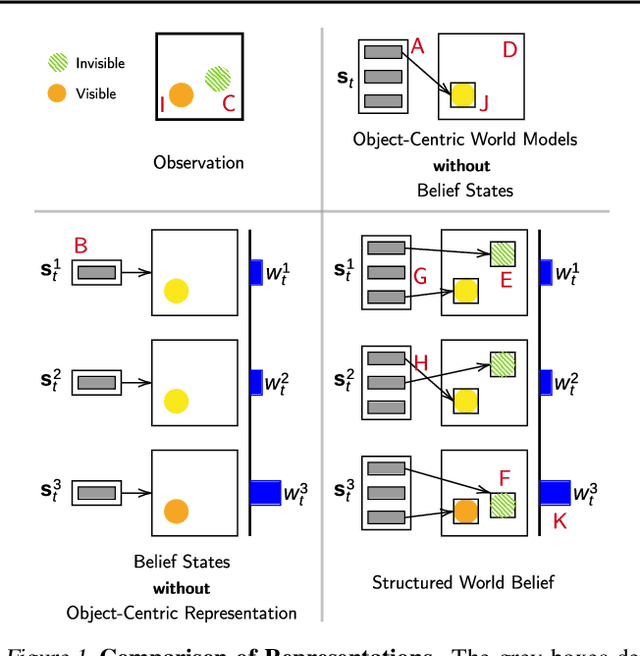
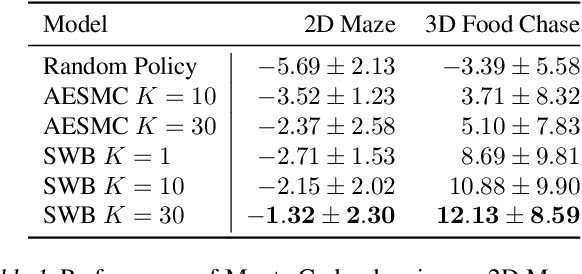
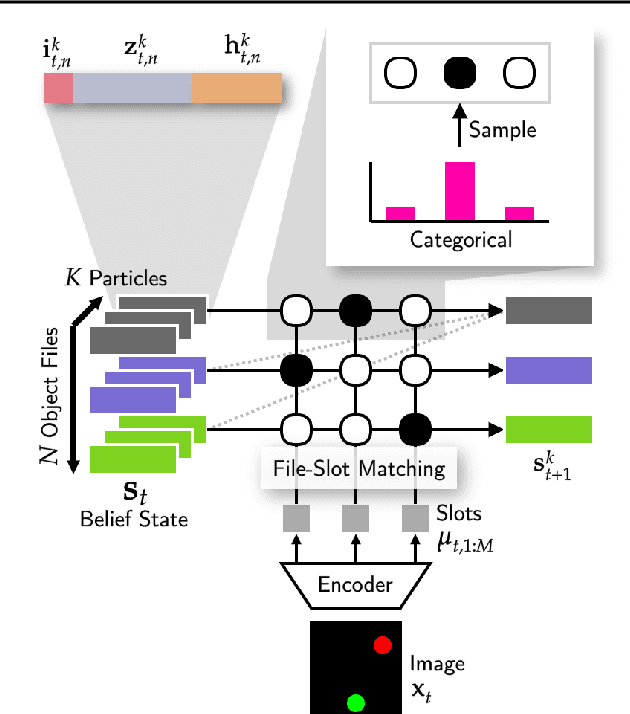

Object-centric world models provide structured representation of the scene and can be an important backbone in reinforcement learning and planning. However, existing approaches suffer in partially-observable environments due to the lack of belief states. In this paper, we propose Structured World Belief, a model for learning and inference of object-centric belief states. Inferred by Sequential Monte Carlo (SMC), our belief states provide multiple object-centric scene hypotheses. To synergize the benefits of SMC particles with object representations, we also propose a new object-centric dynamics model that considers the inductive bias of object permanence. This enables tracking of object states even when they are invisible for a long time. To further facilitate object tracking in this regime, we allow our model to attend flexibly to any spatial location in the image which was restricted in previous models. In experiments, we show that object-centric belief provides a more accurate and robust performance for filtering and generation. Furthermore, we show the efficacy of structured world belief in improving the performance of reinforcement learning, planning and supervised reasoning.